大纲
0x1. 分析的思路和方法
0x2. 搭建实验环境
0x3. 探索mount的过程
0x4. 对架构的思考
0x1. 分析的思路和方法
面对复杂且庞大的项目,如何高效地分析自己感兴趣的模块以达到充分理解的目的,对很多人来说都充满了挑战。我在这里提供一种思路供大家参考:
在理解整体逻辑的基础上,聚焦关键点,忽略大多数主题无关的细节。
这篇文章将会详细阐述这个思路的实践方式。
0x2. 搭建实验环境
搭建实验环境的目的,是要将Linux内核运行起来,运行起来之后我们可以输出日志信息,或人为地制造crash以让系统输出调用栈,调用栈和日志信息可以直观地反映出系统的执行流程,执行流程即是程序的整体脉络。下面你会看到,将系统运行起来是一种探索整体逻辑的有效手段。
0x21. 内核版本与运行平台
内核版本:goldfish3.4
运行平台:qemu
0x22. 文件系统类型
hellofs:https://github.com/accelazh/hellofs
hellofs是acelazh根据开源项目改造的一个文件系统,可以说是一个最小功能的文件系统。选择这个文件系统的原因,主要是因为其结构简单,可以让我们聚焦在文件系统挂载的关键流程上。
0x23. hellofs的移植
hellofs的目标平台是x86_64,而我们的运行平台是arm,进行一些简单的改造即可移植到goldfish。
0x3. 对mount的探索
0x31. 绘制UML序列图
你可能以为我在开玩笑,因为我一行代码都没有分析,上来就要绘制UML序列图!是的,我将主要通过动态的方式来绘制UML序列图,以整体上理解mount的执行流程。下面请允许我开始我的表演!
0x311. 制造crash

在hellofs文件系统源码中加入一个BUG(需要保证mount过程中内核发生crash),比如hellofs_fill_super(如果没有触发到那就多加几个函数),然后编译安装模块,接着开始挂载:
mount -o loop,owner,group,users -t hellofs /data/local/tmp/hello.img /sdcard/mnt
接下来内核发生了crash,从crash日志中,我们提取到如下函数调用栈:
(hellofs_fill_super [hellofs]) from (mount_bdev) (mount_bdev) from
(hellofs_mount [hellofs]) (hellofs_mount [hellofs]) from (mount_fs)
(mount_fs from (vfs_kern_mount) (vfs_kern_mount) from (do_mount)
(do_mount) from (sys_mount) (sys_mount) from (ret_fast_syscall)
0x312. 补全调用栈
因为hellofs的体量相当小,所以我在其中的每个函数入口处均加入了一个日志打印宏,再次运行之后,得到如下信息:
drivers/…/…/hellofs/super.c(58)-<hellofs_mount>:
drivers/…/…/hellofs/super.c(10)-<hellofs_fill_super>:
drivers/…/…/hellofs/inode.c(87)-<hellofs_get_hellofs_inode>:
drivers/…/…/hellofs/inode.c(22)-<hellofs_fill_inode>: hellofs is
succesfully mounted on: /dev/block/loop0
0x333. 绘制UML序列图
有了前两步铺垫,我们能够轻易得到mount的内核执行序列图:
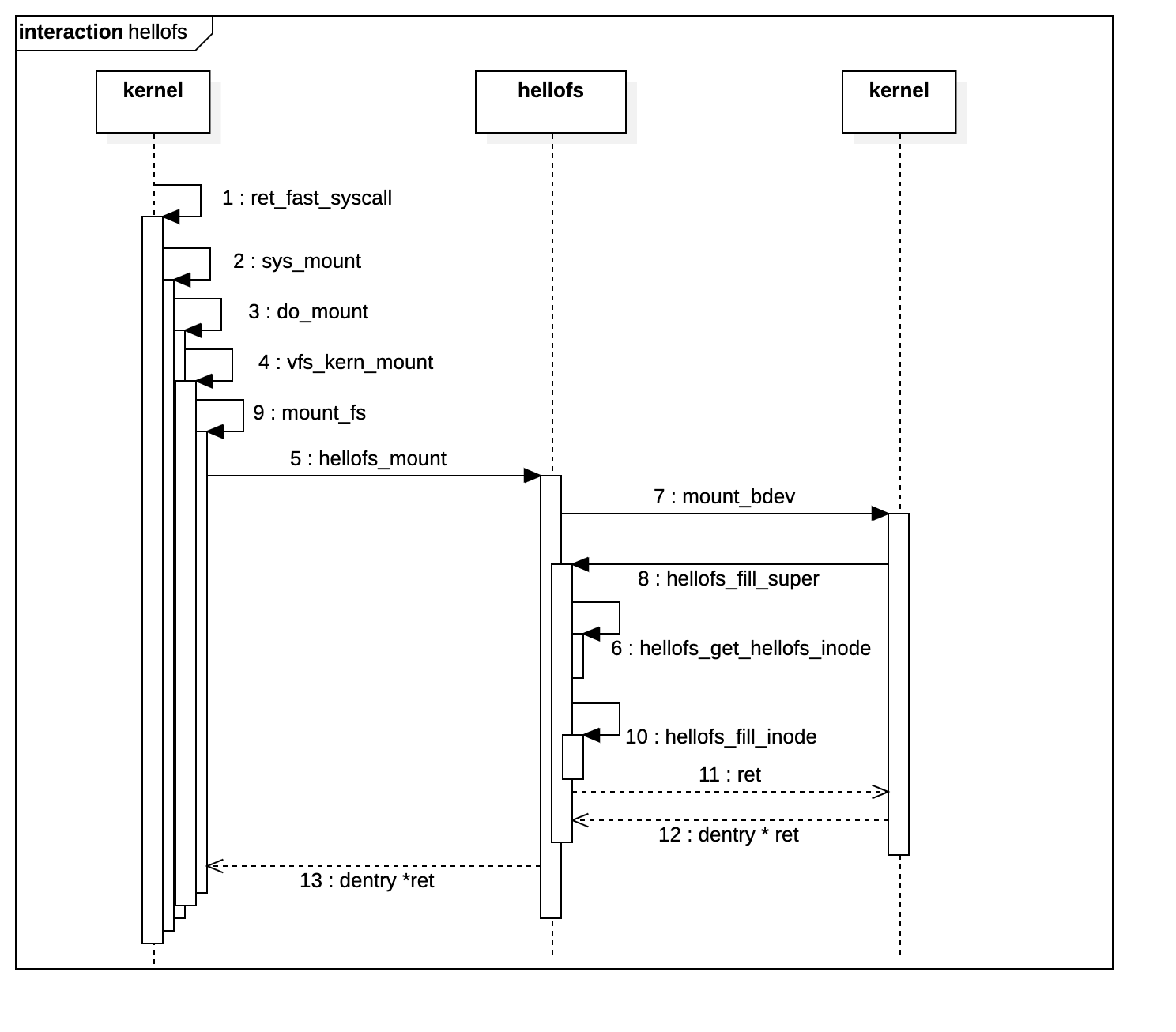
根据UML序列图,我们可以清楚地看到hellofs为kernel提供了两个接口,一个是hellofs_mount,一个是hellofs_fill_super。
0x32. 理解mount的流程
整个UML序列图可以粗略地总结为如下三个要点:
- 用户空间执行mount命令,经由系统调用传递到内核,内核通过参数识别出需要挂载的文件系统为hellofs,hellofs的挂载接口hellofs_mount被调用;
- hellofs_mount调用的最终结果,是返回给内核dentry指针,dentry指针即是已经挂载好的文件系统入口;
- hellofs挂载的主要逻辑,实际上还是由内核自己完成,即mount_bdev函数完成了主要的挂载任务,只不过mount_bdev在完成挂载任务的过程中,仍需要hellofs执行一些协助工作,这个工作就是hellofs_fill_super。
综上步骤,我们可以再次提练挂载的关键信息:
在hellofs_fill_super函数的帮助下,内核mount_bdev函数完成了主要的挂载工作。
