问题描述:给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。如果needel字符串为空,则返回0。

思路:这题是一道经典的字符串匹配问题。最开始的思路是直接用python中自带的find函数,后来也做出了切片法以及暴力破解算法。但字符串匹配问题最经典的算法还是KMP算法,但KMP算法当时学的时候就没太弄明白,于是又花了不少时间终于想清楚了,这里的LMP算法参考了https://www.zhihu.com/question/21923021/answer/281346746这位大佬的讲解。
思路一:没有使用到算法的几个方法
#使用find函数 class Solution: def strStr(self, haystack: str, needle: str) -> int: if str == '': return 0 return haystack.find(needle) #使用切片 class Solution: def strStr(self, haystack: str, needle: str) -> int: for i in range(0,len(haystack)-len(needle)+1): if haystack[i:i+len(needle)] == needle: return i return -1 #暴力破解 class Solution: def strStr(self, haystack: str, needle: str) -> int: if needle == '': return 0 i,j = 0,0 length1,length2 = len(haystack),len(needle) while(j < length2 and i < length1): if haystack[i] == needle[j]: i += 1 j += 1 elif haystack[i] != needle[j] and j == 0: i += 1 else: i = i-j+1 j = 0 if j == length2: return i-j else: return -1
思路二:KMP算法
kmp算法中有一个next数组,用来记录一个字符串的前缀和后缀最长公共部分的长度。为什么要记录这一长度呢?
当使用过暴力破解时,在不匹配的情况下会将j指针移动到模式串(即needle)的起始位置重新开始匹配。然而事实上,通过寻找出前缀和后缀最长公共部分的长度,就可以避免j指针的反复遍历。
