第三章 SQL数据库开发--TSQL--select查询
3.1 select语法与逻辑处理顺序与谓词运算符优先级
3.1.1 select语法
SELECT [ ALL | DISTINCT ]
[TOP ( expression ) [PERCENT] [ WITH TIES ] ]
< select_list >
[ INTO new_table ]
[ FROM { <table_source> } [ ,...n ] ]
[ WHERE <search_condition> ]
[ <GROUP BY> ]
[ HAVING < search_condition > ]
[ORDER BY…]
3.1.2 select逻辑处理顺序
1 FROM
2 ON
3 JOIN
4 WHERE
5 GROUP BY
6 WITH CUBE 或 WITH ROLLUP
7 HAVING
8 SELECT
9 DISTINCT
10 ORDER BY
3.1.3 select谓词运算符优先级
谓词用于 WHERE 子句和 HAVING 子句的搜索条件中
级别 运算符
0 ()
1 ~(位非)
2 *(乘)、/(除)、%(取模)
3 +(正)、-(负)、+(加)、+(串联)、-(减)、&(位与)、^(位异或)、|(位或)
4 =、>、<、>=、<=、<>、!=、!>、!<(比较运算符)
5 NOT
6 AND
7 ALL、ANY、BETWEEN、IN、LIKE、OR、SOME
8 =(赋值)
3.2 TOP限制结果集与DISTINCT消除重复行
3.2.1 TOP限制结果集
TOP限制10输出
SELECT top 10 mid,transoccurtime FROM L05_EXIT_TRAN where transoccurtime>'2018-05-01' order by transoccurtime desc
TOP限制1%输出
SELECT top 1 PERCENT mid,transoccurtime FROM L05_EXIT_TRAN where transoccurtime>'2018-05-01' order by transoccurtime desc
3.2.2 DISTINCT消除重复行
set rowcount 100
SELECT distinct (shiftbegintime) FROM L05_EXIT_TRAN where transoccurtime>'2018-05-01' order by shiftbegintime desc
3.3 在选择列上使用常量,函数,别名
3.3.1 使用常量
SELECT user_name,'姓名' as 常量列 FROM A70_USERS_ZH
张春生 姓名
朱艳平 姓名
郅立强 姓名
王金华 姓名
3.3.2 使用函数
SELECT top 100 year(ac_when) FROM P01_TOD_INDEX;
3.3.3 别名
注意事项:定义了表别名以后,在语句中对该表的引用,都必须使用别名
SELECT top 20 l05.transoccurtime FROM L05_EXIT_TRAN as l05
SELECT top 20 l05.transoccurtime as 交易时间 FROM L05_EXIT_TRAN as l05
3.4 使用where筛选
3.4.1 使用谓词运算符过滤数据
交易时间大于2018-05-01,输出10行
SELECT top 10 * FROM L05_EXIT_TRAN where transoccurtime>'2018-05-01' order by shiftbegintime desc
交易时间大于2018-05-01,或者mid<0 输出10行
SELECT top 10 * FROM L05_EXIT_TRAN where transoccurtime>'2018-05-01' or mid<0 order by shiftbegintime
-43341886603952831 1899-12-30 00:00:00
-43341882293519868 1899-12-30 00:00:00
-43341882283112241 1899-12-30 00:00:00
Between ….and 中间的条件是包含。5月1日至5月10日
SELECT top 10 mid,shiftbegintime FROM L05_EXIT_TRAN where transoccurtime between '2018-05-01' and '2018-05-10' order by shiftbegintime desc
3.4.2 使用like进行模糊查询
| 通配符 |
含义 |
| % |
代表任意字符 |
| _下划线 |
代表单个字符 |
| [] |
指定范围如[a-e]a到e [a,f]a和f |
| [^] |
不包含字符 |
SELECT * FROM A70_USERS_ZH where user_name like '王[欢,磊]'
王磊
王欢
SELECT user_name FROM A70_USERS_ZH where user_name like '王[^欢,磊]'
王宇
王俊
王晨
SELECT * FROM A70_USERS_ZH where user_num like '1600[5-9]%'
16005001
16005002
16005003
16005004
16005005
3.4.3 如何使用null
当指定null条件的时候,使用is null 或者is not null
SELECT * FROM A72_ROLES_DOWN where role_com is not null
0 11 分中心稽查员 稽查帐务 2 0
0 13 9092 9092 2 0
3.5 子查询与嵌套查询
3.5.1 子查询与嵌套查询定义与语法
子查询是一个嵌套在它可以使一个 SELECT、SELECT...INTO 语句、INSERT语句、DELETE 语句、 UPDATE 语句或其他子查询中的查询。子查询嵌套在查询内部,且必须始终出现在圆括号内。