我们可以进一步地猜想,是不是所有类型的文件系统挂载,都是通过mount_bdev来完成的呢?为了验证这一猜想,我绘制了内核中mount_bdev的调用关系图:
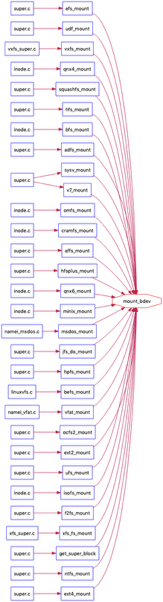
我们可以直观地看到,很多文件系统的挂载,都是通过mount_bdev函数来完成的。
最后只剩下两个问题:
- mount_bdev为什么需要hellofs_fill_super的协助
- mount_bdev是如何完成挂载的
关于第一个问题,通过简单的推理即可达到初步理解其原理的目的,我的推理如下:
内核需要将hellofs挂载到当前目录树下,但它并不知道hellofs的格式、属性以及函数行为,所以它需要hellofs提供一个接口,来告诉它hellofs的格式、属性和函数行为是怎样的,比如块的大小和数量。
接着,我们继续探讨第二个问题,mount_bdev究竟是如何完成挂载的呢?要搞清楚这个问题,我们必须从mount_bdev的源码着手了。
struct dentry *mount_bdev(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data,
int (*fill_super)(struct super_block *, void *, int))
{
struct block_device *bdev;
struct super_block *s;
fmode_t mode = FMODE_READ | FMODE_EXCL;
int error = 0;
……
bdev = blkdev_get_by_path(dev_name, mode, fs_type);
……
s = sget(fs_type, test_bdev_super, set_bdev_super, flags | MS_NOSEC,
bdev);
char b[BDEVNAME_SIZE];
s->s_mode = mode;
strlcpy(s->s_id, bdevname(bdev, b), sizeof(s->s_id));
sb_set_blocksize(s, block_size(bdev));
error = fill_super(s, data, flags & MS_SILENT ? 1 : 0);
if (error) {
deactivate_locked_super(s);
goto error;
}
s->s_flags |= MS_ACTIVE;
bdev->bd_super = s;
return dget(s->s_root);
……
}
我们将一些错误和同步处理相关的代码去掉,仅关注mount的主要逻辑,要点如下:
- 获取被挂载设备的指针bdev;
- 申请一个super_block结构体对象,并作了一些简单的初始化,比如将bdev关联到super_block;
- 调用fill_super进一步填充这个对象,最后返回super_block的s_root字段。
调用结束之后,我们即获取了hellofs文件系统的入口——s_root,这个入口即指向/sdcard/mnt。但故事并没有结束,因为我们还有一些疑问要解决。
到目前为止,我们知道了super_block是如何同块设备关联起来的,但是我们还没看到文件系统的入口在哪里初始化,以及文件系统的函数行为是怎么被关联到super_block的。
进一步研究,我们需要看看hellofs_fill_super的实现逻辑。
该函数的主要逻辑包括:
static int hellofs_fill_super(struct super_block *sb, void *data, int silent) {
struct inode *root_inode;
struct hellofs_inode *root_hellofs_inode;
struct buffer_head *bh;
struct hellofs_superblock *hellofs_sb;
int ret = 0;
bh = sb_bread(sb, HELLOFS_SUPERBLOCK_BLOCK_NO);
BUG_ON(!bh);
hellofs_sb = (struct hellofs_superblock *)bh->b_data;
……
sb->s_magic = hellofs_sb->magic;
sb->s_fs_info = hellofs_sb;
sb->s_maxbytes = hellofs_sb->blocksize;
sb->s_op = &hellofs_sb_ops;
root_hellofs_inode = hellofs_get_hellofs_inode(sb, HELLOFS_ROOTDIR_INODE_NO);
root_inode = new_inode(sb);
……
hellofs_fill_inode(sb, root_inode, root_hellofs_inode);