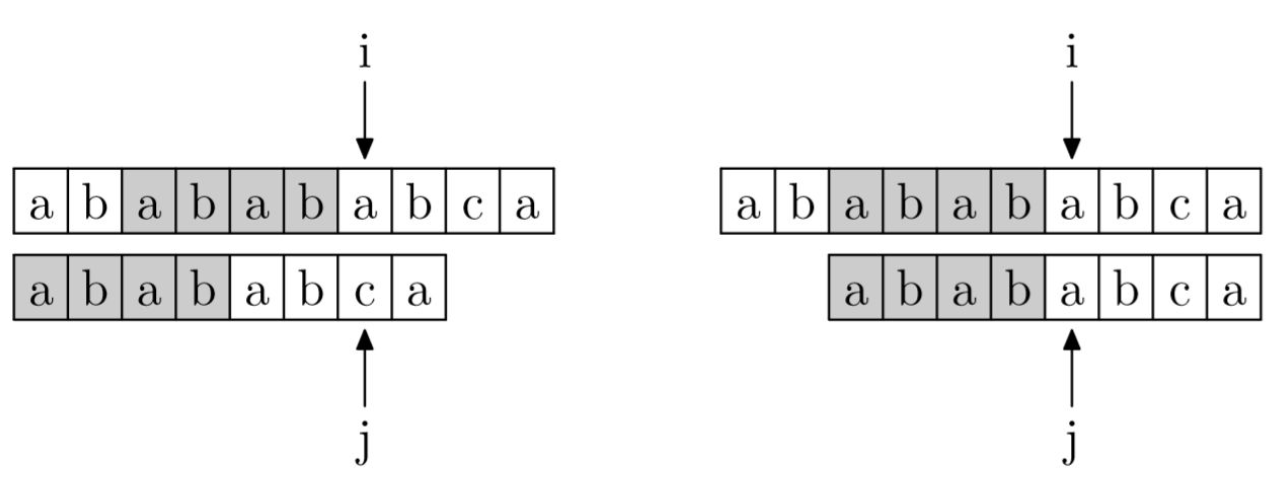
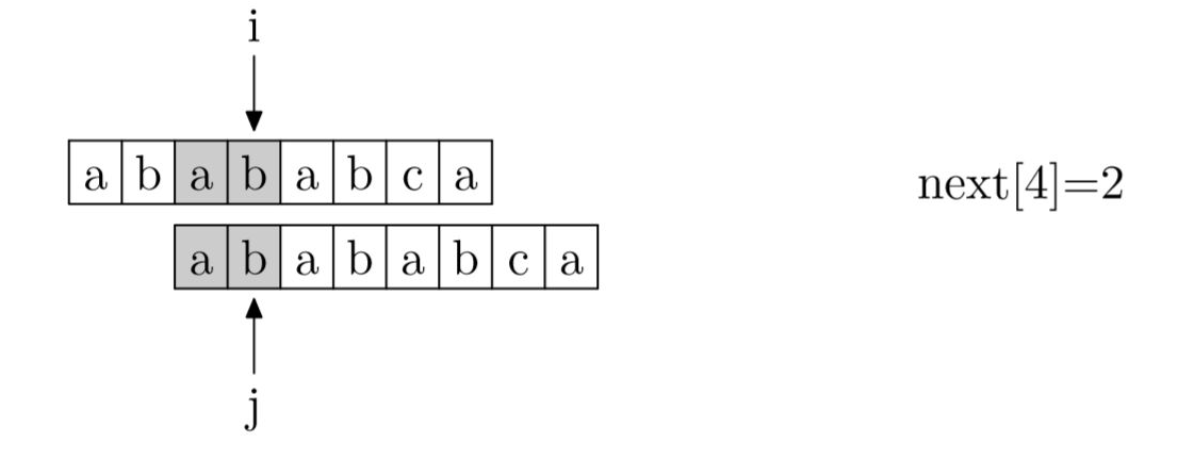
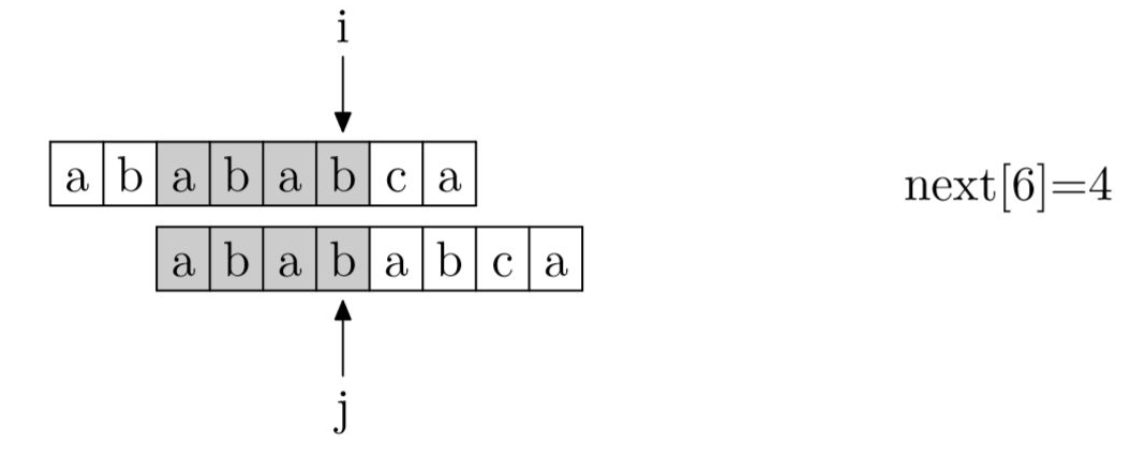
如左图:当j指针移动到c时出现了不匹配的情况,这说明j之前的字符串ababab是跟待匹配字符串完全匹配的,而ababab前缀和后缀最长公共部分的长度为4,也就是说前四位和后四位是一样的(即模式串的前四位跟待匹配字符串的后四位是一样的),因此不必将j指针移动到初始位置,而将其移动到已经匹配的后一位,即第5位即可。
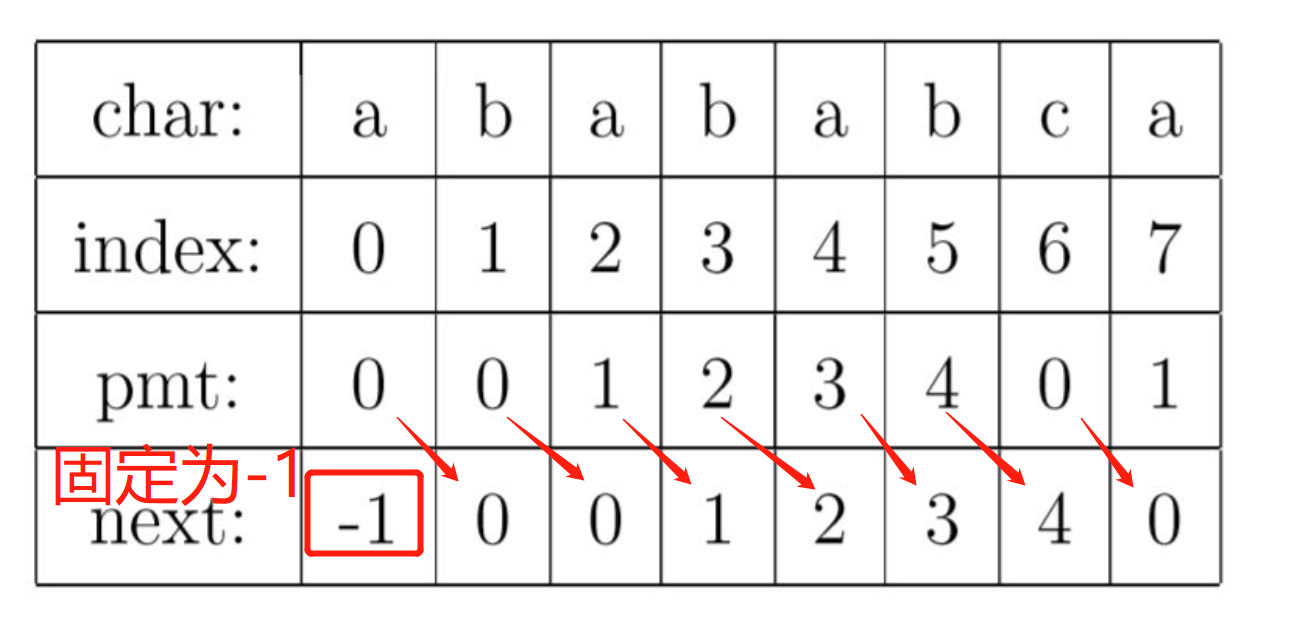
在这个步骤中我们还可以发现,当第j位不匹配时,我们需要用到的值是前j-1位字符串中前缀和后缀的最长公共长度。因此next数组要整体右移一位。具体的next数组如右图所示。
i指针是不会回溯的,通过next数组中记录的值我们就可以知道在不匹配的情况下应该将j指针移动到什么位置。代码如下图所示
def kmp(haystack,needle,nextstr): #i指针遍历haystack,j指针遍历needle i,j = 0,0 while i < len(s) and