hue 集成spark+livy
一.先决条件
安装hue、hadoop。
二.spark on yarn 安装
1.添加环境变量 vim /etc/profile
SCALA_HOME=/opt/scala
SPARK_HOME=/opt/spark
2.配置spark; vim conf/spark-env.sh
#服务器域名 SPARK_LOCAL_IP=node7 #master 地址 SPARK_MASTER_HOST=node7 #master 端口 SPARK_MASTER_PORT=7077 #spark ui 端口 SPARK_MASTER_WEBUI_PORT=8080 #hadoop 配置目录 export HADOOP_CONF_DIR=/opt/hadoop-2.7.4/etc/hadoop/
3.配置spark ;vim conf/spark-defaults.conf
#spark 依赖的jar包 spark.yarn.jars=hdfs://node7:9010/user/sparkJars/jars/*
hdfs://node7:9010/user/sparkJars/jars/* 该路径的由来:
1. 找到spark程序目录的jars目录,如下图:

2.将该路径的jars包上传到hdfs的目录 (本例子中的hdfs路径是:/user/sparkJars/jars)
注:如果不配置该路径,那么每次提交spark 程序时就会上传jars包,这样会影响提交程序的效率,同时会占用hdfs的磁盘空间。
4.测试部署
使用spark-shell打开scala客户端。
./bin/spark-shell --master yarn --deploy-mode client
如果yarn 后台上面出现下图的记录,则表示部署成功。

三.安装livy
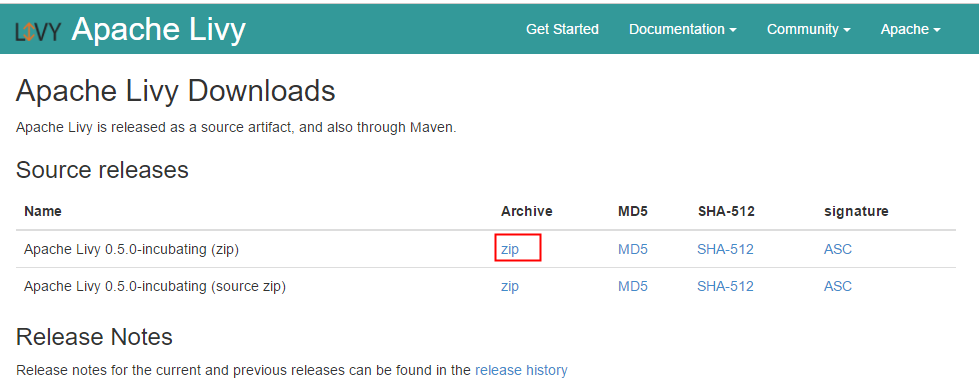
1. 下载livy 安装包
下载地址:http://livy.incubator.apache.org/download/
扫描二维码关注公众号,回复:
968521 查看本文章

