目录
- 一、Impala
- 1.1 Overview
- 1.2 数据类型
- 1.3 其他
- 1.4 Impala JDBC
- 1.4.1 Pom
- 1.4.2 Code
- 二、Presto
- 2.1 Overview
- 2.2 Presto的基本概念
- 2.3 其他
- 2.3 Presto JDBC
- 2.3.1 Pom
- 2.3.2 Code
一、Impala
Maven项目编写Impala JDBC,使用Scala语言编写代码,如果需要可以自行更改为Java代码。
Impala JDBC 2.0 及更高版本使用的默认端口为 21050,Impala服务器通过此端口接收JDBC连接。确保此端口可用于网络上其他主机通信,例如,防火墙软件是否阻止此端口。如果客户端想使用其他端口连接,请修改Impala 端口号 --hs2_port并重启Impala。
1.1 Overview
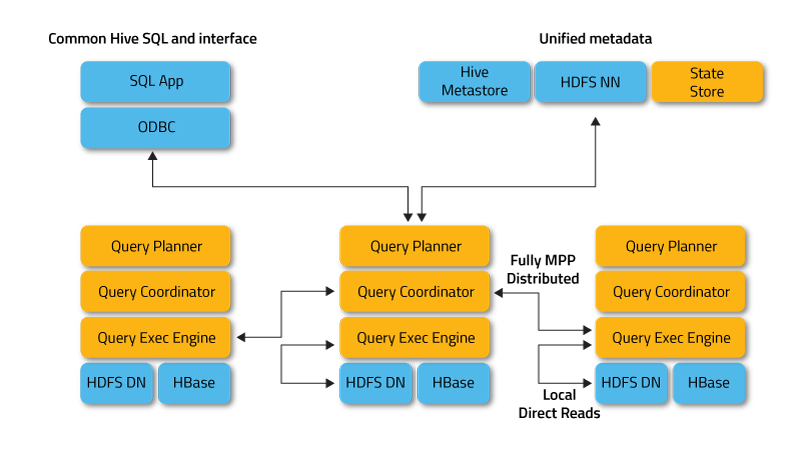
Apache Impala是Apache Hadoop的开源原生分析数据库。多数BI工具都支持Impala,Impala为基于Hadoop上的BI提供了低延迟和高并发性分析查询,即使在多租户环境下,Impala也可以线性扩展。
对于Apache Hive用户,Impala使用相同的元数据和ODBC驱动程序。与Hive一样,Impala支持SQL,因此您不必担心重新造轮子。安装完毕后,在 impala-shell中同步元数据到Impala,执行命令: invalidate metadata; 即可开始使用。
Impala可以提高 Apache Hadoop上SQL查询性能,同时保留了熟悉的用户体验。使用Impala,您可以实时查询数据,无论是存储在HDFS还是Apache HBase中 - 包括SELECT,JOIN和聚合函数。
为了避免延迟,Impala绕过MapReduce,而是通过专门的分布式查询引擎直接访问数据,这个引擎非常类似于商业并行RDBMS中的查询引擎,The result is order-of-magnitude faster performance than Hive, depending on the type of query and configuration.