Select * (子查询T2) from T1 where 查询表达式 in或者 exists子查询。
where 查询表达式 比较运算符ANY|ALL(子查询)
嵌套查询又称子查询,是指在父查询的where条件语句中再插入一个子查询语句,连接查询都可以用子查询完成,反之不然。在SQL语言中,一个 SELECT-FROM-WHERE 语句称为一个查询块。将一个查询块嵌套在另一个查询块的 WHERE 子句或 HAVING 短语的条件中的查询称为 嵌套查询
3.5.2 子查询与嵌套查询事例
3.5.2.1 子查询在select后
SELECT table_id,count(*) 下发数量,(SELECT count(*) FROM A37_Lane_Info) 收费节点数 FROM PARAM_SEND_LANE where version=1811040000220717 and sfrom=0 group by table_id;
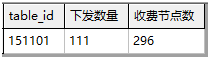
3.5.2.2 子查询在where后
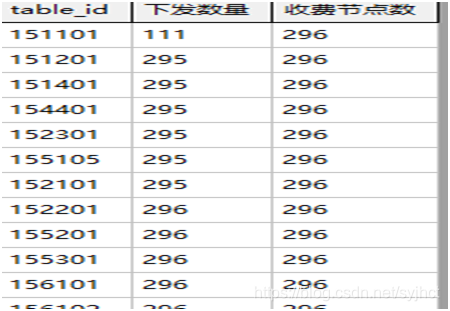
SELECT table_id,count(*) 下发数量,(SELECT count(*) FROM A37_Lane_Info) 收费节点数 FROM PARAM_SEND_LANE where version in (
SELECT version_id FROM A93_VERSION_STATE_ZH where table_id>150000 and state=5 and increment=0) and sfrom=0 group by table_id order by 下发数量 ;
3.5.3 EXISTS关键字与IN
语法 EXISTS表达式 subquery子查询 如果子查询包含任何行,则返回 TRUE。
EXISTS是可接受一个查询作为输入,如果子查询返回任意行,TRUE,否则为FALSE。
IN 确定给定的值是否与子查询或列表中的值相匹配。in在查询的时候,首先查询子查询的表,然后将内表值和外表做一个笛卡尔积,然后按照条件进行筛选。所以相对内表比较小的时候,in的速度较快。
EXISTS 指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。匹配上就将结果放入结果集中。
in 和 exists的区别: 如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in, 反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。其实我们区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询。
In 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。一直以来认为exists比in效率高的说法是不准确的。
SELECT TOP 1000 * FROM L05_EXIT_TRAN where transoccurtime>'2017-11-01' and transoccurtime<'2017-11-28' and operatorid in (SELECT user_id FROM A70_USERS_ZH where user_num= 15001924 )耗时11秒

SELECT TOP 1000 * FROM L05_EXIT_TRAN l05 where l05.transoccurtime>'2017-11-01' and l05.transoccurtime<'2017-11-28' and EXISTS (SELECT a70.user_id FROM A70_USERS_ZH a70 where a70.user_num=15001924 and a70.user_id=l05.operatorID )
耗时2分钟

3.5.4 对于ALL,SOME,ANY的理解
| 运算符 |
含义 |
| ALL |
如果一组的比较都为 TRUE,那么就为 TRUE。 |
| SOME |
如果在一组比较中,有些为 TRUE,那么就为 TRUE。 |
| ANY |
如果一组的比较中任何一个为 TRUE,那么就为 TRUE。 |
ALL 比较标量值和单列集中的值
语法 scalar_expression表达式 { = | <> | != | > | >= | !> | < | <= | !< } ALL ( subquery子查询 )
SOME | ANY (Transact-SQL) 比较标量值和单列集中的值。 SOME 和 ANY 是等效的。
语法 scalar_expression 表达式{ = | < > | ! = | > | > = | ! > | < | < = | ! < }
{ SOME | ANY } ( subquery子查询 )
SELECT * FROM A70_USERS_ZH where user_id > all (select user_id from A74_USER_ROLE where role_id>3) USER_id大于最大值
TI 表有ID1,2,3,4
以下查询返回 TRUE,因为 3 小于表中的某些值。
复制
IF 3 < SOME (SELECT ID FROM T1)
PRINT 'TRUE'
ELSE
PRINT 'FALSE' ;
以下查询返回 FALSE,因为 3 并不小于表中的所有值。
复制
IF 3 < ALL (SELECT ID FROM T1)
PRINT 'TRUE'
ELSE
PRINT 'FALSE' ;
3.6 order by对结果排序
对于null排序处理,是无穷小。Order by默认升序ASC不用写,如果使用降序使用DESC。
单列排序
