1、Set 集合常用命令
- SADD
语法: SADD key member [member …]
时间复杂度: O(N), N 是被添加的元素的数量。
返回值: 被添加到集合中的新元素的数量,不包括被忽略的元素。
功能: 将一个或多个 member 元素加入到集合 key 当中,已经存在于集合的 member 元素将被忽略。假如 key 不存在,则创建一个只包含 member 元素作成员的集合。当 key 不是集合类型时,返回一个错误。
在Redis2.4版本以前, SADD 只接受单个 member 值。

-
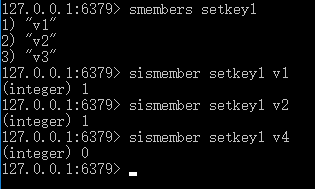
SISMEMBER
语法: SISMEMBER key member
时间复杂度: O(1)
返回值: 如果 member 元素是集合的成员,返回 1 。 如果 member 元素不是集合的成员,或 key 不存在,返回 0 。
功能: 判断 member 元素是否集合 key 的成员。
-
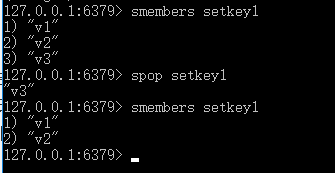
SPOP
语法: SPOP key
时间复杂度: O(1)
返回值: 被移除的随机元素。 当 key 不存在或 key 是空集时,返回 nil 。
功能: 移除并返回集合中的一个随机元素。如果只想获取一个随机元素,但不想该元素从集合中被移除的话,可以使用 SRANDMEMBER key [count] 命令。
-
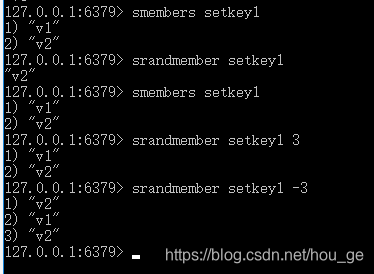
SRANDMEMBER
语法: SRANDMEMBER key [count]
时间复杂度: 只提供 key 参数时为 O(1) 。如果提供了 count 参数,那么为 O(N) ,N 为返回数组的元素个数。
返回值: 只提供 key 参数时,返回一个元素;如果集合为空,返回 nil 。 如果提供了 count 参数,那么返回一个数组;如果集合为空,返回空数组。
功能: 如果命令执行时,只提供了 key 参数,那么返回集合中的一个随机元素。
从 Redis 2.6 版本开始, SRANDMEMBER 命令接受可选的 count 参数:
- 如果 count 为正数,且小于集合基数,那么命令返回一个包含 count 个元素的数组,数组中的元素各不相同。如果 count 大于等于集合基数,那么返回整个集合。
- 如果 count 为负数,那么命令返回一个数组,数组中的元素可能会重复出现多次,而数组的长度为 count 的绝对值。
该操作和 SPOP key 相似,但 SPOP key 将随机元素从集合中移除并返回,而 SRANDMEMBER 则仅仅返回随机元素,而不对集合进行任何改动。
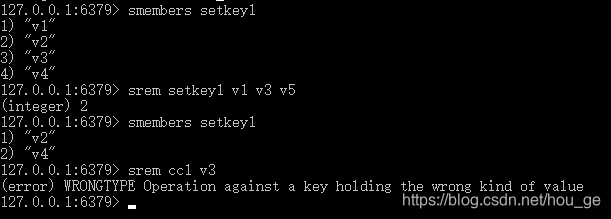
- SREM
语法: SREM key member [member …]
时间复杂度: O(N), N 为给定 member 元素的数量。
返回值: 被成功移除的元素的数量,不包括被忽略的元素。
功能: 移除集合 key 中的一个或多个 member 中,不存在的 member 元素会被忽略。当 key 不是集合类型,返回一个错误。
在 Redis 2.4 版本以前, SREM 只接受单个 member 值。
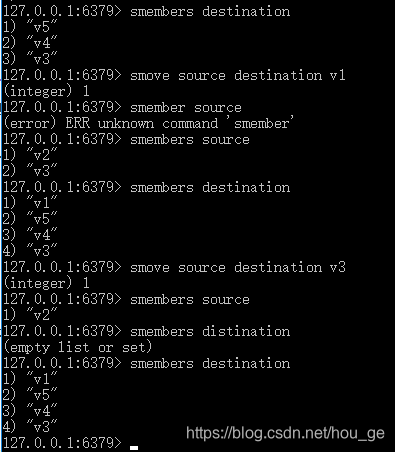
- SMOVE
语法: SMOVE source destination member
时间复杂度: O(1)
