存储引擎
存储引擎是指定在表之上的,即一个库中的每一个表都可以指定专用的存储引擎 。
不管表采用什么样的存储引擎,都会在数据区,产生对应的一个frm文件(表结构定义描述文件) 。在新版本中frm文件已经被mysql舍弃
CSV存储引擎
为其添加索引时报错Too many keys specified; max 0 keys allowed
为其添加默认为null的列时 提示The storage engine for the table doesn't support nullable columns
因此,CSV引擎的表不能定义索引,列定义必须是NOT NULL,不能设置自增列
CSV数据的存储是用,隔开,可直接编辑CSV文件进行数据的插入或删除;编辑之后,要生效使用flush table xxx;
Create Table: CREATE TABLE `csv_name` (
`name` varchar(10) NOT NULL,
`age` tinyint(4) NOT NULL
) ENGINE=CSV DEFAULT CHARSET=utf8mb4 COMMENT='csv 测试'
//插入操作
insert into csv_name values("wojiushiwo",2);
insert into csv_name values("wojiushiwo",4);
在mysql的目录/usr/local/mysql/data/数据库名在有该数据文件存在csv_name.csv存在

通过vi打开文件是这样的,与查询的结果一致。可以在这个文件中修改数据,如添加上一行数据

mysql>flush table csv_name;//立刻刷新
mysql>select * from csv_name;
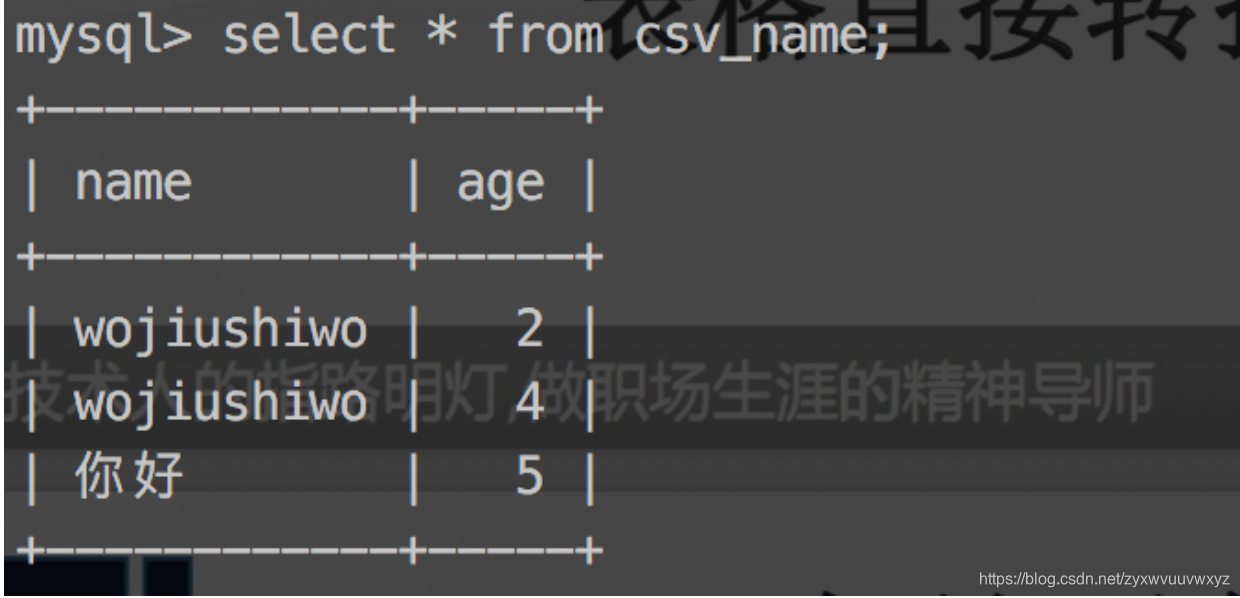
因此可以说安全性不太高
应用场景:
表格的快速导入导出
表格直接转换成CSV
Archive存储引擎
压缩协议进行数据的存储,数据存储为ARZ文件格式
特点:
- 只允许insert和select两种操作
- 只允许自增ID列建立索引
- 支持行级锁
- 不支持事物
- 数据占用磁盘少
应用场景:
- 日志系统
- 大量的设备数据采集
对压缩存储做了实验:
CREATE DEFINER = `root`@`localhost` PROCEDURE `study`.`insert`()
LANGUAGE SQL
NOT DETERMINISTIC
CONTAINS SQL
SQL SECURITY DEFINER
COMMENT ''
begin
declare index_num int DEFAULT 0;
while index_num<100000
do
insert into archive_name(name,age) values("wojiushiwo",20);
insert into innodb_name(name,age) values("wojiushiwo",20);
set index_num=index_num+1;
end while;
end
采用Archive引擎和Innodb引擎分别插入100000条数据,数据文件中innodb_name.ibd文件大小为12M,而archive_name.ARZ文件大小仅为4.4K
Memory存储引擎
数据都是存储在内存中,IO效率要比其他引擎高很多。服务重启数据丢失,内存数据表默认只有16M
特点:
- 支持hash索引、B tree索引,默认是hash索引(查找复杂度O(1))
