原始代码
//test.c
#include <stdio.h>
#define Pi 3.14
void hotPot() {
printf("I want to eat hot pot!\n");
}
int main() {
printf("Hello world.\n");
float a = Pi + 3;
hotPot();
return 0;
}
预处理阶段
- 把头文件编译进去
- 把宏替换
gcc -E test.c -o test.i
代码
// ....前面是编译进来的头文件,省略
# 868 "/usr/include/stdio.h" 3 4
# 2 "test.c" 2
# 5 "test.c"
void hotPot() {
printf("I want to eat hot pot!\n");
}
int main() {
printf("Hello world.\n");
float a = 3.14 + 3;
hotPot();
return 0;
}
可以看出来,宏Pi被替换成了3.14。
编译
- 将前面的代码转换为汇编代码。
gcc -S test.i -o test.s
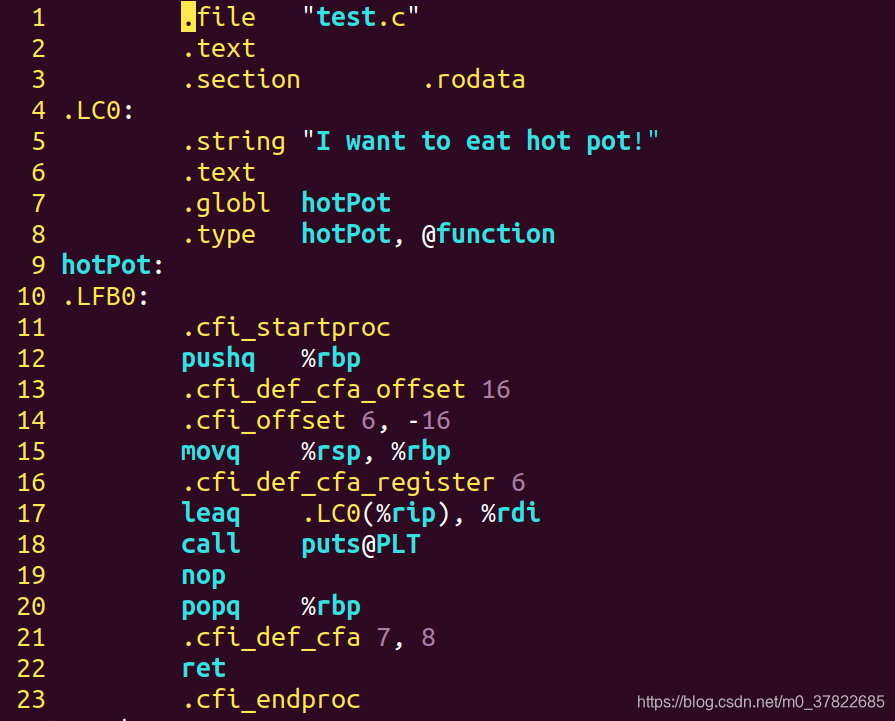
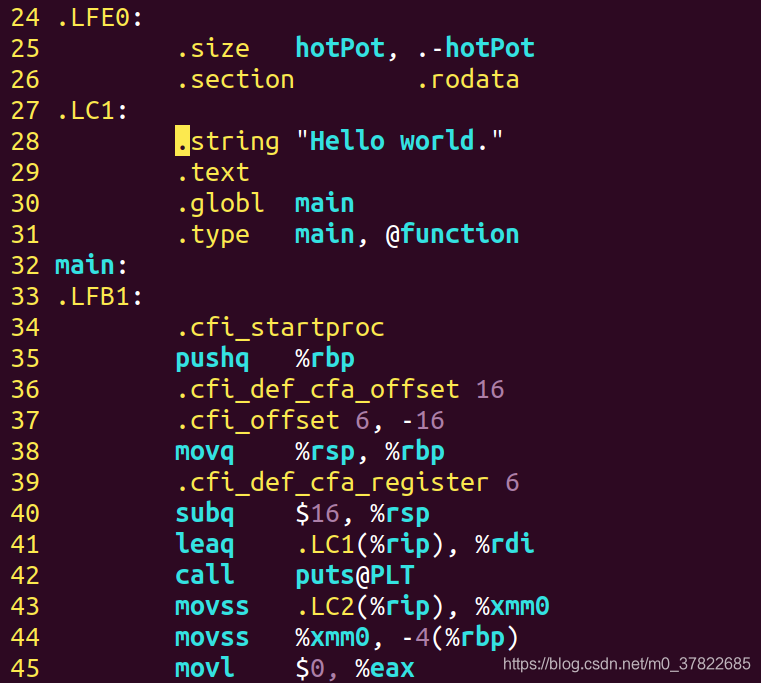
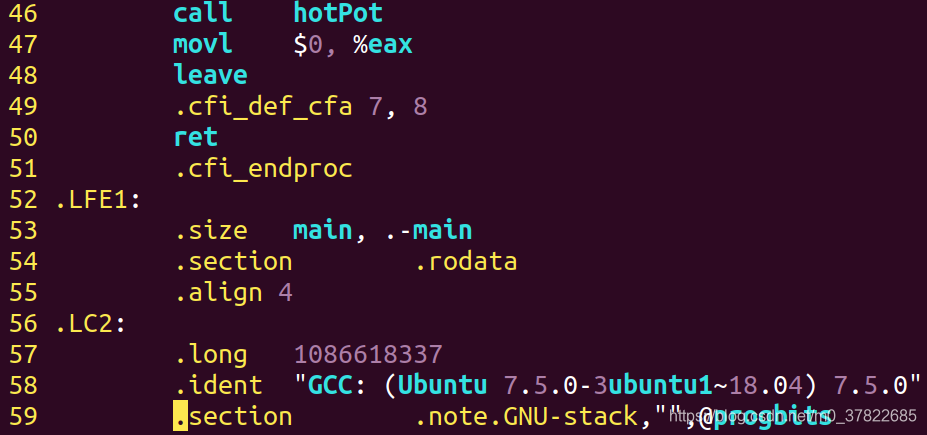
汇编
- 将汇编代码转换为二进制机器码。
gcc -c test.s -o test.o
链接
- 将汇编生成的OBJ文件、系统库的OBJ文件、库文件链接起来,最终生成可执行程序。
gcc test.o -o test

最近学习操作系统,有一些关于链接的感想。为什么要有链接的过程。假如模块A调用了模块B,它们分别都有自己的地址空间,但是A不知道B的地址。多个模块和用到的函数库链接起来,排成一个线性的序列,排好之后就知道跳转的地址在哪了。