返回值: 如果 member 元素被成功移除,返回 1 。 如果 member 元素不是 source 集合的成员,并且没有任何操作对 destination 集合执行,那么返回 0。
功能: 将 member 元素从 source 集合移动到 destination 集合。
SMOVE 是原子性操作。如果 source 集合不存在或不包含指定的 member 元素,则 SMOVE 命令不执行任何操作,仅返回 0 。否则, member 元素从 source 集合中被移除,并添加到 destination 集合中去。当 destination 集合已经包含 member 元素时, SMOVE 命令只是简单地将 source 集合中的 member 元素删除。当 source 或 destination 不是集合类型时,返回一个错误。
-
SMEMBERS
语法: SMEMBERS key
时间复杂度: O(N), N 为集合的基数。
返回值: 集合中的所有成员。
功能: 返回集合 key 中的所有成员。不存在的 key 被视为空集合。 -
SCARD
语法: SCARD key
时间复杂度: O(1)
返回值: 集合的基数。 当 key 不存在时,返回 0 。
功能: 返回集合 key 的基数(集合中元素的数量)。 -
SSCAN
语法: SSCAN key cursor [MATCH pattern] [COUNT count]
时间复杂度: 增量式迭代命令每次执行的复杂度为 O(1) , 对数据集进行一次完整迭代的复杂度为 O(N) , 其中 N 为数据集中的元素数量。
返回值: 返回的每个元素都是一个集合成员
功能: 迭代集合键中的元素。扫描二维码关注公众号,回复: 9643280 查看本文章
-
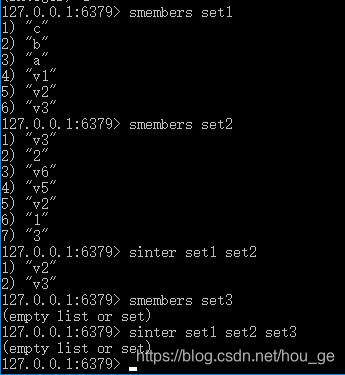
SINTER
语法: SINTER key [key …]
时间复杂度: O(N * M), N 为给定集合当中基数最小的集合, M 为给定集合的个数
返回值: 交集成员的列表。
功能: 返回一个集合的全部成员,该集合是所有给定集合的交集。不存在的 key 被视为空集。当给定集合当中有一个空集时,结果也为空集(根据集合运算定律)。
-
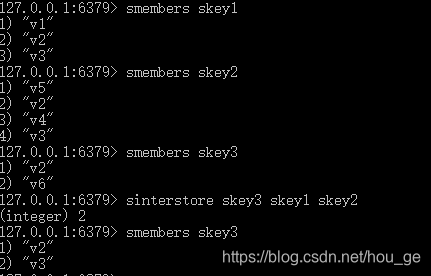
SINTERSTORE
语法: SINTERSTORE destination key [key …]
时间复杂度: O(N * M), N 为给定集合当中基数最小的集合, M 为给定集合的个数
返回值: 结果集中的成员数量。
功能: 这个命令类似于 SINTER key [key …] 命令,但它将结果保存到 destination 集合,而不是简单地返回结果集。如果 destination 集合已经存在,则将其覆盖(全覆盖)。destination 可以是 key 本身。
-
SUNION
语法: SUNION key [key …]
时间复杂度: O(N), N 是所有给定集合的成员数量之和。
返回值: 并集成员的列表。
功能: 返回一个集合的全部成员,该集合是所有给定集合的并集。不存在的 key 被视为空集。

-
SUNIONSTORE
语法: SUNIONSTORE destination key [key …]
时间复杂度: O(N), N 是所有给定集合的成员数量之和。
返回值: 结果集中的元素数量。
