文章目录
Spark下载和安装
可以去Spark官网下载对应的spark版本。此处我选择了 spark-2.4.5-bin-hadoop2.6.tgz。注意该spark版本是2.4.5,与hadoop2.6相匹配,用的scala 2.11版本编译的spark源码。
如果觉得官网比较慢,可以去中国科学技术大学镜像网站和清华大学镜像网站下载。

将spark-2.4.5-bin-hadoop2.6.tgz上传到Linux服务器/usr/local/src/packages目录并解压,建立软连接
cd /usr/local/src
tar zxPvf packages/spark-2.4.5-bin-hadoop2.6.tgz -C ./
ln -s spark-2.4.5-bin-hadoop2.6 spark
同时修改 /etc/profile 文件增加环境变量。修改文件后需要 source /etc/profile 生效
export SPARK_HOME=/usr/local/src/spark
export PATH=$PATH:$JAVA_HOME/bin:$SPARK_HOME/bin
Spark的部署模式
可以通过 spark-submit --help 查看能支持哪些模式,下图是截取的部分信息。
--master MASTER_URL 参数就是支持的模式,有 local[*]即本地模式、Spark Standalone模式(即spark框架自身自带的资源调度管理服务)、mesos模式、yarn模式、k8s模式。

本地模式验证最简单 ./bin/run-example SparkPi 100 --master local[2] 就能查看结果。
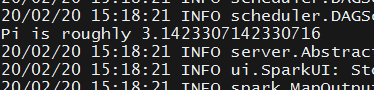
工作中用的最多的就是 spark on yarn 模式。其他模式用的较少我就不再这里描述。
spark on yarn
需要修改spark-env.sh文件,cp spark-env.sh.template spark-env.sh,在该文件添加如下内容,这样spark运行时就能找到hdfs集群和yarn集群。
HADOOP_HOME=/usr/local/src/hadoop
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
通过运行spark自带计算PI的例子来进行验证。
spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.11-2.4.5.jar 100
结果可去yarn集群的webui界面看到。

spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client examples/jars/spark-examples_2.11-2.4.5.jar 100
结果会在控制台上看到。

两个命令的区别只在于--deploy-mode的值是cluster还是client,具体什么区别后面详细介绍。
IDEA编写spark程序
可以用过 spark-submit --version 查看当前spark的版本及对应的scala编译版本。scala是2.11.12版本。

下载Scala
由于spark的源码是由scala编写的,故需要从scala官网下载对应2.11.12版本的scala。最后的小版本号可以不一样,但必须是 2.11.* 版本。下载 scala-2.11.12.msi windows的安装文件,安装scala很简单,此处不再赘述。
安装Scala插件
首先在IDEA的插件管理器上下载scala的插件,如下图我已经下载好插件。

然后点击 Project Structure -->Global Libraries 上面的加号,添加Scala SDK

下图就是我添加好的scala-sdk

建立Maven工程
新建 Maven工程,填写GroupId以及ArtifactId,然后一步步填写对应的工程名,然后点击Finish,这样就创建好了新的Maven工程。比较简单就不再这里贴图了。
需要在pom.xml文件添加spark的依赖,如下所示
特别需要注意的是 依赖里的scala版本必须要和服务器上spark对应的scala版本一致,否则会出现 java.lang.NoSuchMethodError: scala.Predef$.refArrayOps 找不到方法的错误。
spark的依赖可以从mvn仓库里找到。
<properties>
<!--解决maven打包时编码不对的问题-->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>2.4.5</spark.version>
<scala.version>2.11</scala.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
打开刚刚创建的Maven工程,在src/main目录下创建名为scala的directory,并将其标记为Resources Root。

编写wordcount程序
然后在scala目录下新建名为 com.utstar.patrick.spark.wc 的package,并在该package下新建scala文件,
New --> Scala Class,填写好Name后选择 Object
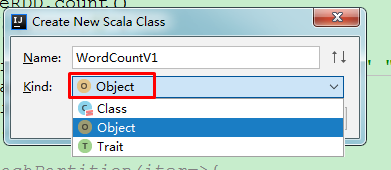
代码如下
package com.utstar.patrick.spark.wc
import java.util.concurrent.TimeUnit
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCountV1 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
sparkConf.setAppName("WordCountV1")
// 本地模式运行,如果是sparn on yarn就需要注释,否则会报错
// sparkConf.setMaster("local[4]")
val sparkContext = new SparkContext(sparkConf)
// val path = "D:\\cygwin64\\home\\Administrator\\words.txt"
val path = "/user/root/input/words.txt"
//从存储文件系统创建RDD, 并指定分区数是3
val fileRDD = sparkContext.textFile(path=path,minPartitions = 3)
//获取文件的总行数
val lines = fileRDD.count()
println(s"总共有${lines}行")
//单词统计
val wcMapRDD = fileRDD.flatMap(line=>line.split(" ")).map(word=>(word,1))
val wcRDD = wcMapRDD.reduceByKey(_+_)
// 打印
wcRDD.foreach(println)
// 采用collect()将数据收集到driver机上后再遍历打印
wcRDD.collect().foreach(println)
sparkContext.stop();
}
}
打成jar包
Project Structure --> Artifacts --> + --> JAR -->Empty

填写名字后将项目的编译文件双击就能将编译后的代码加入到jar包里了。


然后点击 Apply 即可。
再选择 Build --> Build Artifacts 即可完成jar包的打包。
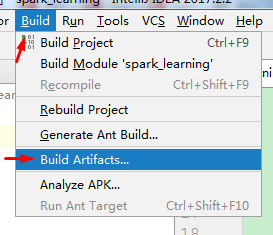
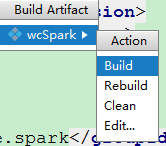
验证JAR包
将打包的jar包上传到服务器后运行命令
spark-submit --master yarn --deploy-mode cluster --class com.utstar.patrick.spark.wc.WordCountV1 /root/test/spark-learning/wcSpark.jar
在yarn的webui页面能查看结果

注意 wcRDD.foreach(println) 的打印信息在上面没有找到的,要去到该application对应的container里找(因为这是分布式计算任务,会到各个executor节点上打印),如下图