SELECT attach_id,user_name FROM A70_USERS_ZH order by attach_id
多列排序
SELECT attach_id,user_num,user_name FROM A70_USERS_ZH order by attach_id desc,user_num
1001136 7001003 郑彤染
1001136 7001004 杨学培
1001136 7001007 张天杰
1001136 7001008 何敏
1001136 7001009 黄丽强
1001136 7001012 郑健
3.7 使用GROUP BY 子句和聚集函数进行分组
3.7.1 GROUP BY使用基础
聚集函数
AVG() 返回某列的平均值
COUNT()返回某列的行数
MAX() 返回某列的最大值
MIN() 返回某列的最小值
SUM()返回某列值之和
查询7月以后,出口广场的车流量
SELECT a36.organ_name as 广场,count(*) as 车流量 FROM L05_EXIT_TRAN as l05,A36_ORGAN as a36 where l05.transoccurtime>'2018-07-01' and l05.plaza_id=a36.organ_id group by a36.organ_name order by 车流量 desc
西红门主站进京出 3751926
榆垡南出京出 1660982
金华寺站出京出 667890
庞各庄站出京出 625676
西红门南桥进京出2 579101
海子角站进京出 546598
天宫院站出京出 531863
3.7.2 HAVING子句筛选分组后的数据
Having与where子句功能相同,都是对数据进行筛选,不同的是,where是对分组之前的数据筛选,having是对分组后的数据筛选,having可以使用聚合函数或者其他表达式,where 子句不能。进行先使用where子句,where子句性能好
查询7月以后,出口广场的车流量大于6万的广场
SELECT a36.organ_name as 广场,count(*) as 车流量 FROM L05_EXIT_TRAN as l05,A36_ORGAN as a36 where l05.transoccurtime>'2018-07-01' and l05.plaza_id=a36.organ_id group by a36.organ_name having count(*)>600000 order by 车流量 desc
西红门主站进京出 3751926
榆垡南出京出 1660982
金华寺站出京出 667890
庞各庄站出京出 625676
3.7.3 Where 和having比较
Where 筛选good
SELECT a36.organ_name as 广场,count(*) as 车流量 FROM L05_EXIT_TRAN as l05,A36_ORGAN as a36 where l05.transoccurtime>'2018-07-01' and l05.plaza_id>100100 and l05.plaza_id=a36.organ_id group by a36.organ_name order by 车流量 desc
Having 筛选bad
SELECT l05.plaza_id as 广场,count(*) as 车流量 FROM L05_EXIT_TRAN as l05,A36_ORGAN as a36 where l05.transoccurtime>'2018-07-01' and l05.plaza_id=a36.organ_id group by l05.plaza_id having l05.plaza_id>100100 order by 车流量 desc
Where 子句过滤后,然后对更少的数据分组,第二个是分组后,过滤。当然是where子句性能好。
3.7.4 NO-GROUP BY ROLLUP与CUBE 没有弄明白
3.8 COMPUTE (Transact-SQL) 以后会舍弃不用
生成合计作为附加的汇总列出现在结果集的最后。当与 BY 一起使用时,COMPUTE 子句在结果集内生成控制中断和小计。可在同一查询内指定 COMPUTE BY 和 COMPUTE。
语法
[ COMPUTE
{ { AVG | COUNT | MAX | MIN | STDEV | STDEVP | VAR | VARP | SUM }
( expression ) } [ ,...n ]
[ BY expression [ ,...n ] ]
]
| 行聚合函数 |
结果 |
| AVG |
数值表达式中所有值的平均值 |
| COUNT |
选定的行数 |
| MAX |
表达式中的最高值 |
| MIN |
表达式中的最低值 |
| STDEV |
表达式中所有值的标准偏差 |
| STDEVP |
表达式中所有值的总体标准偏差 |
| SUM |
数值表达式中所有值的和 |
| VAR |
表达式中所有值的方差 |
| VARP |
表达式中所有值的总体方差 |
|
|
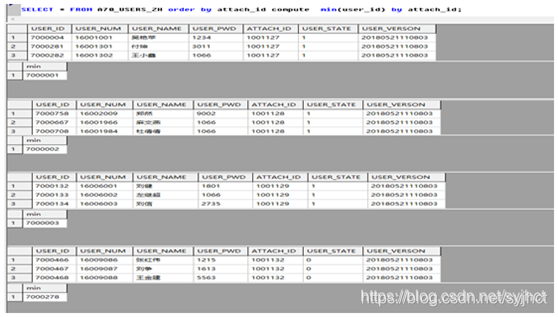
SELECT * FROM A70_USERS_ZH order by attach_id compute min(user_id);;

SELECT * FROM A70_USERS_ZH order by attach_id compute min(user_id) by attach_id;
3.10 SQL性能优化
3.10.1 尽量使用正逻辑而不是非逻辑,非逻辑操作(no between 、 not in 和not null)可能会降低查询速度,因为它要检索数据表中的所有行;
3.10.2 如果能够使用一个更确定的查询,就尽量避免使用关键字LIKE,使用LIKE查询,数据查询速度可能会降低;
3.10.3 只要有可能,尽量在搜索条件中使用精确的比较或值的域;
3.10.4使用Order by 子句可能会降低数据查询速度,
