文章目录
本文是接着上一篇 hadoop系列之使用jar命令提交任务
在上一篇我们最后画了一张图:
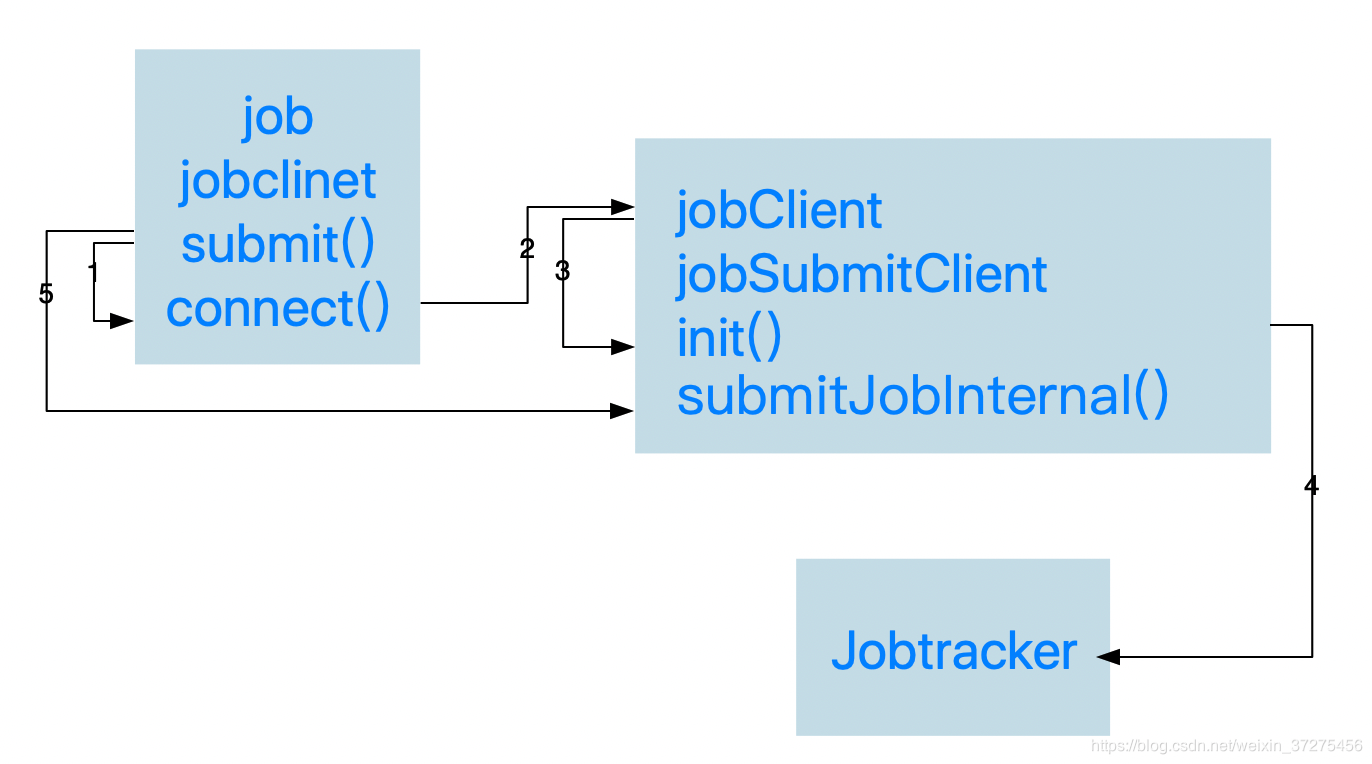
我们再jobClient调用init()函数的时候通过RPC获得了一个Jobtracker实例。然后在job调用submitJobInternal()的时候又调用了jobtracker的submitJob().接下来我们从submitJob()函数讲解jobtracker.
一、Jobtracker启动
前面说到client通过RPC调用了Jobtracker的submitJob()操作,那Jobtracker作为RPC的服务端,在启动的时候又做了哪些事情呢?