1.2 数据类型
| 类型 | 条件 | 范围 | 描述 | 句法 |
|---|---|---|---|---|
| ARRAY复杂类型 | 仅适用于2.3或更高版本。文件类型只能为Parquet或ORC格式 | 可以表示任意数量的有序元素的复杂数据类型,元素可以是标量或者另一个复杂类型 | column_name ARRAY < type > |
|
| BIGINT | -9223372036854775808 至9223372036854775807。没有UNSIGNED子类型。 | 8字节整数数据类型 | column_name BIGINT |
|
| BOOLEAN | TRUE或FALSE | 表示单个true / false选择 | column_name BOOLEAN |
|
| CHAR | 仅适用于2.0或更高版本。对于Impala,长度是必需的。CHAR和VARCHAR列中的 所有数据必须使用与UTF-8兼容的字符编码。 | 最大长度为255 | 固定长度的字符类型,必要时尾部用空格填充以达到指定的长度。如果值长于指定的长度,则Impala会截断所有尾部字符。 | column_name CHAR(length) |
| DATE | DATE类型在Impala 3.3及更高版本中可用 | 0000-01-01至9999-12-31 | 使用DATE数据类型存储日期值 | |
| DECIMAL | 仅适用于3.0或更高版本。3.x版本与2.版本有区别,如果继续使用老版本,可设置SET DECIMAL_V2=FALSE。 | -10 ^ 38 +1到10 ^ 38 –1 | 固定尺和精度的数值数据类型 | DECIMAL[(precision[, scale])] |
| DOUBLE | 4.94065645841246544e-324 至 1.79769313486231570e+308 正数或负数 | 双精度浮点数据类型 | column_name DOUBLE |
|
| FLOAT | 1.40129846432481707e-45至3.40282346638528860e+38 正数或负数 | 单精度浮点数据类型 | column_name FLOAT |
|
| INT | 如果整数值太大而无法用INT 表示,请改用 BIGINT | -2147483648 至 2147483647 | 使用的4字节整数数据类型 | column_name INT |
| MAP复杂类型 | 仅适用于2.3或更高版本。在后台,该MAP类型的实现方式与该ARRAY类型类似 。Impala不会对KEY值施加任何唯一性约束 | 表示任意一组键值对的复杂数据类型,key部分是一个标量类型,value部分可以是标量或另一复杂类型 | column_name MAP < primitive_type, type > |
|
| REAL | DOUBLE数据类型 的别名 | column_name REAL |
||
| SMALLINT | 如果整数值太大而不能用SMALLINT表示,请改用 INT。 | -32768 至 32767 ,没有UNSIGNED子类型 | 使用的2字节整数数据类型 | column_name SMALLINT |
| STRING | 在32 KB或更少的字符串上运行的查询将可靠地工作,并且不会造成严重的性能或内存问题 | 对STRING的大小和一行总大小的硬性限制是2 GB;STRING写入Parquet文件时 限制为1 GB。 | 字符串 | column_name STRING |
| STRUCT复杂类型 | 仅适用于2.3或更高版本。只能在具有Parquet或ORC文件格式的表或分区中使用。具有此数据类型的列不能用作分区表中的分区键列。 | 任何复杂类型(包括任何嵌套类型的声明)的列定义的最大长度为4000个字符。 | 代表单个项目的多个字段。经常用作ARRAY 或MAP的VALUE部分的元素类型 | column_name STRUCT < name : type [COMMENT 'comment_string'], ... > |
| TIMESTAMP | 1400-01-01至9999-12-31 | TIMESTAMP数据类型保存日期和时间的值。可以将其分解为年,月,日,小时,分钟和秒字段,但是由于没有可用的时区信息,因此它不对应于任何特定的时间点。更多关于日期函数请查看 Time Functions | column_name TIMESTAMP |
|
| TINYINT | 如果整数值太大而无法用TINYINT表示,请改用SMALLINT | -128 至127。没有UNSIGNED子类型 | 使用的1字节整数数据类型 | column_name TINYINT |
| VARCHAR | 仅适用于2.0或更高版本 | 您可以指定的最大长度为65535。 | 可变长度字符类型,在处理过程中必要时将其截断以适合指定的长度。 | column_name VARCHAR(max_length) |
| 复杂类型 | 仅适用于2.3或更高版本 | 复杂类型(也称为嵌套类型)使您可以在单个行/列位置中表示多个数据值 |
1.3 其他
- Impala其他启动选项请查看 Modifying Impala Startup Options
- CDH Impala配置属性 Impala Properties in CDH 6.1.0
- Impala官方文档 Impala Doucmentation | 最新版文档: HTML Documentation for Impala 3.2
- Impala 结构详细信息可查看 “Impala: A Modern, Open-Source SQL Engine for Hadoop”
1.4 Impala JDBC
1.4.1 Pom
只列出重要部分
<!-- *** Scala *** -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<!-- scala-compiler -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-compiler</artifactId>