- 字段长度都是固定长度varchar(32)/char(32)
- 不支持大数据存储类型字段如blog、text
The used table type doesn't support BLOB/TEXT columns - 表级锁
应用场景:
- 等值查找热度较高数据
- 查询结果内存中的计算,大多数都是采用这种存储引擎作为临时表存储需计算的数据
Myisam
Mysql5.5之前的默认存储引擎
特点:
- select count(*) from xx 这个操作无需进行数据表的扫瞄,该存储引擎下专门在表中记录了count数
- 数据MYD和索引MYI分开存储
- 表级锁
- 不支持事务
Innodb
- 支持事务
- 行级锁
- 聚集索引方式进行数据存储
- 支持外键关系保证数据完整性
执行优化
Mysql客户端/服务端通信
Mysql客户端与服务端的通信方式是半双工
- 全双工:双向通信,发送同时也可以接收
- 半双工:双向通信,同时只能接收或者是发送,无法同时做操作
- 单工:只能单一方向传送
客户端一旦开始发送消息,另一端要接收完整个消息才能响应。客户端一旦开始接收数据就没办法停下来发送指令
查询状态
对于一个mysql连接,或者一个线程,时刻都有一个状态来标识这个连接正在做什么
查看命令show full processlist或show processlist

Command的含义:
- Sleep 线程正在等待客户端发送数据
- Query 连接线程正在执行查询
- Locked 线程正在等待表锁的释放
- Sorting result 线程正在对结果进行排序
- Sending data 向请求端返回数据
如果某个操作花费了很多时间,耗费了sql很多资源,可以通过kill {id}的方式将连接杀掉
查询缓存 以读为主的业务,数据生成之后就不常改变的业务可以使用查询缓存
工作原理:缓存select操作的结果集和sql语句;新的select语句,先去查询缓存,如果有可用的记录集,则使用缓存数据
判断标准:
待执行的sql语句与缓存的SQL语句是否完全一样,区分大小写。(可以理解为一个key-value结构,key是sql,value是sql查询的结果集)
-
query_cache_type
- 0 不起用查询缓存,默认值
- 1 启用查询缓存,只要符合查询缓存的要求,客户端的查询语句和记录集都可以缓存起来,供其他客户端使用,如果查询语句和记录集加上
SQL_NO_CACHE将不缓存 - 2 启用查询缓存,只要查询语句中添加
SQL_CACHE且符合查询缓存的要求,客户端的查询语句和记录集则可以缓存起来,供其他客户端使用
-
query_cache_size
允许设置query_cache_size的值最小为40K,默认是1M
-
query_cache_limit 限制查询缓存区最大能缓存的查询记录集,默认设置为1M
show status like 'Qcache%'命令可查看缓存情况

默认查询缓存是不开启的,如有需要可以去my.ini配置文件里配置
查询缓存-不会缓存的情况
1.当查询语句中有一些不确定的数据时,则不会被缓存。如包含函数NOW(), CURRENT_DATE()等类似的函数,或者用户自定义的函数,存储函数,用户变量等都不会被缓存
2.当查询的结果大于query_cache_limit设置的值时,结果不会被缓存
3.对于InnoDB引擎来说,当一个语句在事务中修改了某个表,那么在这个事务 提交之前,所有与这个表相关的查询都无法被缓存。因此长时间执行事务, 会大大降低缓存命中率
4,查询的表是系统表 5,查询语句不涉及到表
为什么mysql默认关闭了缓存开启??
