一、FutureTask 获取线程返回值
1.1、Callable与Runnable接口对比
(1)Callable接口和Future接口的作用
- 通常实现一个线程我们会使用继承Thread的方式或者实现Runnable接口,这两种方式有一个共同的缺陷就是在执行完任务之后无法获取执行结果。从Java1.5之后就提供了Callable与Future,这两个接口就可以实现获取任务执行结果。
(2)Runnable接口
- 代码非常简单,只有一个方法run
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
(3)Callable泛型接口
- 有泛型参数,提供了一个call方法,执行后可返回传入的泛型参数类型的结果。
- 两者功能大致相似,callable更强大一些,它的线程执行后会有返回值,并且能够抛出异常
public interface Callable<V> {
V call() throws Exception;
}
1.2、Future接口
(1)Future接口提供了一系列方法用于控制线程执行计算
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
//取消任务
boolean isCancelled();
//是否被取消
boolean isDone();
//计算是否完成
V get() throws InterruptedException, ExecutionException;
//获取计算结果,在执行过程中任务被阻塞
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
//timeout等待时间、unit时间单位
}
(2)使用Callable和Future实现线程通信
@Slf4j
public class FutureExample {
static class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
log.info("do something in callable");
Thread.sleep(5000);
return "Done";
}
}
public static void main(String[] args) throws InterruptedException, ExecutionException {
ExecutorService executor = Executors.newCachedThreadPool();
Future<String> future = executor.submit(new MyCallable());
log.info("do something in main");
//如果上面的submit方法没有执行完,则一直阻塞在get这里
String result = future.get();
log.info("result :{}",result);
}
}
/*输出:等待了五秒才获取到返回值
10:36:43.210 [main] INFO com.tangxz._8.FutureExample - do something in main
10:36:43.210 [pool-1-thread-1] INFO com.tangxz._8.FutureExample - do something in callable
10:36:48.213 [main] INFO com.tangxz._8.FutureExample - result :Done
*/
1.3、FutureTask类
- 父类是
RunnableFuture,RunnableFuture继承了Runnable和Future这两个接口。由此可以知道FutureTask也是执行类似于Callable类型的任务。- 如果构造函数参数是
Runnable的话,它会转换成Callable类型。FutureTask又可以作为Runnable被线程执行,也可以作为Future得到callable的返回值。- 好处:①假如有一个很费时的逻辑需要计算并且返回这个值,同时这个值又不是马上需要,那就可以使用这个组合,用另外的一个线程去计算返回值,而当前线程在使用这个返回值之前,可以做其它的操作,等到需要这个返回值时,再通过future得到。
(1)Future实现了RunnableFuture接口,而RunnableFuture接口继承了Runnable与Future接口,所以它既可以作为Runnable被线程中执行,又可以作为callable获得返回值。
public class FutureTask<V> implements RunnableFuture<V> {
...
}
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
(2)FutureTask支持两种参数类型,Callable和Runnable,在使用Runnable 时,还可以多指定一个返回结果类型。
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
(3)使用FutureTask
@Slf4j
public class FutureTaskExample {
