AVX / AVX2 指令编程
https://zhuanlan.zhihu.com/p/94649418 感觉讲的很好呢 我就是还没理解AVX2和AVX512的区别
最近在做加密算法的加速,因为有大量基于C的矩阵运算,优化需要用到AVX指令。这文章不是系统介绍,只是普通的入门笔记,主要内容为function的介绍(documentation的汉化)。转载请注明出处,不然我会画圈圈诅咒你以后写不出代码只写得出bug>_<。
阅读前需要掌握:
- 基本的C语言
- 理解什么是SIMD
官方资料(能看的话就不要看任何我写的废话了):
关于intel的SSE,AVX,AVX2,AVX512等所有指令中的方法都可以在这里找到:
PDF版本:
19.0U1_CPP_Compiler_DGR_0.pdf在线版(可筛选):
Intrinsics GuideA taste of SIMD / 小试牛刀 - 使用SIMD编程:
 来源:https://software.intel.com/en-us/articles/introduction-to-intel-advanced-vector-extensions
来源:https://software.intel.com/en-us/articles/introduction-to-intel-advanced-vector-extensions
未使用SIMD:
vectorAdd(const float* a, const float* b, const float* c){ for(int i=0; i<8; i++) { c[i] = a[i] + b[i]; //一条代码仅能操作2个单个值进行运算 } //需要重复循环操作才能运算完整个数组间的加法 }使用AVX:
__m256 vectorAdd(__m256 a, __m256 b, __m256 c) {
return _mm256_add_ps(a,b); //一个方法可以同时操作整个数组进行运算 - 一步到位
}AVX中常见的数据类型
处理avx向量(数组)的时候,最好以bit的单位去看每个数。
幼儿园化介绍:
数据类型前面带两个下划线
名字里带128的 = 一个向量包含128个bit = 32 byte
名字里带256的 = 一个向量包含256个bit = 64 byte
尾巴啥也不带的 = 里面都是float,一个float=32bit,自己除一下里面有几个
尾巴带d的 = 里面都是double,一个double=64bit,自己除一下里面有几个
尾巴带i的 = 里面都是整型,根据整型的类型不同,个数也不同
正经介绍:
两种浮点向量被单独列出:__m128,__m256,每个数由4byte的float构成;__m128d,__m256d,每个数由8byte的double构成。
而__m128i,__m256i是由整型构成的向量,char,short,int,long均属于整型(以及unsigned以上类型),所以例如__m256i就可以由32个char,或者16个short,或者8个int,又或者4个long构成。
另外:AVX-512同理,即m512 / m512d / m512i
函数名称
_mm<bit_width>_<name>_<data_type><bit_width>返回的向量的类型,返回的是256bit大小的就是256,返回128大小的,这里就是空的。还有一些特殊的:store没有返回(void);test系列比较两个输入是否相同,返回0或1。<name>函数的名字,基本通过名字就可以看出功能啦~<data_type>表示这个函数在处理数据时,会把输入的数据当作什么类型去处理
关于<data_type>,因为m256i / m128i中的整型多种多样,需要告诉AVX里面的整型大小(size)是多少。
ps:里面都是float,把32bits当成一个数看pd:里面都是double,把64bits当成一个数看epi8/epi16/epi32/epi64:向量里每个数都是整型,一个整型8bit/16bit/32bit/64bitepu8/epu16/epu32/epu64:向量里每个数都是无符号整型(unsigned),一个整型8bit/16bit/32bit/64bitm128/m128i/m128d/m256/m256i/m256d:输入值与返回类型不同时会出现 ,例如__m256i_mm256_setr_m128i(__m128ilo,__m128ihi),输入两个__m128i向量 ,把他们拼在一起,变成一个__m256i返回 。另外这种结尾只见于loadsi128/si256:不care向量里到底都是些啥类型,反正128bit/256bit,例如:
__m256i _mm_broadcastsi128_si256 (__m128i a)此函数接收一个128-bit的__m128i,然后将这__m128i的128位,按位放入返回的__m256i 类型的前128位(127-0)中,再按位放入(复制到)后128位(255-128)中。因为不涉及单个数操作,将128位看成整体操作,所以不用在意其中每个数的数据类型。
si128/si256基本只见于
broadcast:复制2遍__m128i,放入__m256i;cast:__m128i转型__m256i(upper 128 bit undefined) ,__m256i转型__m128i
总而言之5 & 6两种并不太常见。
小测验:
- 现在我已经加载一个int a[32]到一个
__m256i中,我想把每两个int当作一个数去操作(a[0], a[1]当作一个数,a[2], a[3]当作一个数,以此类推),我给这个操作起名为"嘟嘟魔法",最后返回一个__m256i类型的向量,这个函数应该叫什么名字呢? [1] (答案在注释里)
用于【初始化 / 加载 】的函数
Intrinsics for Load and Store Operations (& Set Operations )
今天不想细写,列个提纲
- 初始化全0
- 手动给值初始化
- 从现有数组加载
- 从pointer/地址加载
常用【加减乘除法】的函数 - Intrinsics for Arithmetic Operations
pending
看完加减法之后故名字义也都能会的函数们
- Intrinsics for Bitwise Operations - 按位逻辑操作
- 按位
and/andnot/or/xor - AVX2中只有输入为
m256i类型,输出也为m256i类型的按位逻辑函数 - Intrinsics for Compare Operations - 比较操作
_mm256_cmpeq_epi8/16/32/64- 输入两个
__m256i, 以每8/16/32/64个bit为一个数, - 逐个数比较两个输入向量是否相同,
- 如果相同,则将返回向量中该数所对应的bit全设为1,
- 若不同, 则则将返回向量中该数所对应的bit全设为0
_mm256_cmpgt_epi8/16/32/64- 输入两个
__m256i:s1和s2, 以每8/16/32/64个bit为一个数 - 如果
s1的第i个数>s2的第i个数, 则将返回向量中该数所对应的bit全设为1 - 如果
s1的第i个数<=s2的第i个数, 则将返回向量中该数所对应的bit全设为0 _mm256_max_epi8/16/32- 将返回向量中该数所对应的bit,设为s1[i]或s2[i]中较为大的那个数
_mm256_max_epu8/16/32_mm256_min_epi8/16/32- 将返回向量中该数所对应的bit,设为s1[i]或s2[i]中较为小的那个数
_mm256_min_epu8/16/32
加减乘融合函数 - (AVX2)Intrinsics for Fused Multiply Add Operations
- 包含的函数(如果不是常用就不用记了)
- 1区:
_mm/_mm256 - 2区:
_fmadd/fmsub/fmaddsub/fmsubadd/fnmadd/fnmsub - 3区:
ps/pd - 1区+2区+3区 所有排列组合共计 24个
- 4区:
_mm - 4区:
_fmadd/fmsub/fnmadd/fnmsub - 6区:
ss/sd - 4区+ 5区+5区 所有排列组合共计 8个
简单记忆:_mm256无ss与sd,fmaddsub 和 fmsubadd 也无ss与sd
重排? 混选?我不知道中文是啥 - Intrinsics for Permute Operations
- _mm256_permutevar8x32_epi32