1.在查询之前必须先检查是否命中缓存,浪费计算资源
2.将语句集火结果集加入缓存的过程,会带来额外的系统消耗
3.**针对表进行写入或更新数据时,将对应表的所有缓存都设置失效。 **
4.如果查询缓存很大或者碎片很多时,这个操作可能带来很大的系统消耗
查询优化处理
- 解析sql 通过lex词法分析,yacc语法分析将sql语句解析成解析树
- 预处理阶段 根据mysql的语法的规则进一步检查解析树的合法性,如检查数据的表和列是否存在,解析名字和别名的设置等
- 查询优化器 主要作用就是找到最优执行计划
执行计划
通过explain关键字可以模拟sql语句的执行情况

执行计划-id
select查询的序列号,标识执行的顺序
1、id相同,执行顺序由上至下
2、id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
3、id相同又不同即两种情况同时存在,id如果相同,可以认为是一组,从上往下顺序 执行;在所有组中,id值越大,优先级越高,越先执行
执行计划类型
查询的类型,主要是用于区分普通查询、联合查询、子查询等
SIMPLE:简单的select查询,查询中不包含子查询或者union
PRIMARY:查询中包含子部分,最外层查询则被标记为primary
SUBQUERY/MATERIALIZED:SUBQUERY表示在select 或 where列表中包含了子查询;MATERIALIZED表示where 后面in条件的子查询