功能: 这个命令类似于 SUNION key [key …] 命令,但它将结果保存到 destination 集合,而不是简单地返回结果集。如果 destination 已经存在,则将其覆盖。destination 可以是 key 本身。 -
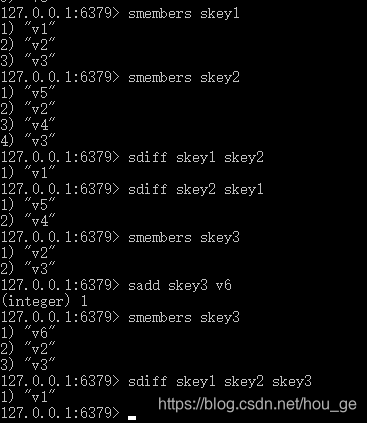
SDIFF
语法: SDIFF key [key …]
时间复杂度: O(N), N 是所有给定集合的成员数量之和。
返回值: 一个包含差集成员的列表。
功能: 返回一个集合的全部成员,该集合是所有给定集合之间的差集。不存在的 key 被视为空集。
-
SDIFFSTORE
语法: SDIFFSTORE destination key [key …]
时间复杂度: O(N), N 是所有给定集合的成员数量之和。
返回值: 结果集中的元素数量。
功能: 这个命令的作用和 SDIFF key [key …] 类似,但它将结果保存到 destination 集合,而不是简单地返回结果集。如果 destination 集合已经存在,则将其覆盖。destination 可以是 key 本身。
2、ZSet 有序集合常用命令
-
ZADD
语法: ZADD key score member [[score member] [score member] …]
时间复杂度: O(M*log(N)), N 是有序集的基数, M 为成功添加的新成员的数量。
功能: 将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
返回值: 被成功添加的新成员的数量,不包括那些被更新的、已经存在的成员。
如果某个 member 已经是有序集的成员,那么更新这个 member 的 score 值,并通过重新插入这个 member 元素,来保证该 member 在正确的位置上。
score 值可以是整数值或双精度浮点数。
如果 key 不存在,则创建一个空的有序集并执行 ZADD 操作。
当 key 存在但不是有序集类型时,返回一个错误。 -
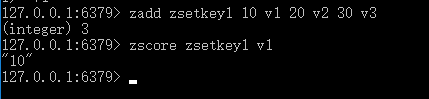
ZSCORE
语法: ZSCORE key member
时间复杂度: O(1)
功能: 返回有序集 key 中,成员 member 的 score 值。如果 member 元素不是有序集 key 的成员,或 key 不存在,返回 nil 。
返回值: member 成员的 score 值,以字符串形式表示。
-
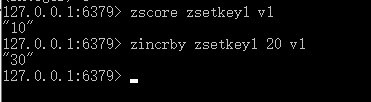
ZINCRBY
语法: ZINCRBY key increment member
时间复杂度: O(log(N))
功能: 为有序集 key 的成员 member 的 score 值加上增量 increment 。
返回值: member 成员的新 score 值,以字符串形式表示。
可以通过传递一个负数值 increment ,让 score 减去相应的值,比如 ZINCRBY key -5 member ,就是让 member 的 score 值减去 5 。当 key 不存在,或 member 不是 key 的成员时, ZINCRBY key increment member 等同于 ZADD key increment member 。当 key 不是有序集类型时,返回一个错误。score 值可以是整数值或双精度浮点数。
4. ZCARD
语法: ZCARD key
时间复杂度: O(1)
功能: 返回有序集 key 的基数。