<version>2.11.8</version>
</dependency>
<!-- scala-reflect -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-reflect</artifactId>
<version>2.11.8</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.cloudera.impala/jdbc -->
<dependency>
<groupId>com.cloudera.impala</groupId>
<artifactId>jdbc</artifactId>
<version>2.5.31</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-service -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-service</artifactId>
<version>1.1.1</version>
<exclusions>
<exclusion>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.thrift/libthrift -->
<dependency>
<groupId>org.apache.thrift</groupId>
<artifactId>libthrift</artifactId>
<version>0.12.0</version>
</dependency>
1.4.2 Code
package yore
import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet}
/**
* Impala JDBC
*
* Created by yore on 2019/5/20 06:46
*/
object ImpalaJDBCClient {
private[yore] val JDBC_DRIVER: String = "com.cloudera.impala.jdbc41.Driver"
// 端口可以查看:Impala 配置项 hs2_port
private[yore] val URL = "jdbc:impala://cdh3:21050/kudu_test"
def main(args: Array[String]): Unit = {
var conn: Connection = null
var ps: PreparedStatement = null
try{
Class.forName(JDBC_DRIVER)
conn = DriverManager.getConnection(URL)
var sql = "show tables"
sql = "select * from tag_5 limit 10"
ps = conn.prepareStatement(sql)
val result: ResultSet = ps.executeQuery()
val start = System.currentTimeMillis()
while (result.next()){
for(pos <- 1 to result.getMetaData.getColumnCount){
print(result.getObject(pos) + "\t")
}
println()
}
val end = System.currentTimeMillis()
println("-"*26 + s" Impala\n\t共花费:${(end - start).toDouble/1000} 秒")
}catch {
case e: Exception => e.printStackTrace()
}finally {
if(ps != null) ps.close()
if(conn != null) conn.close()
println("-"*26)
}
}
}
二、Presto
2.1 Overview
Presto 是一个在 Facebook 主持下运营的开源项目。Presto是一种旨在使用分布式查询有效查询大量数据的工具,Presto是专门为大数据实时查询计算呢而设计和开发的产品,其为基于 Java 开发的,对使用者和开发者而言易于学习。
Presto有时被社区的许多成员称为数据库,官方也强调 Presto 不是通用关系数据库,它不是 MySQL,PostgreSQL 或 Oracle 等数据库的替代品,Presto 不是为处理在线事务处理(OLTP)而设计的。
如果您使用太字节或数PB的数据,您可能会使用与 Hadoop 和 HDFS 交互的工具。Presto 被设计为使用 MapReduce 作业(如Hive或Pig)管道查询 HDFS 的工具的替代方案,但 Presto不限于访问HDFS。
Presto 可以并且已经扩展到可以在不同类型的数据源上运行,包括传统的关系数据库和其他数据源像 Cassandra。Presto旨在处理数据仓库和分析:数据分析,聚合大量数据和生成报告。这些工作负载通常归类为在线分析处理(OLAP)。
2.2 Presto的基本概念
-
Coordinator
Presto coordinator 是负责解析语句、查询计划和管理 Presto Worker 节点的服务器。它是 Presto 安装的“大脑”,也是客户端连接以提交语句以供执行的节点。
每个 Presto 安装必须有一个 Presto Coordinator 和一个或多个 Presto Worker。出于开发或测试目的,可以将单个 Presto 实例配置作为这两个角色。
协调器跟踪每个 Worker 的活动并协调查询的执行。Coordinator 创建一个涉及一系列阶段的查询的逻辑模型,然后将其转换为在 Presto 工作集群上运行的一系列连接任务。