UNION:若第二个select出现在union之后,则被标记为union;
UNION RESULT:从union表获取结果的select
以users和user_address表为例 说明执行计划类型
CREATE TABLE `user_address` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`userID` int(11) DEFAULT NULL,
`addr` varchar(256) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
CREATE TABLE `users` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`uname` varchar(32) NOT NULL,
`userLevel` int(11) NOT NULL,
`age` int(11) NOT NULL,
`phoneNum` char(11) NOT NULL,
`createTime` datetime NOT NULL,
`lastUpdate` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`uname`) USING BTREE,
KEY `idx_union_uname&userLevel&age` (`uname`,`userLevel`,`age`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
-- 两张表通过userID和id关联
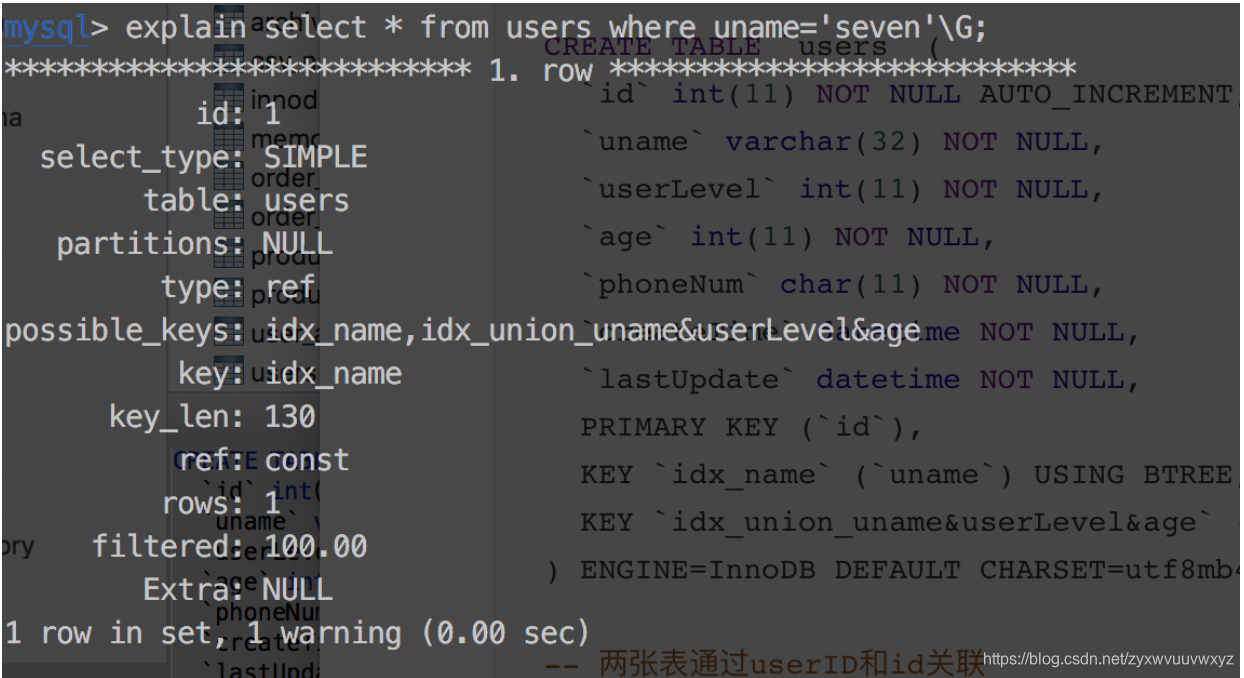
SIMPLE:简单的select查询 查询中不包含子查询或union
explain select * from users where uname='seven'\G;
explain select a.* from users a join user_address b on a.id=b.userID\G;
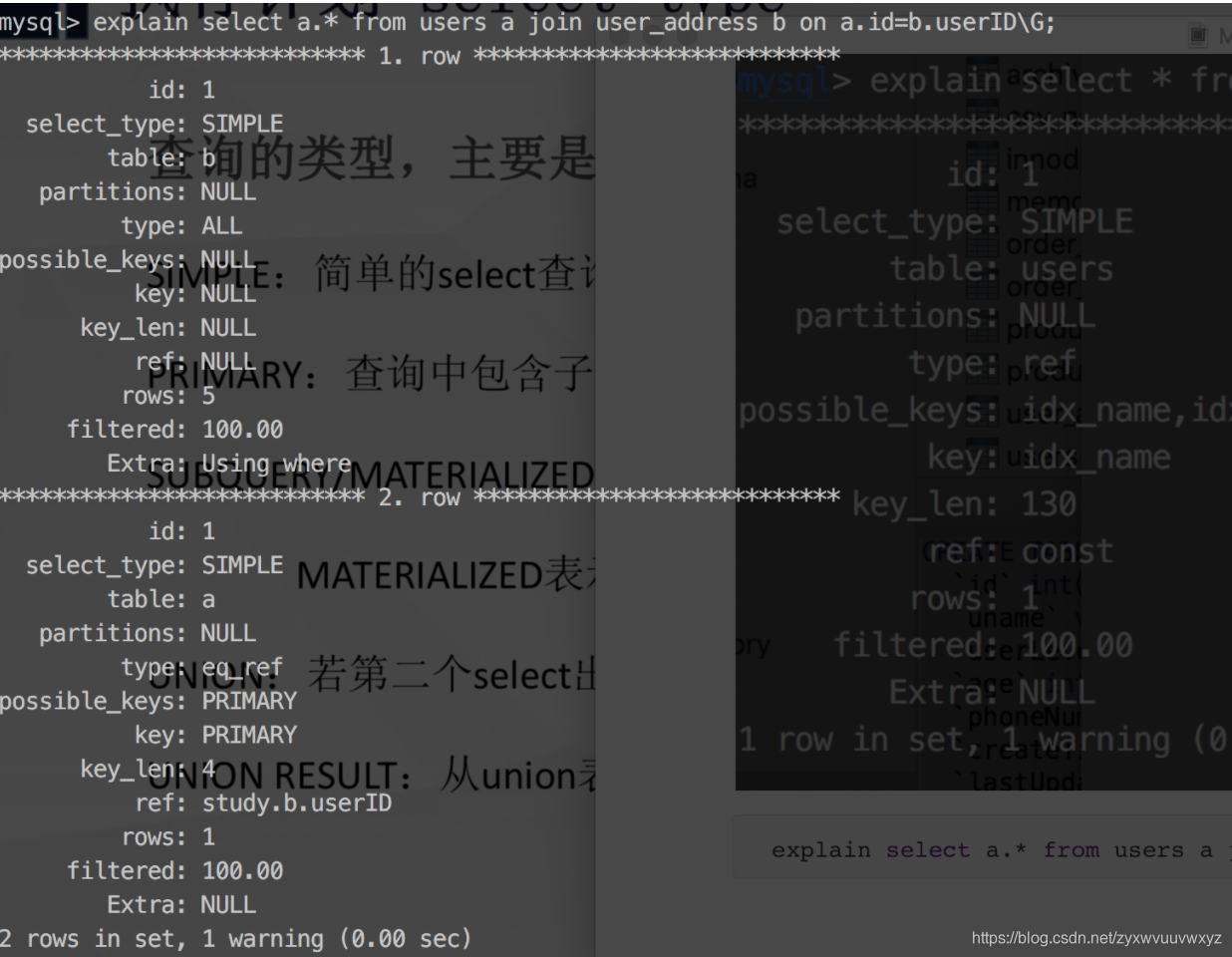
PRIMARY:查询中包含子查询,最外层的查询被表级为primary
SUBQUERY:表示在select或where列表中包含了子查询
explain select * from users where id = (select userID from user_address where uname='seven')\G;

MATERIALIZED:表示where后面in条件的子查询
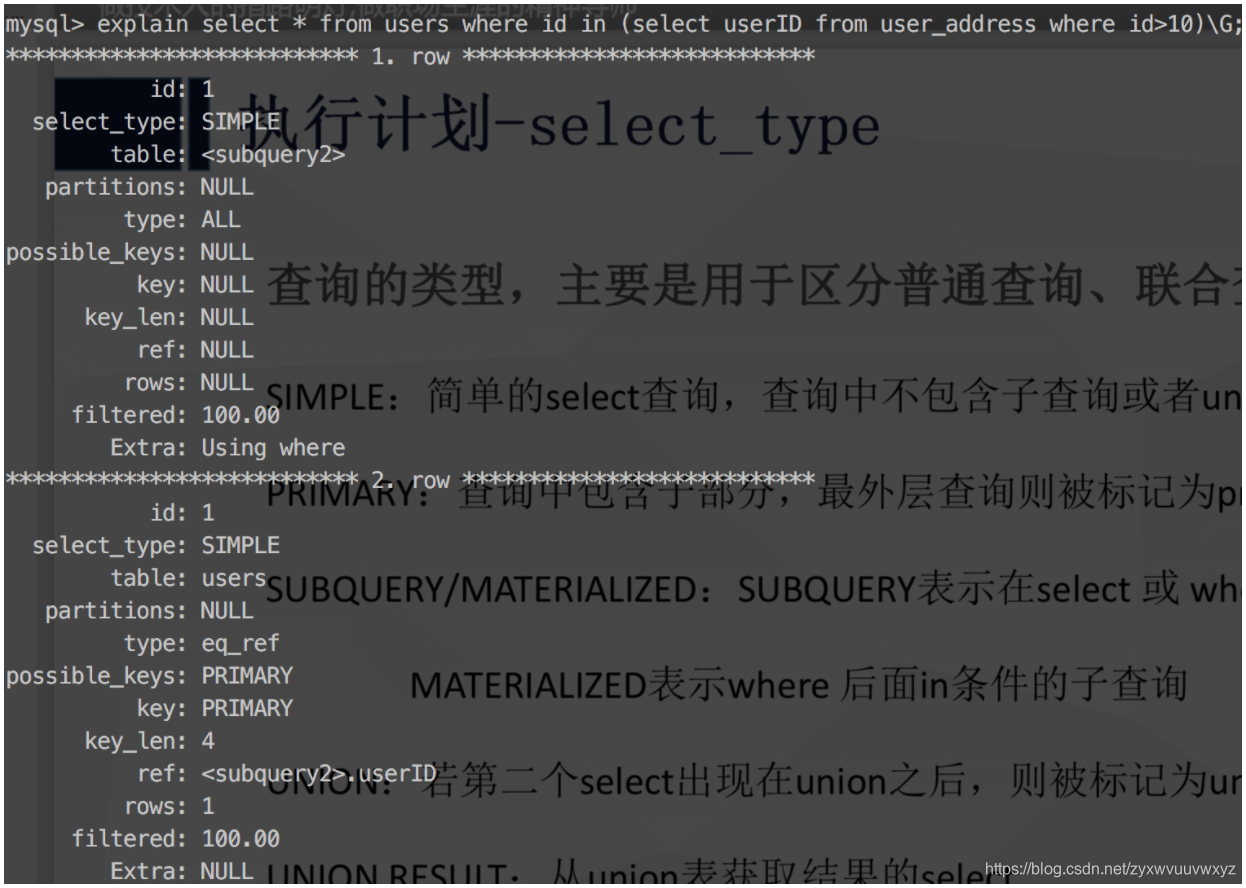
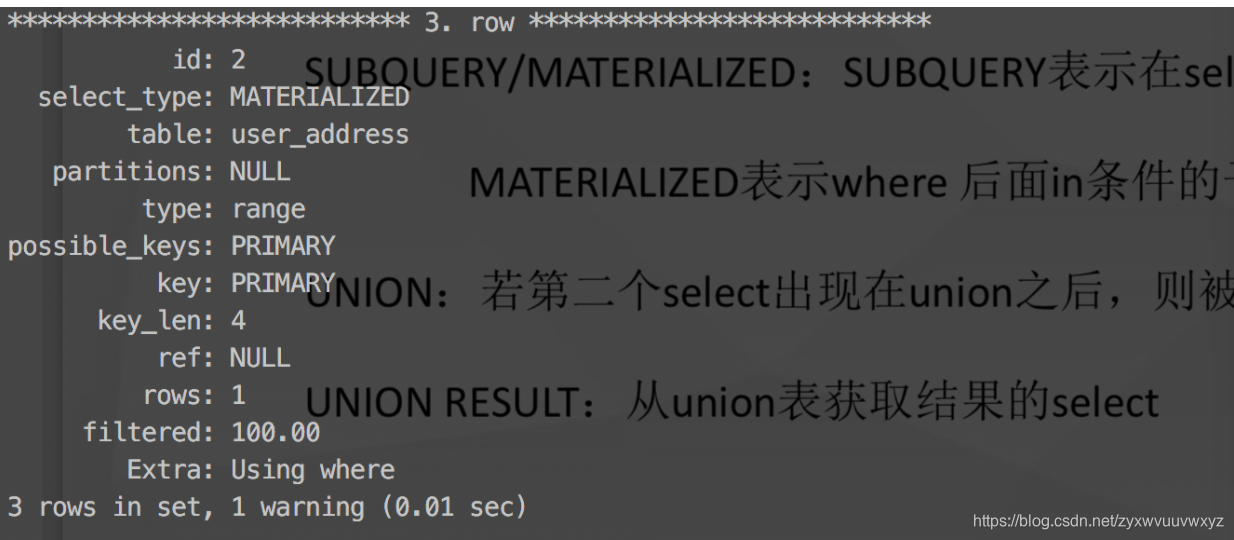
在这里可以看到前两个id=1,后一个id=2,则可以看出先执行id=2的语句,然后两个id=1的语句 顺序执行。其中第一个的subquery2表示 它查询的临时表的数据源是id=2的子查询结果