返回值: 当 key 存在且是有序集类型时,返回有序集的基数。 当 key 不存在时,返回 0 。
5. ZCOUNT
语法: ZCOUNT key min max
时间复杂度: O(log(N)), N 为有序集的基数。
功能: 返回有序集 key 中, score 值在 min 和 max 之间(默认包括 score 值等于 min 或 max )的成员的数量。
返回值: score 值在 min 和 max 之间的成员的数量。
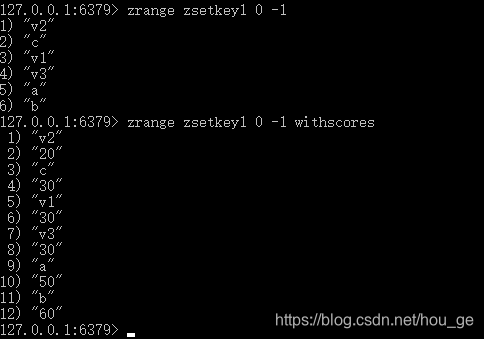
6. ZRANGE
语法: ZRANGE key start stop [WITHSCORES]
时间复杂度: O(log(N)+M), N 为有序集的基数,而 M 为结果集的基数。
功能: 返回有序集 key 中,指定区间内的成员。
返回值: 指定区间内,带有 score 值(可选)的有序集成员的列表。
其中成员的位置按 score 值递增(从小到大)来排序。
具有相同 score 值的成员按字典序(lexicographical order )来排列。
如果你需要成员按 score 值递减(从大到小)来排列,请使用 ZREVRANGE key start stop [WITHSCORES] 命令。
下标参数 start 和 stop 都以 0 为底,也就是说,以 0 表示有序集第一个成员,以 1 表示有序集第二个成员,以此类推。 你也可以使用负数下标,以 -1 表示最后一个成员, -2 表示倒数第二个成员,以此类推。
超出范围的下标并不会引起错误。 比如说,当 start 的值比有序集的最大下标还要大,或是 start > stop 时, ZRANGE 命令只是简单地返回一个空列表。 另一方面,假如 stop 参数的值比有序集的最大下标还要大,那么 Redis 将 stop 当作最大下标来处理。
可以通过使用 WITHSCORES 选项,来让成员和它的 score 值一并返回,返回列表以 value1,score1, …, valueN,scoreN 的格式表示。 客户端库可能会返回一些更复杂的数据类型,比如数组、元组等。
- ZREVRANGE
语法: ZREVRANGE key start stop [WITHSCORES]
时间复杂度: O(log(N)+M), N 为有序集的基数,而 M 为结果集的基数。
功能: 返回有序集 key 中,指定区间内的成员。
返回值: 指定区间内,带有 score 值(可选)的有序集成员的列表。
其中成员的位置按 score 值递减(从大到小)来排列。 具有相同 score 值的成员按字典序的逆序(reverse lexicographical order)排列。
除了成员按 score 值递减的次序排列这一点外, ZREVRANGE 命令的其他方面和 ZRANGE key start stop [WITHSCORES] 命令一样。
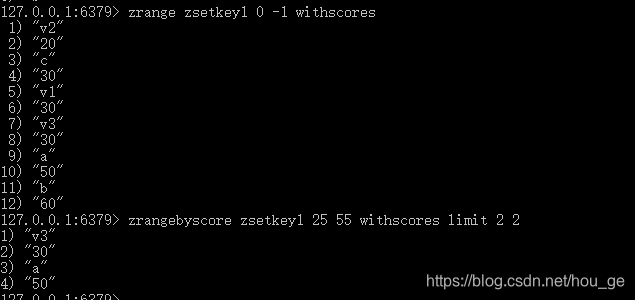
- ZRANGEBYSCORE
语法: ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
时间复杂度: O(log(N)+M), N 为有序集的基数, M 为被结果集的基数。
功能: 返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
返回值: 指定区间内,带有 score 值(可选)的有序集成员的列表。
具有相同 score 值的成员按字典序(lexicographical order)来排列(该属性是有序集提供的,不需要额外的计算)。