public static void main(String[] args) throws InterruptedException, ExecutionException {
FutureTask<String> futureTask = new FutureTask<>(new Callable<String>() {
@Override
public String call() throws Exception {
log.info("do something in callable");
Thread.sleep(5000);
return "Done";
}
});
new Thread(futureTask).start();
log.info("do something in main");
Thread.sleep(1000);
String result = futureTask.get();
log.info("result :{}",result);
}
}
二、Fork/Join框架
2.1、ForkJoin简介
ForkJoin是Java7提供的一个并行执行任务的框架,是把大任务分割成若干个小任务,待小任务完成后将结果汇总成大任务结果的框架。主要采用的是工作窃取算法,工作窃取算法是指某个线程从其他队列里窃取任务来执行。
2.2、工作窃取算法
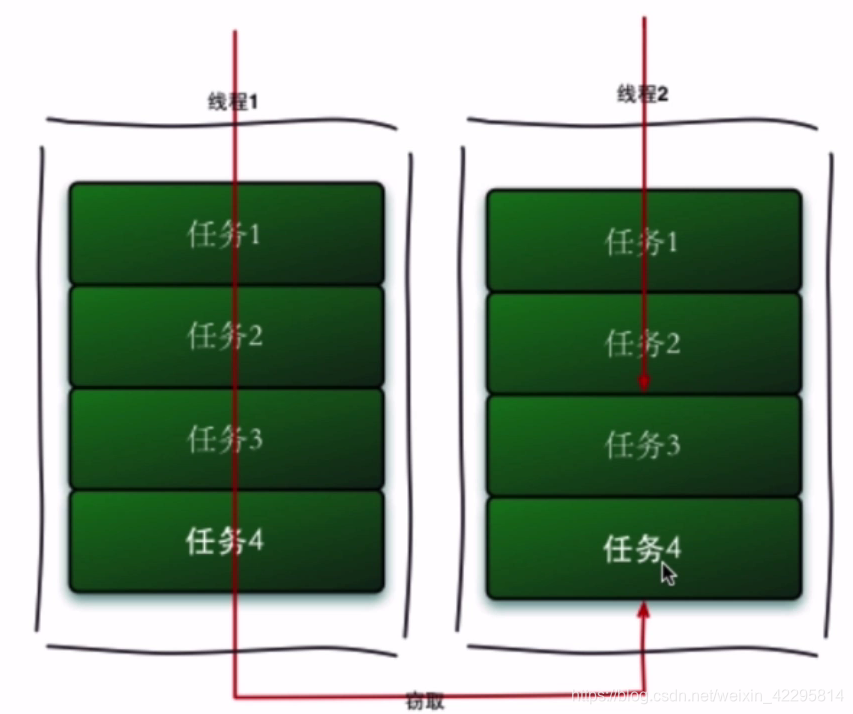
- 右边从顶部开始执行,从尾部开始窃取。
- 为了减少线程的竞争,把大任务分成小任务,再分配到不同的个队列中线程和队列一一对应。
- 先执行完自己的任务,再帮助别人完成别人的任务,就从其它线中窃取任务来执行,在这时他们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,外面会使用双端队列,被窃取任务的队列永远从双端队列的头部拿任务来执行,而窃取任务的线程则永远从双端队列的尾部拿任务来执行。
- 工作窃取算法的优点是充分利用线程进行并行计算并减少了线程间的竞争。
- 工作窃取算法的缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时,同时这样也消耗了更多的系统资源,比如创建了多个线程和多个双端队列。
- 对于fork框架而言,当一个任务正在等待他使用down操作创建的子任务结束时,执行这个任务的工作线程,查找其它未被执行的工作任务,并开始它的执行,通过这种方式线程充分的运用他们的运行时间来提高应用程序的性能。要实现这个目标,fork框架有一定的局限性。
2.3、ForkJoin局限性
- 任务只能使用fork和join操作来作为同步机制,如果使用了其它同步机制,那他们在同步操作时,工作线程就不能执行其它任务了,比如在fork框架中使任务进入了睡眠,那么这个睡眠区间内,正在执行这个任务的工作线程就不会执行其它任务了。
- 我们在执行的任务不应该去执行io操作,如读写数据文件
- 任务不能抛出检查异常,必须通过必要的代码来处理他们
2.4、ForkJoin框架核心
核心有两个类:ForkJoinPool | ForkJoinTask
(1)ForkJoinPool
负责来做实现,包括工作窃取算法、管理工作线程和提供关于任务的状态以及他们的执行信息。
(2)ForkJoinTask
提供在任务中执行fork和join的机制。
2.5、ForkJoin使用(模拟加和运算)
/**
* @Info: 继承的类字面意思就是递归的意思
* @Author: 唐小尊
* @Date: 2019/12/29 9:41
*/
@Slf4j
public class ForkJoinTaskExample extends RecursiveTask<Integer> {
private static final int threshold = 2;
private int start;
private int end;
public ForkJoinTaskExample(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
//如果任务足够小就计算任务
boolean canCompute = (end - start) <= threshold;
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
//如果任务大于阈值,就分裂成两个子任务计算
int middle = (start + end) / 2;
ForkJoinTaskExample leftTask = new ForkJoinTaskExample(start, middle);
ForkJoinTaskExample rightTask = new ForkJoinTaskExample(middle + 1, end);
//执行子任务
leftTask.fork();
rightTask.fork();
//等待任务执行结束合并其结果
int leftResult = leftTask.join();
int rightResult = rightTask.join();
//合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