union:若第二个select出现在union,则被标记为union
explain select id from users
union
select userID from user_address\G;
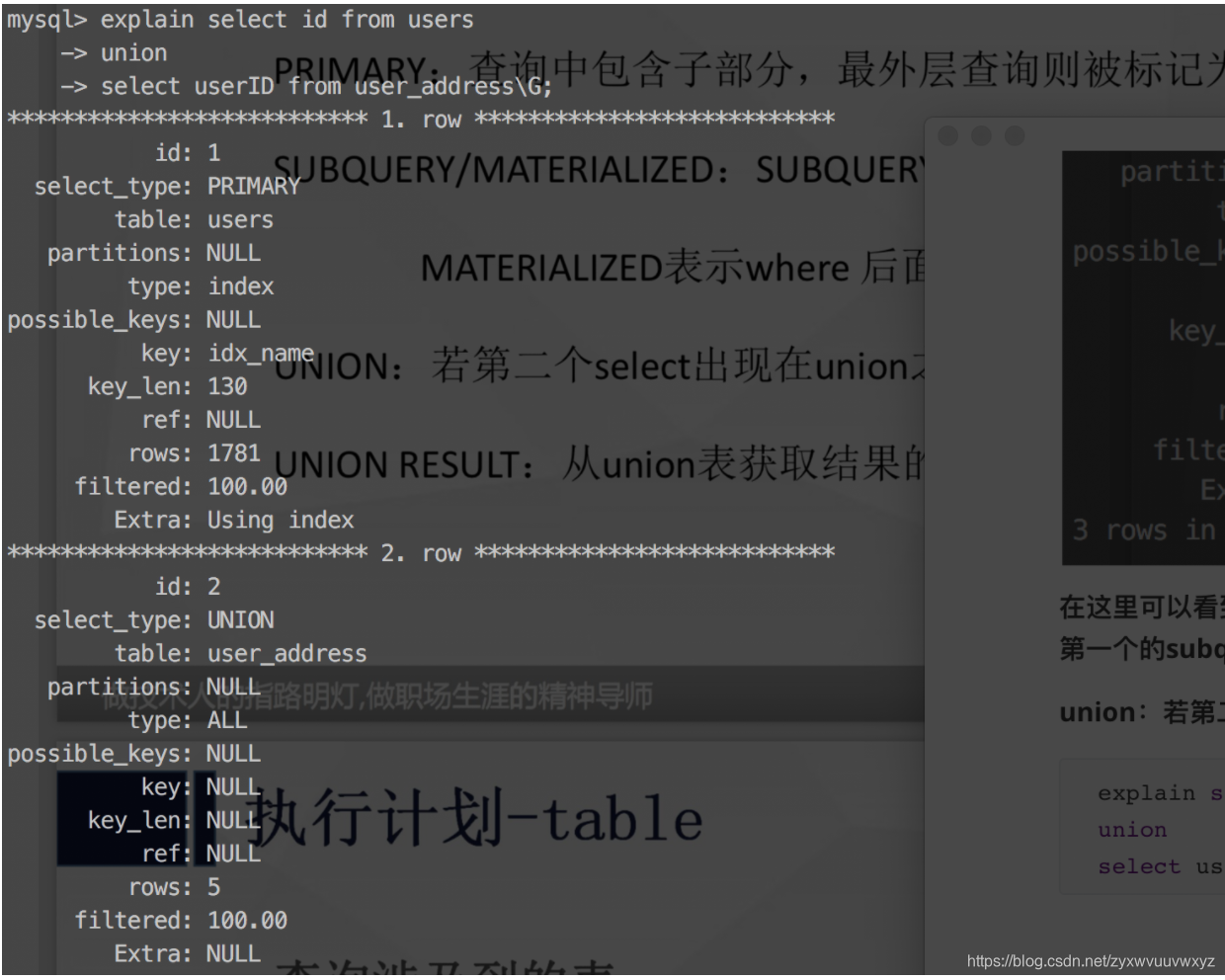
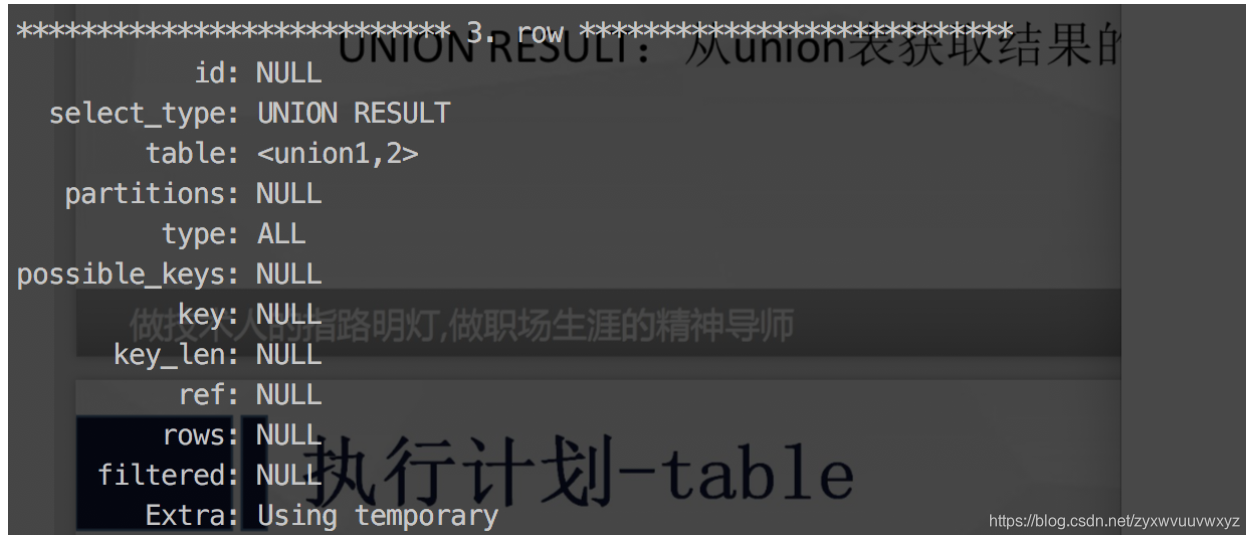
先执行id=2的查询,它的select_type=union;在执行id=1的查询,最后执行id:null的查询。<UNION 1,2>表示由id=1和id=2 union得到的结果
UNION RESULT:从union表中获取结果的select
EXPLAIN select r.id from
(
select id from users
union
select userID as id from user_address
)as r;

select_type=DERIVED 表示临时表的意思,执行顺序分别是3,2,1,随后执行select_type=UNION_RESULT的语句
**访问类型,sql查询优化中一个很重要的指标,结果值从好到坏依次是: system > const > eq_ref > ref > range > index > ALL **
system:表只有一行记录(等于系统表),const类型的特例,基本不会出现,可以忽略不计
