BeautifulSoup4是爬虫必学的技能。BeautifulSoup最主要的功能是从网页抓取数据,Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐使用lxml 解析器。
爬取笑话大全:
冷笑话的页面:
1.寻找url规律:
http://xiaohua.zol.com.cn/lengxiaohua/1.html
http://xiaohua.zol.com.cn/lengxiaohua/2.html
http://xiaohua.zol.com.cn/lengxiaohua/3.html
可以看出url规律很简单,不过是从1到n迭代
2.Headers:
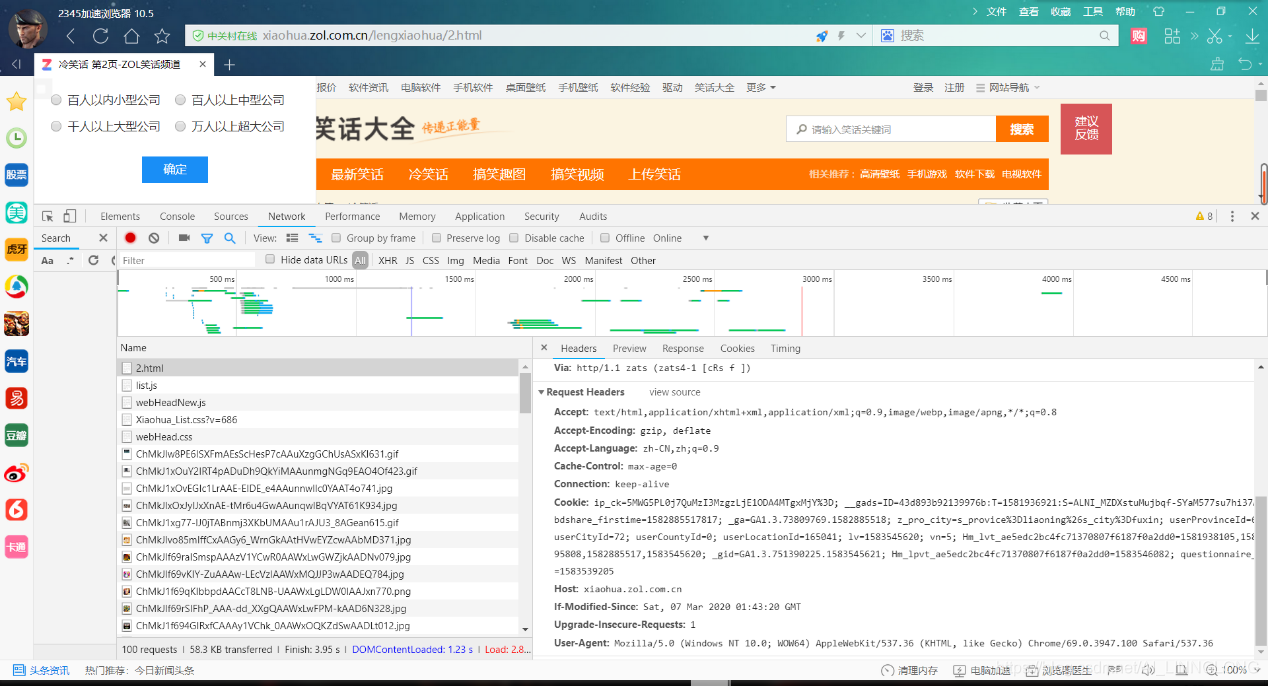
3.分析要求:
内容:
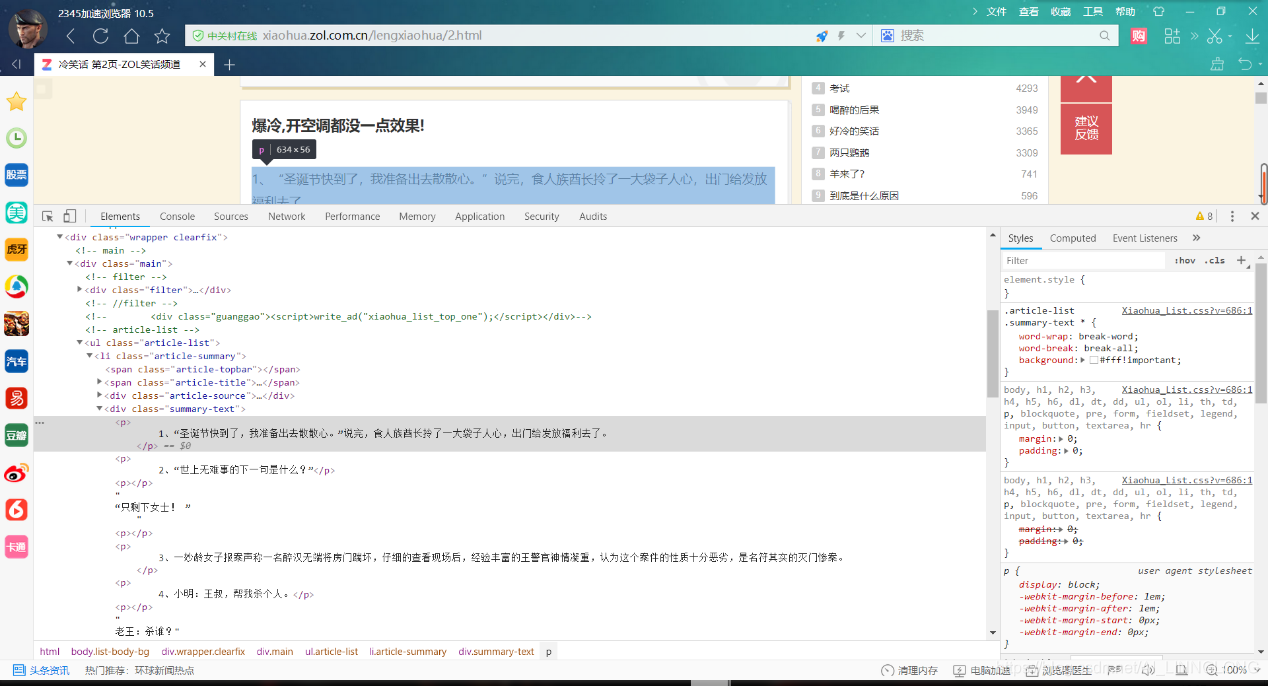