//生成一个计算任务,计算1+2+3+4
ForkJoinTaskExample task = new ForkJoinTaskExample(1, 100);
//执行一个任务
Future<Integer> result = forkJoinPool.submit(task);
try {
log.info("result:{}", result.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
}
三、BlockingQueue 阻塞队列
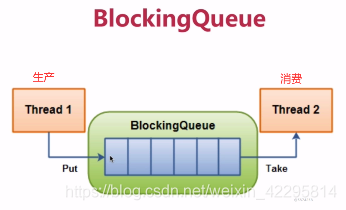
3.1、阻塞队列
3.1.1、阻塞队列是什么
- 阻塞队列是一个队列,在某些情况下对阻塞队列的访问可能会造成阻塞。
- 阻塞队列是线程安全的,主要用在生产者消费者场景。
3.1.2、被阻塞的情况
- 当队列满了的时候进行入队列操作
- 当队列为空时进行出队列操作
3.2、阻塞队列的四套方法
BlockingQueue提供了四套方法,分别来进行插入、移除、检查。每套方法在不能立刻执行时都有不同的反应。

- Throws Exceptions :如果不能立即执行就抛出异常。
- Special Value:如果不能立即执行就返回一个特殊的值。
- Blocks:如果不能立即执行就阻塞
- Times Out:如果不能立即执行就阻塞一段时间,如果过了设定时间还没有被执行,则返回一个值
3.3、BlockingQueue的实现类
3.3.1、ArrayBlockingQueue
- 有界的阻塞队列,内部实现是数组,容量有限,在其初始化的时候指定容量大小,指定之后不能再变,先进先出。采用FIFO方式存储数据。
3.3.2、DelayQueue
- 阻塞的是内部元素,DelayQueue里面的元素都必须实现一个接口,是juc里面的一个delay的接口,这个接口继承了conterable接口,因为DelayQueue里面的元素需要排序,一般都是按照元素过期的优先级进行排序。
public interface Delayed extends Comparable<Delayed> { long getDelay(TimeUnit unit); }
- 应用场景很多,比如:定时关闭连接、缓存对象、超时处理等多种场景。
- 内部实现是PriorityQueue和ReentrantLock,就是锁和排序。
public class DelayQueue<E extends Delayed> extends AbstractQueue<E> implements BlockingQueue<E> { private final transient ReentrantLock lock = new ReentrantLock(); private final PriorityQueue<E> q = new PriorityQueue<E>(); ... }
3.3.3、LinkedBlockingQueue
- 大小配置可选,如果初始化时指定了一个大小,那么他就是有边界的,不指定就是无边界的,使用了默认的最大的整型值,内部使用的链表,先进先出,最先插入的在尾部,移出的在头部
public LinkedBlockingQueue() { this(Integer.MAX_VALUE);//不指定大小,无边界采用默认值,最大整型值 }
3.3.4、PriorityBlockingQueue
- 有优先级的阻塞队列。
- 没有边界的队列,有排序规则,允许插入空对象。
- 所有插入的对象必须实现conterable接口,队列优先级的排序规则就是按照我们对Comparable接口的实现来指定的。
- 我们可以从PriorityBlockingQueue中获取一个迭代器,但这个迭代器并不保证能按照优先级的顺序进行迭代。
public boolean add(E e) {//添加方法 return offer(e); } public boolean offer(E e) { if (e == null) throw new NullPointerException(); final ReentrantLock lock = this.lock; lock.lock(); int n, cap; Object[] array; while ((n = size) >= (cap = (array = queue).length)) tryGrow(array, cap); try { Comparator<? super E> cmp = comparator;//必须实现Comparator接口 if (cmp == null) siftUpComparable(n, e, array); else siftUpUsingComparator(n, e, array, cmp); size = n + 1; notEmpty.signal(); } finally { lock.unlock(); } return true; }
3.3.5、 SynchronousQueue
- 内部仅允许容纳一个元素,当一个线程插入一个元素后,就会阻塞,除非这个元素被另一个线程消费,因此称他为同步队列,他是一个无界非缓存的队列。