Coordinator 使用 REST API 与 Worker 和客户进行通信。 -
Worker
Presto worker 是 Presto 安装中的负责执行任务和处理数据服务器。Worker 从连接器获取数据并相互交换中间数据。Coordinator 负责从工人那里获取结果并将最终结果返回给客户。
当Presto工作进程启动时,它会将自己通告给 Coordinator 中的发现服务器,这使 Presto Coordinator可以执行任务。
Worker 使用 REST API 与其他 Worker 和 Presto Coordinator 进行通信。 -
Connector
Connector 将 Presto 适配到数据源,如Hive或关系数据库。您可以将 Connector 视为与数据库驱动程序相同的方式。它是 Presto SPI 的一个实现,它允许 Presto 使用标准 API 与资源进行交互。
Presto 包含几个内置连接器:一个用于 JMX 的连接器 ,一个提供对内置系统表的访问的系统连接器,一个Hive连接器和一个用于提供 TPC-H 基准数据的TPCH连接器。
许多第三方开发人员都提供了连接器,以便 Presto 可以访问各种数据源中的数据。每个 Catalog 都与特定 Connector 相关联。如果检查 Catalog 配置文件,您将看到每个都包含强制属性 connector.name,
Catalog 使用该属性为给定 catalog 创建 Connector。可以让多个 Catalog 使用相同的 Connector 来访问类似数据库的两个不同实例。例如,如果您有两个Hive集群,则可以在单个 Presto 集群中配置两个 Catalog,
这两个 Catalog 都使用 Hive Connector,允许您查询来自两个 Hive 集群的数据(即使在同一SQL查询中)。 -
Catalog
Presto Catalog 包含 Schemas,并通过 Connector 引用数据源。例如,您可以配置 JMX catalog 以通过 JMX Connector 提供对 JMX 信息的访问。
在 Presto 中运行 SQL 语句时,您将针对一个或多个 Catalog 运行它。Catalog 的其他示例包括用于连接到 Hive 数据源的 Hive 目录。
当在 Presto 中寻址一个表时,全限定的表名始终以 Catalog 为根。例如,一个全限定的表名称hive.test_data.test将引用 Hive catalog中 test_data库中 test表。
Catalog 在存储在 Presto 配置目录中的属性文件中定义。 -
Schema
Schema 是组织表的一种方式。Schema 和 Catalog 一起定义了一组可以查询的表。使用 Presto 访问 Hive 或 MySQL 等关系数据库时,Schema 会转换为目标数据库中的相同概念。
其他类型的 Connector 可以选择以对底层数据源有意义的方式将表组织成 Schema。 -
Table
表是一组无序行,它们被组织成具有类型的命名列。这与任何关系数据库中的相同。从源数据到表的映射由 Connector 定义。 -
Statement
Presto 执行与 ANSI 兼容的 SQL 语句。当 Presto 文档引用语句时,它指的是 ANSI SQL 标准中定义的语句,它由子句(Clauses),表达式(Expression)和断言(Predicate)组成。
Presto 为什么将语句(Statment)和查询(Query)概念分开呢?这是必要的,因为在 Presto 中,Statment 只是引用 SQL 语句的文本表示。执行语句时,Presto 会创建一个查询以及一个查询计划,然后该查询计划将分布在一系列 Presto Worker 进程中。 -
Query
当 Presto 解析语句时,它会将其转换为查询并创建分布式查询计划,然后将其实现为在 Presto Worker 进程上运行的一系列互连阶段。在 Presto 中检索有关查询的信息时,您会收到生成结果集以响应语句所涉及的每个组件的快照。
语句和查询之间的区别很简单。语句可以被认为是传递给 Presto 的 SQL 文本,而查询是指为实现该语句而实例化的配置和组件。查询包含 stages, tasks, splits, connectors以及协同工作以生成结果的其他组件和数据源。 -
Stage
当 Presto 执行查询时,它会通过将执行分解为具有层级关系的多个 Stage。例如,如果 Presto 需要聚合存储在 Hive 中的10亿行的数据,则可以通过创建根 State 来聚合其他几个阶段的输出,所有这些阶段都旨在实现分布式查询计划的不同部分。
包含查询的层级关系结构类似于树。每个查询都有一个根 Stage,负责聚合其他 Stage 的输出。阶段是 Coordinator 用于建模分布式查询计划的 Stage,但阶段本身不在 Presto Worker 进程上运行。 -
Task
如上一部分所述,Stage 为分布式查询计划的特定部分建模,但 Stage 本身不在 Presto Worker 进程上执行。要了解 Stage 的执行方式,您需要了解 Stage 是通过 Presto Worker 网络分发的一系列任务来实现的。
任务是 Presto 架构中的“work horse”,因为分布式查询计划被解构为一系列 Stage,然后将这些 Stage 转换为任务,然后执行或处理 split。Presto 任务具有输入和输出,正如一个 Stage 可以通过一系列任务并行执行,任务与一系列驱动程序并行执行。 -
Split
任务对拆分进行操作,拆分是较大数据集的一部分。分布式查询计划的最低级别的 Stage 通过 Connector 的拆分检索数据,而分布式查询计划的更高级别的中间阶段从其他阶段检索数据。