Jobtracker是一个独立的后台进程,其启动显然是要从main函数启动
public static void main(String argv[]
) throws IOException, InterruptedException {
StringUtils.startupShutdownMessage(JobTracker.class, argv, LOG);
try {
if(argv.length == 0) {
JobTracker tracker = startTracker(new JobConf());
tracker.offerService();
}
else {
if ("-dumpConfiguration".equals(argv[0]) && argv.length == 1) {
dumpConfiguration(new PrintWriter(System.out));
}
else {
System.out.println("usage: JobTracker [-dumpConfiguration]");
System.exit(-1);
}
}
} catch (Throwable e) {
LOG.fatal(StringUtils.stringifyException(e));
System.exit(-1);
}
}
main数里主要有两句话:
JobTracker tracker = startTracker(new JobConf()); // 1
tracker.offerService(); // 2
JobTracker tracker = startTracker(new JobConf())` 主要对JobTracker 类进行一些必要的初始化.在初始化过程中有两个比较关键的地方:
- 在
result = new JobTracker(conf, identifier)的时初始化的时候,做了如下几件事情:- 初始化secretManager和aclsManager,对安全和用户权限管理类做初始化
- 通过反射实例化资源调度器 (taskScheduler),实现资源调度器可拔插机制
- 启动rpc服务器(interTrackerServer)
- 启动web服务(infoServer)
- 加载用户配置的job.tracker参数
- 启动作业恢复管理器(recoveryManager)
- 历史记录查看服务启动(jobHistoryServer)
- 实例化网络拓扑管理器(dnsToSwitchMapping)
result.taskScheduler.setTaskTrackerManager(result);将上一步实例化的Jobracker作为参数反注册给资源调度器.这里实质上是使用了观察者模式,而且是双向耦合的观察者模式public static JobTracker startTracker(JobConf conf, String identifier) throws IOException, InterruptedException { DefaultMetricsSystem.initialize("JobTracker"); JobTracker result = null; while (true) { try { result = new JobTracker(conf, identifier); result.taskScheduler.setTaskTrackerManager(result); break; } catch (VersionMismatch e) { throw e; } catch (BindException e) { throw e; } catch (UnknownHostException e) { throw e; } catch (AccessControlException ace) { // in case of jobtracker not having right access // bail out throw ace; } catch (IOException e) { LOG.warn("Error starting tracker: " + StringUtils.stringifyException(e)); } Thread.sleep(1000); } if (result != null) { JobEndNotifier.startNotifier(); MBeans.register("JobTracker", "JobTrackerInfo", result); } return result; }
通过tracker.offerService()启动一些重要的后台进程
- 该方法首先要更新重启次数.代码如下.如果更新成功就继续,更新不成功就再次循环.
while (true) {
try {
recoveryManager.updateRestartCount();
break;
} catch (IOException ioe) {
LOG.warn("Failed to initialize recovery manager. ", ioe);
// wait for some time
Thread.sleep(FS_ACCESS_RETRY_PERIOD);
LOG.warn("Retrying...");
}
}
-
然后是启动任务调度器,默认的任务调度器是
JobQueueTaskScheduler.并非一个线程或者进程~~(详解任务调度器:JobQueueTaskScheduler)~~taskScheduler.start();start()代码如下所示,如果有作业被提交给 jobTracker,则
public synchronized void start() throws IOException { super.start(); // 添加JobInProgressListener,这是作业收听实例。 // 作业收听实例的作用是监听作业的提交。 // 下面的taskTrackerManager实际上是JobTracker taskTrackerManager.addJobInProgressListener(jobQueueJobInProgressListener); // 设置并启动askTrackerManager。 eagerTaskInitializationListener.setTaskTrackerManager(taskTrackerManager); eagerTaskInitializationListener.start(); // 添加eagerTaskInitializationListener作为作业收听实例,用于排序 taskTrackerManager.addJobInProgressListener(eagerTaskInitializationListener);
}
```
- tracker.offerService(); 的作用主要就是启动taskScheduler。此外还启动了一系列其他的东西。
expireTrackersThread // 发现和清理死掉的TaskTracker
retireJobsThread //清理已经完成的作业信息
expireLaunchingTaskThread // 处理发送给某个taskTracker但是一直没有汇报的任务
completedJobsStoreThread // 将已经完成的作业信息保存到hdfs上