可选的 LIMIT 参数指定返回结果的数量及区间(就像SQL中的 SELECT LIMIT offset, count ),注意当 offset 很大时,定位 offset 的操作可能需要遍历整个有序集,此过程最坏复杂度为 O(N) 时间。
可选的 WITHSCORES 参数决定结果集是单单返回有序集的成员,还是将有序集成员及其 score 值一起返回。 该选项自 Redis 2.0 版本起可用。
9. ZREVRANGEBYSCORE
语法: ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]
时间复杂度: O(log(N)+M), N 为有序集的基数, M 为结果集的基数。
功能: 返回有序集 key 中, score 值介于 max 和 min 之间(默认包括等于 max 或 min )的所有的成员。有序集成员按 score 值递减(从大到小)的次序排列。
返回值: 指定区间内,带有 score 值(可选)的有序集成员的列表。
具有相同 score 值的成员按字典序的逆序(reverse lexicographical order )排列。
除了成员按 score 值递减的次序排列这一点外, ZREVRANGEBYSCORE 命令的其他方面和 ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] 命令一样。
-
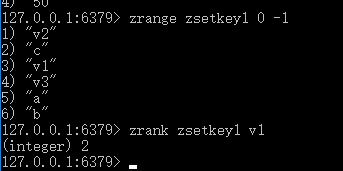
ZRANK
语法: ZRANK key member
时间复杂度: O(log(N))
功能: 返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递增(从小到大)顺序排列。排名以 0 为底,也就是说, score 值最小的成员排名为 0 。使用 ZREVRANK key member 命令可以获得成员按 score 值递减(从大到小)排列的排名。
返回值: 如果 member 是有序集 key 的成员,返回 member 的排名。 如果 member 不是有序集 key 的成员,返回 nil 。
-
ZREVRANK
语法: ZREVRANK key member
时间复杂度: O(log(N))
功能: 返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递减(从大到小)排序。排名以 0 为底,也就是说, score 值最大的成员排名为 0 。使用 ZRANK key member 命令可以获得成员按 score 值递增(从小到大)排列的排名。
返回值: 如果 member 是有序集 key 的成员,返回 member 的排名。 如果 member 不是有序集 key 的成员,返回 nil 。 -
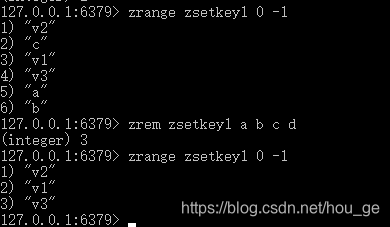
ZREM
语法: ZREM key member [member …]
时间复杂度: O(M*log(N)), N 为有序集的基数, M 为被成功移除的成员的数量。
功能: 移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。当 key 存在但不是有序集类型时,返回一个错误。
返回值: 被成功移除的成员的数量,不包括被忽略的成员。
-
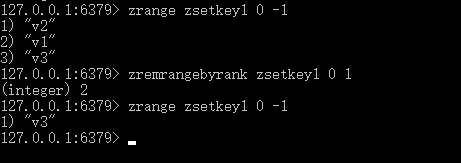