当 Presto 正在安排查询时,Coordinator 将查询 Connector 以获取可用于表的所有拆分的列表。Coordinator 跟踪哪些计算机正在运行哪些任务以及哪些任务正在处理哪些拆分。 -
Driver
任务包含一个或多个并行 Driver。Driver 对数据进行操作并组合运算符以生成输出,然后由任务聚合,然后将其传递到另一个 Stage 中的另一个任务。
Driver 是一系列操作符实例,或者您可以将 Driver 视为内存中的一组物理运算符。它是 Presto 架构中最低级别的并行性。Driver 有一个输入和一个输出。 -
Operator
Operator消费、转换和生成数据。例如,表扫描从 Connector 获取数据并生成可由其他运算符使用的数据,并且过滤器运算符通过在输入数据上应用来使用 Predicate 数据并生成子集。 -
Exchange
交换在 Presto 节点之间传输数据以用于查询的不同阶段。任务使用交换客户端将数据生成到输出缓冲区并使用其他任务中的数据。
2.3 其他
- 官网
- 项目源码 - GitHub
- Presto 的安装官方文档
- 其他可参考 官方文档
2.4 Presto JDBC
如果查看
2.4.1 Pom
<dependencies>
<!-- https://mvnrepository.com/artifact/io.prestosql/presto-jdbc -->
<dependency>
<groupId>io.prestosql</groupId>
<artifactId>presto-jdbc</artifactId>
<version>314</version>
</dependency>
</dependencies>
2.4.2 Code
package yore;
import io.prestosql.jdbc.PrestoConnection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.time.ZoneId;
import java.util.Properties;
import java.util.TimeZone;
/**
* JDBC访问 Presto
* @see <a href="https://prestodb.github.io/docs/current/installation/jdbc.html">JDBC Driver<a/><br/>
*
* Created by yore on 2019/5/8 13:10
*/
public class PrestoJDBCClient {
static final String JDBC_DRIVER = "io.prestosql.jdbc.PrestoDriver";
static final String URL = "jdbc:presto://cdh6:8080/kudu/default";
public static void main(String[] args) {
// @see <a href="https://en.wikipedia.org/wiki/List_of_tz_database_time_zones">List of tz database time zones</a>
// 设置时区,这里必须要设置 map.put("CTT", "Asia/Shanghai");
TimeZone.setDefault(TimeZone.getTimeZone(ZoneId.SHORT_IDS.get("CTT")));
Properties properties = new Properties();
properties.setProperty("user", "presto-user");
properties.setProperty("SSL", "false");
PrestoConnection conn = null;
PreparedStatement ps = null;
try {
Class.forName(JDBC_DRIVER);
conn = (PrestoConnection)DriverManager.getConnection(URL, properties);
String sql = "show tables";
sql = "select * from tag_5 limit 10";
ps = conn.prepareStatement(sql);
ResultSet result = ps.executeQuery();
long start = System.currentTimeMillis();
while (result.next()){
for(int pos=1; pos< result.getMetaData().getColumnCount(); pos++){
System.out.print(result.getObject(pos) + "\t");
}
System.out.println();
}
long end = System.currentTimeMillis();
System.out.println("--------------------------Presto" );
System.out.println("\\t共花费:" + (double) (end - start) /1000 + "秒");
}catch (Exception e){
e.printStackTrace();
}finally {
if(ps != null) {
try {
ps.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(conn != null) {
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
System.out.println("--------------------------" );
}
}
}
最后我的笔记
其他关于Presot的可以查看 我的另一篇博客
End