j < len(p): if j == -1 or s[i] == p[j]: i += 1 j += 1 else: j = nextstr[j] if j == len(p): return i-j else: return -1
那么接下来的问题就是如何构造next数组?
首先明确的一点是,规定next[0]=-1。接下来,可以把求解next数组的过程看作是一个字符匹配过程。其中i表示next数组中的位置,j表示下一次开始匹配时应该从哪个位置开始。
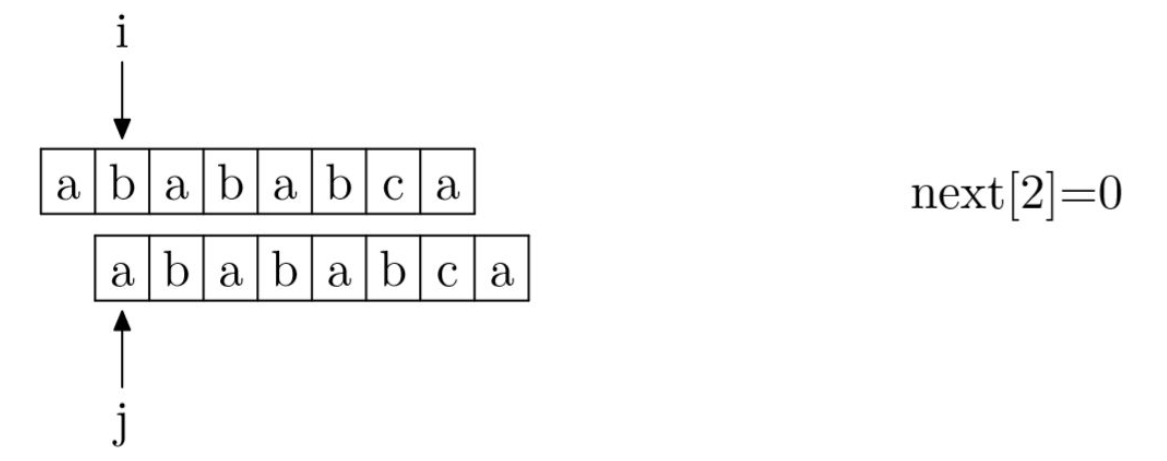
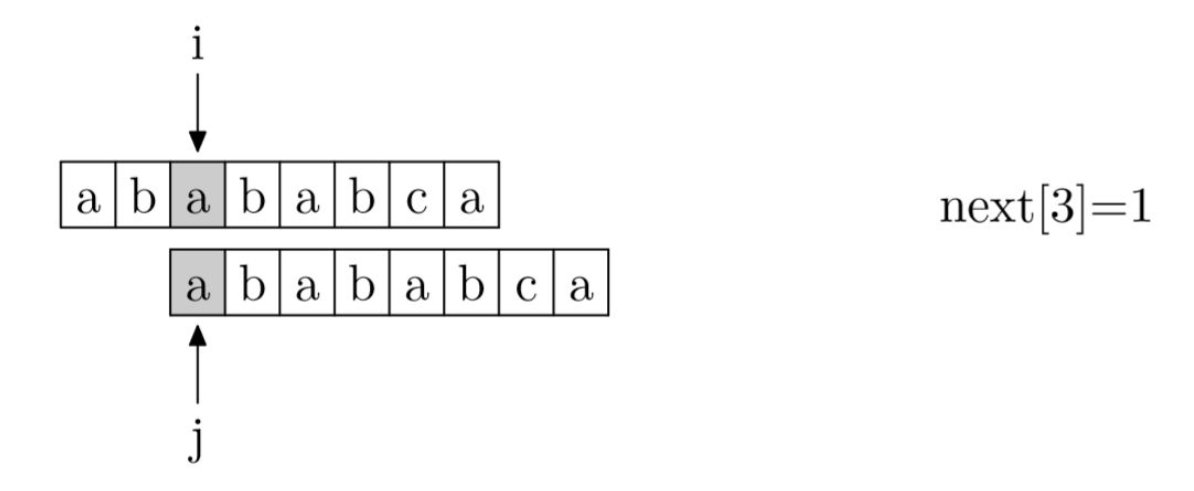
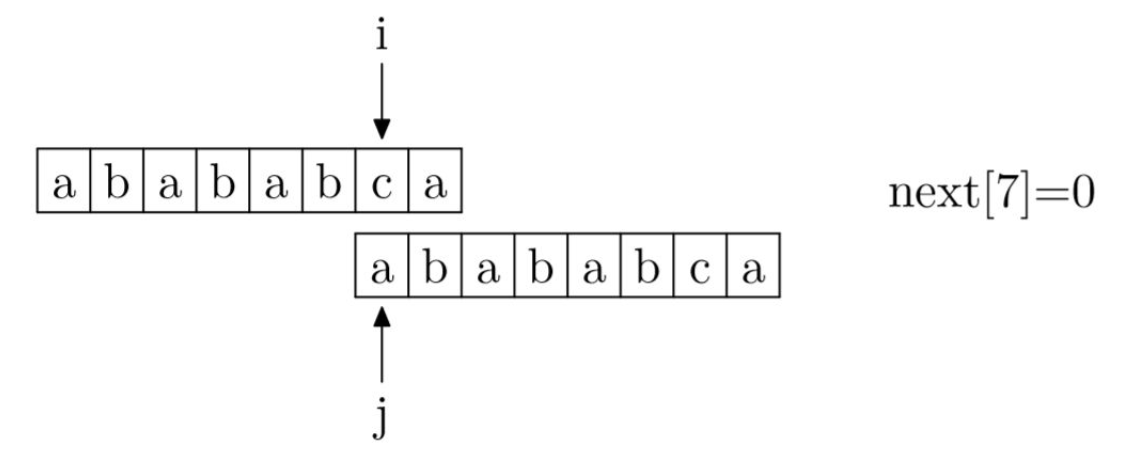
def getnext(needle): nextstr = [0] * (len(needle)) nextstr[0] = -1 i = 0 j = -1 while i < len(needle): if j == -1 or needle[i] == needle[j]: i += 1 j += 1 nextstr[j] = j else: j = nextstr[j] return nextstr