const:表示通过索引一次就找到了,const用于比较primary key 或者 unique索引。可类比为使用主键或唯一所以查询。
explain select * from users where id=1;

eq_ref:唯一索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键 或 唯一索引扫描
ref:非唯一性索引扫描,返回匹配某个单独值的所有行,本质是也是一种索引访问
explain select * from users where uname='李二狗';

range:只检索给定范围的行,使用一个索引来选择行
explain select * from users where id<10;

index:Full Index Scan,索引全表扫描,把索引从头到尾扫一遍
ALL:Full Table Scan,遍历全表以找到匹配的行
explain select * from users where age<30;

表示是简单查询,全表扫描,rows=1781表示扫描的数据条数,filtered表示返回结果的行占需要督导的行的百分比
possible_keys 查询过程中有可能用到的索引
key 实际使用的索引,如果为NULL,则没有使用索引
rows 根据表统计信息或者索引选用情况,大致估算出找到所需的记录所需要读取的行 数
filtered 它指返回结果的行占需要读到的行(rows列的值)的百分比 表示返回结果的行数占需读取行数的百分比,filtered的值越大越好
十分重要的额外信息 Extra
1、Using filesort : mysql对数据使用一个外部的文件内容进行了排序,而不是按照表内的索引进行排序读取
2、Using temporary: 使用临时表保存中间结果,也就是说mysql在对查询结果排序时使用了临时表,常见于order by 或 group by
3、Using index:表示相应的select操作中使用了覆盖索引(Covering Index),避免了访问表的数据行,效率高
4、Using where : 使用了where过滤条件
5、select tables optimized away: 基于索引优化MIN/MAX操作或者MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段在进行计算,查询执行 计划生成的阶段即可完成优化
SQL语句的访问类型最差也要是range级别
explain select uname from users where age<30;
-- 由于uname同时也是索引,放在查询列里相当于覆盖索引 这时候执行计划中extra有Using where;Using index
-- 这个时候select列必须是只有索引列 才能算是覆盖索引,如这里的uname。如果再随便加上一个字段 则查询不走索引了

不走索引的
explain select age,phoneNum from user