inode_init_owner(root_inode, NULL, root_inode->i_mode);
sb->s_root = d_make_root(root_inode);
……
return ret;
}
- 从块设备读取hellofs_superblock结构的数据,以初始化该结构体对象,最终传递给super_block结构对象;
- 将hellofs_superblock的操作函数赋给super_block对象;
- 分配并填充root_inode,赋给super_block结构体对象的s_root字段。
至此,super_block结构体对象已经成功关联了被挂载的块设备、hellofs_superblock的操作函数、以及文件系统根目录的内核表示对象root_inode。
我们将这部分内容稍微总结一下:
- 从设计模式的角度来看,super_block结构实际上属于Linux内核提供的文件系统适配接口,开发者将自己的super block——hellofs_superblock与super_block进行适配,以实现自己的文件系统与内核的挂接;
- 挂接成功之后,用户空间传递下来的所有请求,都经由super_block结构对象转发给hellofs_superblock进行处理。
从这个角度来看,我们发现mount过程的技术本质就是对super_block的各个字段进行填充。
既然super_block这么重要,我们就简单看看它的定义:
struct super_block {
struct list_head s_list; /* Keep this first */
dev_t s_dev; /* search index; _not_ kdev_t */
unsigned char s_blocksize_bits;
unsigned long s_blocksize;
loff_t s_maxbytes; /* Max file size */
struct file_system_type *s_type;
const struct super_operations *s_op;
const struct dquot_operations *dq_op;
const struct quotactl_ops *s_qcop;
const struct export_operations *s_export_op;
unsigned long s_magic;
struct dentry *s_root;
struct rw_semaphore s_umount;
int s_count;
atomic_t s_active;
……
const struct xattr_handler **s_xattr;
struct hlist_bl_head s_anon; /* anonymous dentries for (nfs) exporting */
struct list_head s_mounts; /* list of mounts; _not_ for fs use */
struct block_device *s_bdev;
struct backing_dev_info *s_bdi;
struct mtd_info *s_mtd;
struct hlist_node s_instances;
unsigned int s_quota_types; /* Bitmask of supported quota types */
struct quota_info s_dquot; /* Diskquota specific options */
struct sb_writers s_writers;
char s_id[32]; /* Informational name */
u8 s_uuid[16]; /* UUID */
void *s_fs_info; /* Filesystem private info */
……
const struct dentry_operations *s_d_op; /* default d_op for dentries */
……
struct list_head s_inodes; /* all inodes */
};
可以看到,super_block包含了一个文件系统的方方面面,包括对应的块设备、根目录、所有的inode节点、文件系统的操作函数指针等等。
最后,我们进一步总结出如下观点:
实现自定义文件系统的主要任务,就是对super_block结构进行适配。
0x4. 对架构的思考
Linux很强大的一个地方就在于它支持几乎所有文件系统,从这次mount的探索过程中,我们可以窥见其实现这种强大支持的原理:
- 由内核提供文件系统访问的接口,但不提供具体的实现,也不需要关心具体的实现;
- 不同的文件系统根据内核定义的接口自由地扩展。
进一步总结,即是面向接口编程的精髓:
高层模块定义接口,不关心具体实现;底层模块依赖于接口,根据接口完成功能的扩展。