ZREMRANGEBYRANK
语法: ZREMRANGEBYRANK key start stop
时间复杂度: O(log(N)+M), N 为有序集的基数,而 M 为被移除成员的数量。
功能: 移除有序集 key 中,指定排名(rank)区间内的所有成员。
返回值: 被移除成员的数量。
区间分别以下标参数 start 和 stop 指出,包含 start 和 stop 在内。
下标参数 start 和 stop 都以 0 为底,也就是说,以 0 表示有序集第一个成员,以 1 表示有序集第二个成员,以此类推。 你也可以使用负数下标,以 -1 表示最后一个成员, -2 表示倒数第二个成员,以此类推。
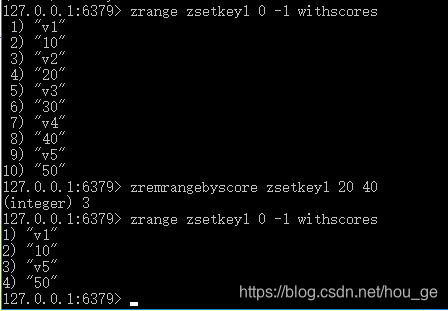
14. ZREMRANGEBYSCORE
语法: ZREMRANGEBYSCORE key min max
时间复杂度: O(log(N)+M), N 为有序集的基数,而 M 为被移除成员的数量。
功能: 移除有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。
返回值: 被移除成员的数量。
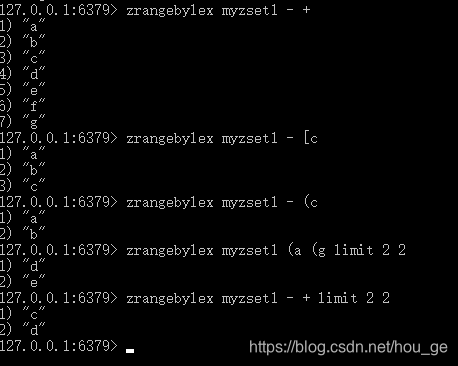
- ZRANGEBYLEX
语法: ZRANGEBYLEX key min max [LIMIT offset count]
时间复杂度: O(log(N)+M), 其中 N 为有序集合的元素数量, 而 M 则是命令返回的元素数量。 如果 M 是一个常数(比如说,用户总是使用 LIMIT 参数来返回最先的 10 个元素), 那么命令的复杂度也可以看作是 O(log(N)) 。
功能: 当有序集合的所有成员都具有相同的分值时, 有序集合的元素会根据成员的字典序(lexicographical ordering)来进行排序, 而这个命令则可以返回给定的有序集合键 key 中, 值介于 min 和 max 之间的成员。
返回值: 数组回复:一个列表,列表里面包含了有序集合在指定范围内的成员。
如果有序集合里面的成员带有不同的分值, 那么命令返回的结果是未指定的(unspecified)。 官方文档上这句解释,未明白含义,验证分值不一样,还是按照实际的顺序返回数据。
命令会使用 C 语言的 memcmp() 函数, 对集合中的每个成员进行逐个字节的对比(byte-by-byte compare), 并按照从低到高的顺序, 返回排序后的集合成员。 如果两个字符串有一部分内容是相同的话, 那么命令会认为较长的字符串比较短的字符串要大。
可选的 LIMIT offset count 参数用于获取指定范围内的匹配元素 (就像 SQL 中的 SELECT LIMIT offset count 语句)。 需要注意的一点是, 如果 offset 参数的值非常大的话, 那么命令在返回结果之前, 需要先遍历至 offset 所指定的位置, 这个操作会为命令加上最多 O(N) 复杂度。
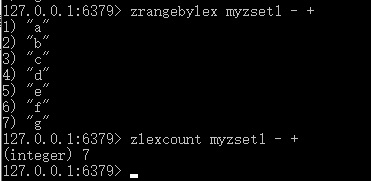
16. ZLEXCOUNT
语法: ZLEXCOUNT key min max
时间复杂度: O(log(N)),其中 N 为有序集合包含的元素数量。
功能: 对于一个所有成员的分值都相同的有序集合键 key 来说, 这个命令会返回该集合中, 成员介于 min 和 max 范围内的元素数量。
返回值: 整数回复:指定范围内的元素数量。
