机器配置:
hadoop集群有一个master和两个slave
hadoop的安装目录为/root/hadoop-2.5.2
利用hadoop自带的wordcount计算词数:
1、启动hadoop集群
命令:source ~/.bash_profile


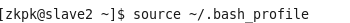
2、进入hadoop安装目录
命令:cd ~/hadoop-2.5.2
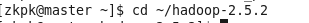
3、创建hdfs数据目录:hadoop fs -mkdir /input
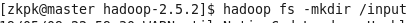
4、查看hdfs根目录下文件
命令:hadoop fs -ls /
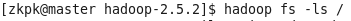
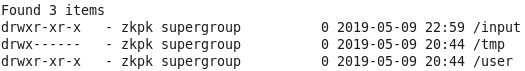
5、把在/root/hadoop-2.5.2目录下的LICENSE.txt放到hdfs的/input文件夹里
命令:hadoop fs -put LICENSE.txt /input
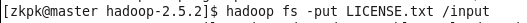
6、查看是否移入成功
命令:hadoop fs -ls /input
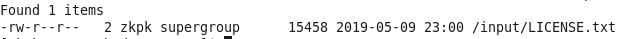
7、进入jar包目录
命令:cd ./share/hadoop/mapreduce
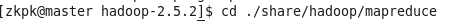
8、通过hadoop自带示例程序wordcount计算词数:
命令:hadoop jar hadoop-mapreduce-examples-2.5.2.jar wordcount /input /output
其中:hadoop-mapreduce-examples-2.5.2.jar为使用的jar包,wordcount 为jar中Main入口类的名字,/input为hdfs下输入文件的目录,/output为输出文件的目录,且该目录在命令执行时会创建(之前不能有)
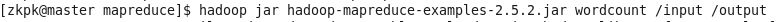
9、查看此时hdfs根目录
命令:hadoop fs -ls /

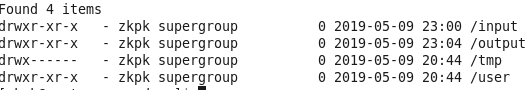
10、查看output下的文件
命令:hadoop fs -ls /output

11、打开part-r-00000,里面存放着词频统计的结果
命令:hadoop fs -cat /output/part-r-00000


自己编写程序使用MapReduce
例如:利用IDEA自己编写程序,实现MapReduce
hadoop安装在虚拟机的/opt/hadoop-2.9.2中
1、在IDEA中File->New->Project创建新项目

2、选择Maven项目,然后点击Next

3、GroupId为项目包名,ArtifactId为程序名,Version为版本


4、Project name为项目名称,Project location为项目位置
5、然后点击Finish。跳出New Project后,选择New Window
6、然后在电脑中任意路径下(尽量不要有中文),放入以下5个jar包

7、将这5个jar包导入到项目中
8、在java下创建以下3个类
WordCount.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true) ;
//System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
TokenizerMapper.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class TokenizerMapper extends Mapper<Object, Text,Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
//由于该例子未用到key的参数,所以该处key的类型就简单指定为Object
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
IntSumReducer.java
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class IntSumReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}

9、然后将这个项目打包为jar包
10、然后在虚拟机的/opt/hadoop-2.9.2目录下创建一个目录job,利用Xftp将这个jar包从主机放到虚拟机上,如放在虚拟机的/opt/hadoop-2.9.2/job目录下(可以放在其他目录下)
[root@hadoop01 hadoop-2.9.2]# mkdir job

11、在/opt/hadoop-2.9.2/job目录下,创建一个input_data.txt,向其中输入3个harry和1个Potter,作为要统计词频的文本文件
[root@hadoop01 hadoop-2.9.2]# vi job/input_data.txt
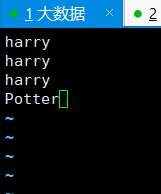
12、在hdfs上创建目录/test,将input_data.txt传上去
[root@hadoop01 hadoop-2.9.2]# hadoop fs -mkdir /test
[root@hadoop01 hadoop-2.9.2]# hadoop fs -put job/input_data.txt /test
13、利用之前生成的MyHadoopTest.jar这个jar包实现词频统计
其中:job/MyHadoopTest.jar为我们生成的jar包,因为放在/opt/hadoop-2.9.2/job下,所以前面加job/
WordCount为打包的项目的Main类的名字,/test为hdfs中输入文件的所在目录,/testoutput为输出文件所在目录,该目录执行完语句后创建
[root@hadoop01 hadoop-2.9.2]# hadoop jar job/MyHadoopTest.jar WordCount /test /testoutput
14、查看hdfs上/testoutput中的文件,其中part-r-00000为输出结果
[root@hadoop01 hadoop-2.9.2]# hadoop fs -ls /testoutput

15、查看part-r-00000的内容,为文本统计的内容
[root@hadoop01 hadoop-2.9.2]# hadoop fs -cat /testoutput/part-r-00000