__m256i _mm256_permutevar8x32_epi32(__m256i a,__m256i idx)- _mm256_permutevar8x32_ps
__m256 _mm256_permutevar8x32_ps(__m256 a,__m256i idx)- _mm256_permute4x64_epi64
__m256i _mm256_permute4x64_epi64(__m256i a,const int imm8)- _mm256_permute4x64_pd
__m256d _mm256_permute4x64_pd(__m256d a,const int imm8)- _mm256_permute2x128_si256
__m256i _mm256_permute2x128_si256(__m256i a,__m256i b,const int imm8)
图解permute
前两个:_mm256_permutevar8x32_epi32 与 _mm256_permutevar8x32_ps ,输入与返回类型不一样。
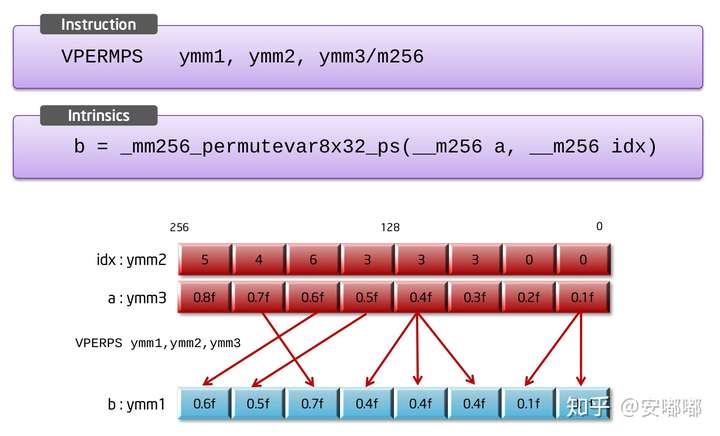 _mm256_permutevar8x32_ps
_mm256_permutevar8x32_ps
a为输入的源,b为返回的向量,idx为重排的index索引
即:假设idx[i]里存的值为m,操作即为b[i] = a[m]
中间两个同理:_mm256_permute4x64_epi64 输入输出均为__m256i; _mm256_permute4x64_pd 输入输出均为 __m256d
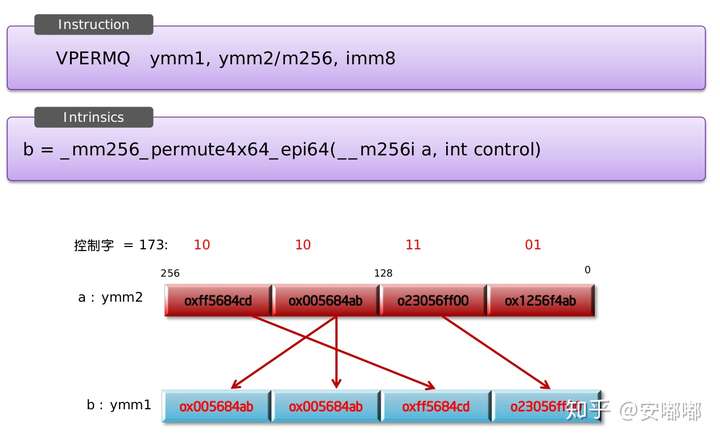 _mm256_permute4x64_epi64
_mm256_permute4x64_epi64
a为输入的源,b为返回的向量,imm8/control为重排的index索引
将int类的control以2进制读出(按bit读),按(_m256i)/(epi64) = 4,切分为4份,生成所对应的索引
如图示:索引control = 173,二进制为10101101,被切割后分别为10,10,11,01。翻译为十进制,理解为每个数的重排索引m分别为2,2,3,1。应用b[i] = a[m]
即:b[3]=a[2]; b[2]=a[2]; b[1]=a[3]; b[0]=a[1]
略有不同的重排? 混选?指令 - Intrinsics for Shuffle Operations
我称之为"有壁的混选指令"
对于输入输出为128bit的向量而言:
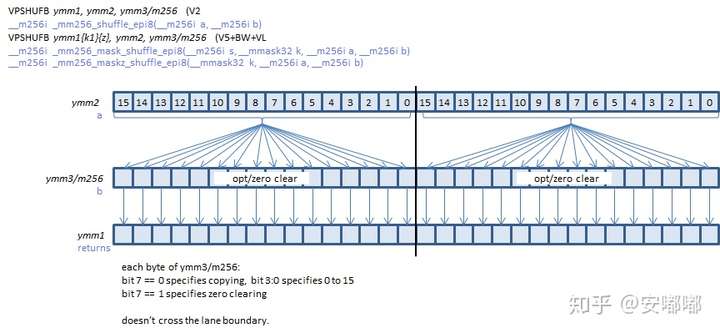
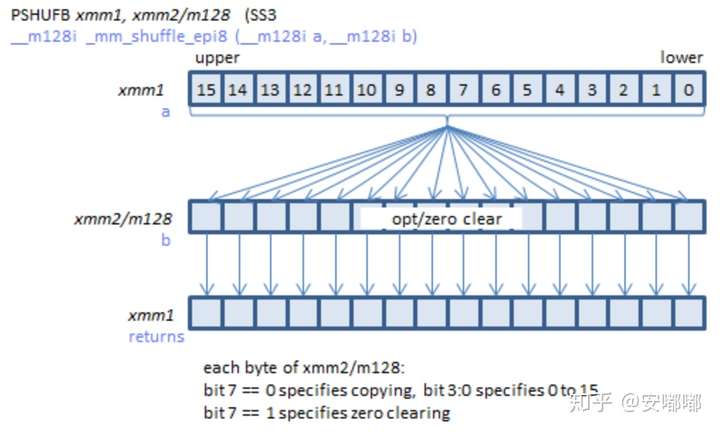 图源:https://www.officedaytime.com/simd512e/simdimg/si.php?f=pshufb
图源:https://www.officedaytime.com/simd512e/simdimg/si.php?f=pshufb
当b[i]的第7位bit为1时,return[i] =0
当b[i]的第7位bit为0时,读b[i]的前4位bit所组成的值=m,return[i]=a[m]
对于输入输出大于128bit的向量而言,如_mm256_shuffle_epi8 ,_mm512_shuffle_epi8 :
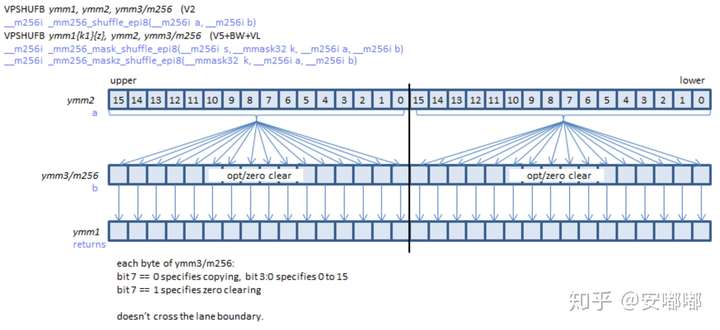 256/512同理 详见https://www.officedaytime.com/simd512e/simdimg/si.php?f=pshufb
256/512同理 详见https://www.officedaytime.com/simd512e/simdimg/si.php?f=pshufb
每128位为一个lane,重排范围只能在128位内,不能将前128位的内容重排至后128位。其他同理与128bit的shuffle。
- _mm256_shuffle_epi8
- _mm256_shuffle_epi32
- _mm256_shufflehi_epi16
- _mm256_shufflelo_epi16
可变位移指令 - (AVX2)Intrinsics for Logical Shift Operations
每个数都可以有不同的移位,即可以让一个向量中的每个数,都能shift不同的位数(方向只能相同)。AVX2之前只可以做相同位数的shift。
pending
离散数据加载 - (AVX2)Intrinsics for GATHER Operations
pending
参考
- ^答案:叫_mm256i_dodoMagic_epi16 (__m256i a),参数为__m256i,返回类型也为__m256i