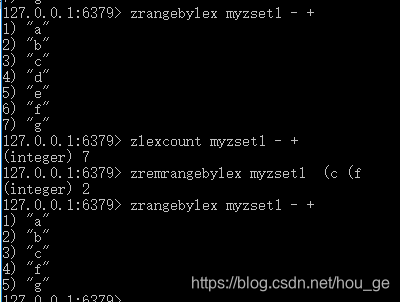
17. ZREMRANGEBYLEX
语法: ZREMRANGEBYLEX key min max
时间复杂度: O(log(N)+M), 其中 N 为有序集合的元素数量, 而 M 则为被移除的元素数量。
功能: 对于一个所有成员的分值都相同的有序集合键 key 来说, 这个命令会移除该集合中, 成员介于 min 和 max 范围内的所有元素。
返回值: 整数回复:被移除的元素数量。
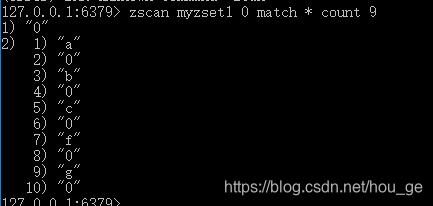
18. ZSCAN
语法: ZSCAN key cursor [MATCH pattern] [COUNT count]
时间复杂度: 增量式迭代命令每次执行的复杂度为 O(1) , 对数据集进行一次完整迭代的复杂度为 O(N) , 其中 N 为数据集中的元素数量。
功能: 用于迭代有序集合中的元素(包括元素成员和元素分值)
返回值: 返回的每个元素都是一个有序集合元素,一个有序集合元素由一个成员(member)和一个分值(score)组成。
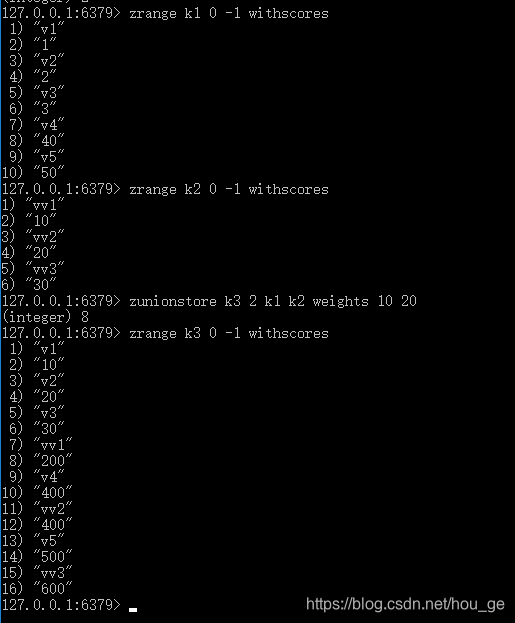
19. ZUNIONSTORE
语法: ZUNIONSTORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX]
时间复杂度: O(N)+O(M log(M)), N 为给定有序集基数的总和, M 为结果集的基数。
功能: 计算给定的一个或多个有序集的并集,其中给定 key 的数量必须以 numkeys 参数指定,并将该并集(结果集)储存到 destination 。默认情况下,结果集中某个成员的 score 值是所有给定集下该成员 score 值之 和 。
返回值: 保存到 destination 的结果集的基数。
WEIGHTS
使用 WEIGHTS 选项,你可以为 每个 给定有序集 分别 指定一个乘法因子(multiplication factor),每个给定有序集的所有成员的 score 值在传递给聚合函数(aggregation function)之前都要先乘以该有序集的因子。
如果没有指定 WEIGHTS 选项,乘法因子默认设置为 1 。
AGGREGATE
使用 AGGREGATE 选项,你可以指定并集的结果集的聚合方式。
默认使用的参数 SUM ,可以将所有集合中某个成员的 score 值之 和 作为结果集中该成员的 score 值;使用参数 MIN ,可以将所有集合中某个成员的 最小 score 值作为结果集中该成员的 score 值;而参数 MAX 则是将所有集合中某个成员的 最大 score 值作为结果集中该成员的 score 值。
20. ZINTERSTORE
语法: ZINTERSTORE destination numkeys key [key …] [WEIGHTS weight [weight …]] [AGGREGATE SUM|MIN|MAX]
时间复杂度: O(NK)+O(Mlog(M)), N 为给定 key 中基数最小的有序集, K 为给定有序集的数量, M 为结果集的基数。
功能: 计算给定的一个或多个有序集的交集,其中给定 key 的数量必须以 numkeys 参数指定,并将该交集(结果集)储存到 destination 。默认情况下,结果集中某个成员的 score 值是所有给定集下该成员 score 值之和.
返回值: 保存到 destination 的结果集的基数。