我们所需要的笑话都在p标签里
标题:
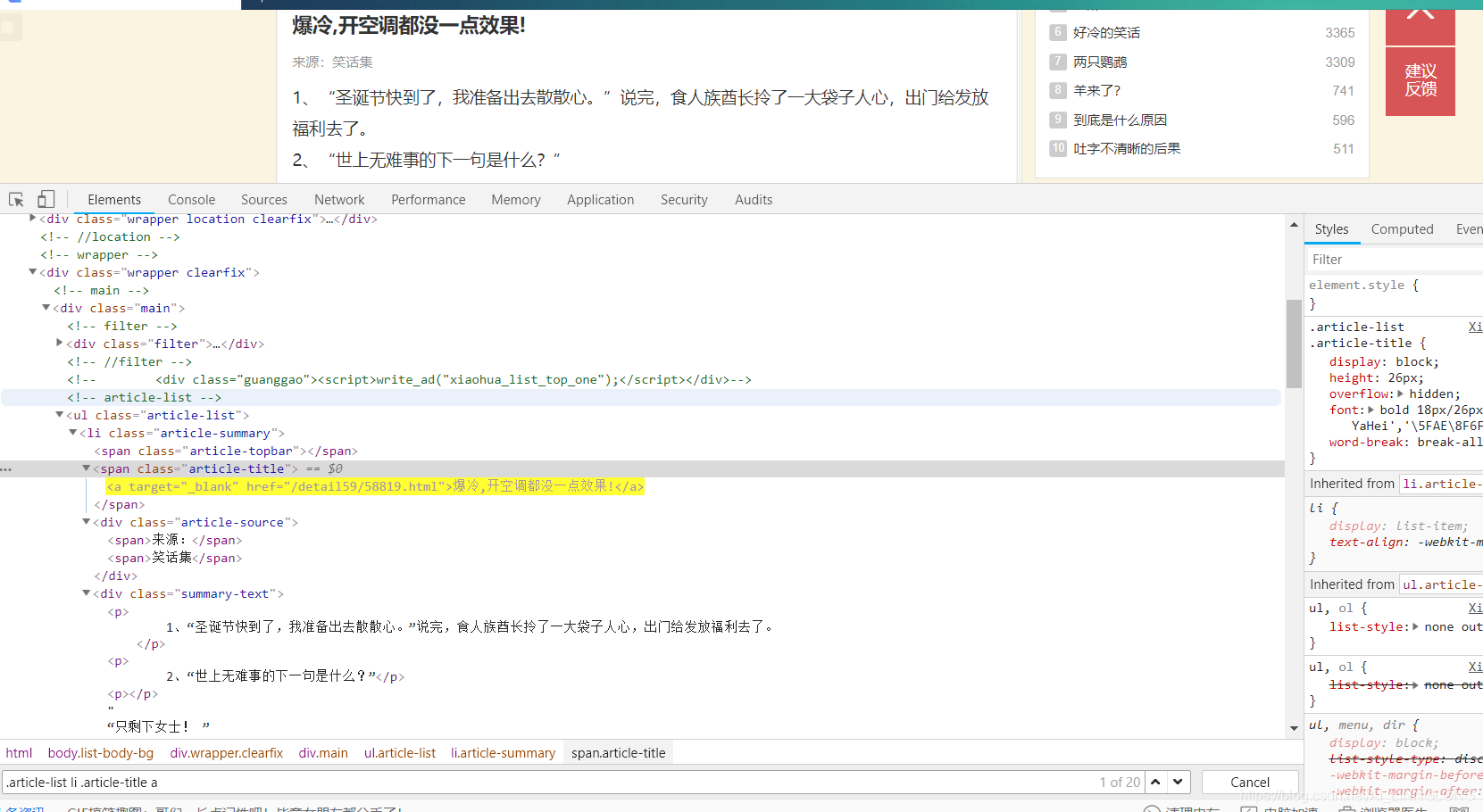
来源:
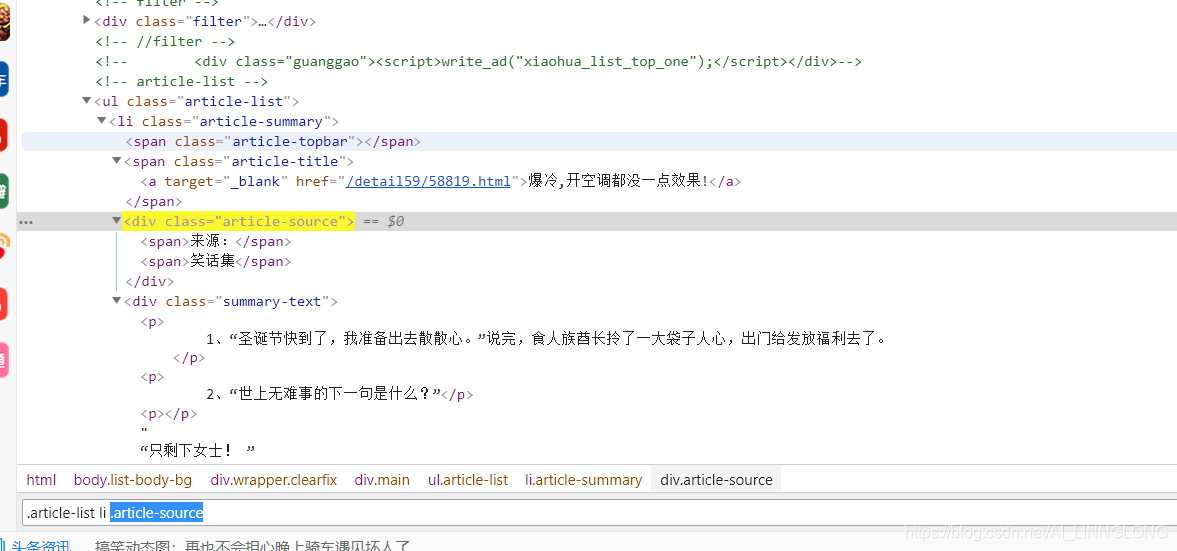
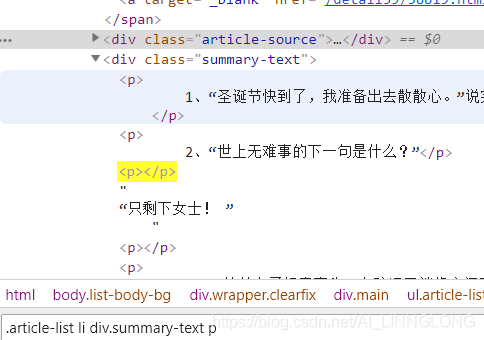
注意:我们可以利用.strip().replace(" ",'') 去除首位的空格和中间无用的空格
代码:
import requests
from bs4 import BeautifulSoup
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36'}
for i in range(1,100):
url='http://xiaohua.zol.com.cn/lengxiaohua/{}.html'.format(i)
html=requests.get(url,headers=headers)
text=html.text
soup=BeautifulSoup(text,"lxml")
lis=soup.select('.article-list li')
for li in lis:
title=li.select_one('.article-title a').text
content=li.select_one('.summary-text ').text
try:
source=li.select_one('.article-source').text
except:
source="未知来源"
print("标题:"+title.strip().replace(" ",''))
print("来源:"+source.strip().replace(" ",''))
print("内容: "+content.strip().replace(" ",''))