2.设置环境变量
vim /etc/profile
#spark程序目录
export SPARK_HOME=/opt/spark #hadoop 配置目录 export HADOOP_CONF_DIR=/opt/hadoop-2.7.4/etc/hadoop/
再执行source profile命令,让环境变量生效
3.解压zip包
unzip livy-0.5.0-incubating-bin.zip
mv livy-0.5.0-incubating-bin.zip livy-0.5.0
4.配置livy
vi livy.conf
#livy服务端口 livy.server.port = 8998 #spark程序部署使用yarn集群 livy.spark.master = yarn #spark 程序使用客户端模式 livy.spark.deploy-mode =client
四.配置hue
1.配置hue.ini
vim hue.ini
[spark] # livy 服务器域名 livy_server_host=node8 # livy 服务器端口 ## livy_server_port=8998 # Configure Livy to start in local 'process' mode, or 'yarn' workers. livy_server_session_kind=yarn
五.验证配置是否正确
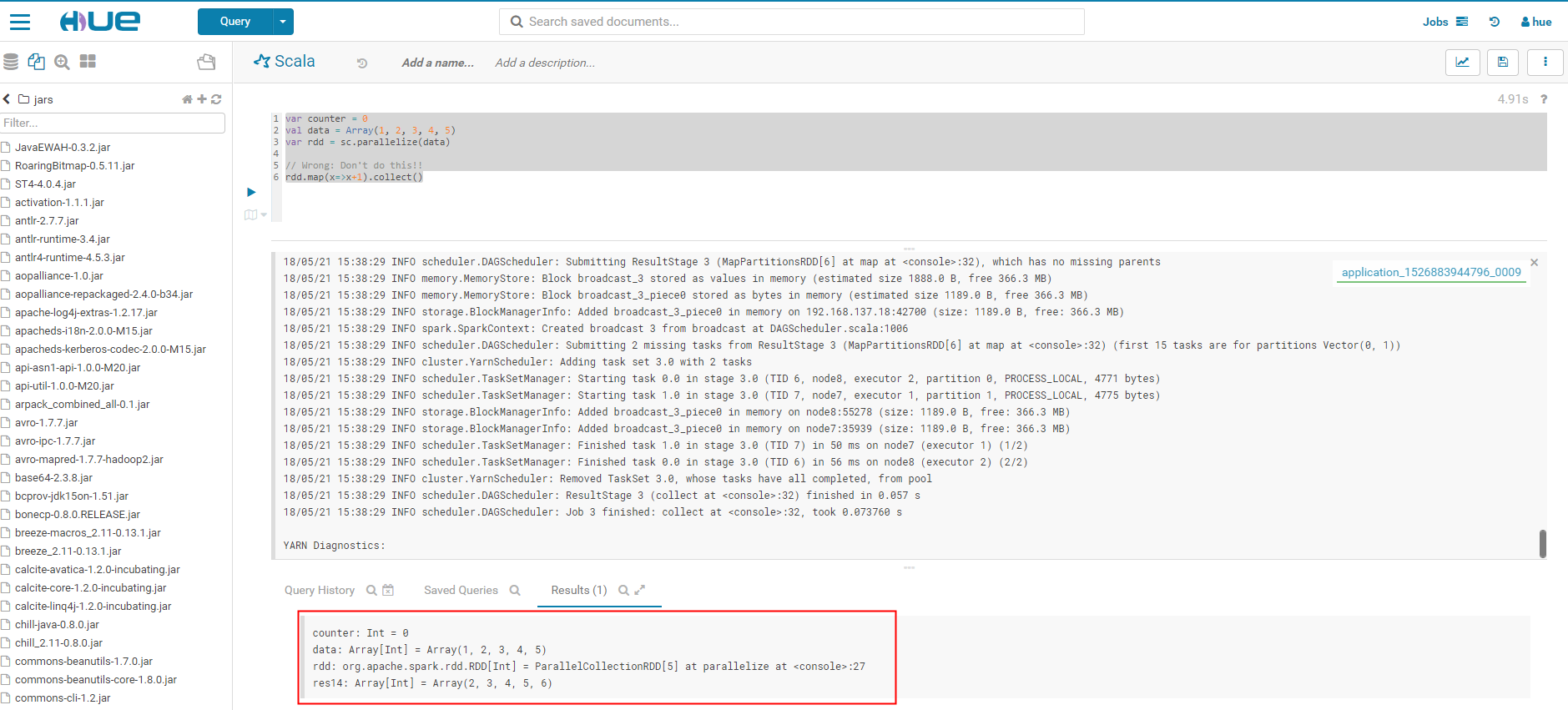
1.登录hue后台,打开scala编辑页,执行以下scala代码
var counter = 0 val data = Array(1, 2, 3, 4, 5) var rdd = sc.parallelize(data) // Wrong: Don't do this!! rdd.map(x=>x+1).collect()
出现如下结果,则证明集成成功。