前言
大数据环境CDH已搭建完毕,第一个MapReduce程序wordcount也已成功运行,接下来我们需要通过WordCount来了解MapReduce的运行机制。
如何大致了解MapReduce的运行机制呢?有两点,(1)源码,对一个搞开发的人来说,我都有你MapReduce所有相关的源码jar包,有你所有的类文件,还能不知道你是怎么执行的吗?当然,要具备一定的源码阅读调试经验和编码功底;(2)运行日志,日志真的是特别重要的东西,它详细地记录了程序的运行流程,当然,前提是必须将有用的运行信息都打印出来,基本上没有分析日志解决不了的问题,如果有,那就多打几行。
改造源码
所以,我们在针对WordCount.java中相关的类做了一些源码阅读的认识后,需要稍微改造一下WordCount.java,即为其map、combine和reduce函数添加一些必要的日志输出,当然在实际的过程中,随着对MR的认识逐渐全面,其实是一部分一部分添加的。另外,为了区分开combine和reduce的日志,我们将job.setCombinerClass(IntSumCombiner.class)替换为job.setCombinerClass(IntSumReducer.class),而IntSumCombiner和IntSumReducer的区别仅在于类名的不同。如下贴出我在微整后的WordCount:
package com.szh.hadoop;
import java.io.File;
import java.io.IOException;
import java.net.InetAddress;
import java.util.Arrays;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class WordCount {
protected static final Logger LOG = LoggerFactory.getLogger(WordCount.class);
@SuppressWarnings("deprecation")
public static void main(String[] args) throws Exception {
LOG.info("main方法执行在机器: {}上", InetAddress.getLocalHost());
LOG.info("Args: " + Arrays.toString(args));
Configuration conf = new Configuration();
// instead of mapred.jar(deprecated)
conf.set("mapreduce.job.jar", System.getProperty("user.dir") + File.separator + "wc.jar");
LOG.info("当前工作目录: {}", System.getProperty("user.dir"));
File jarFile = new File(conf.get("mapreduce.job.jar"));
LOG.info("Jar to run: {}, {}, {}", jarFile.getAbsolutePath(), jarFile.isFile(), jarFile.exists());
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
LOG.error("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = new Job(conf, "szh's word count 20190613");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumCombiner.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; i++) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
LOG.info("Input path: {}", otherArgs[i]);
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[(otherArgs.length - 1)]));
LOG.info("Output path: {}", otherArgs[(otherArgs.length - 1)]);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
LOG.info("map方法执行在机器: {}上", InetAddress.getLocalHost());
LOG.info("源文本数据(map输入数据): {} : {}", key, value);
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
LOG.info("\tmap循环: <{},{}>", word, one);
}
LOG.info("本次map结束!");
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
LOG.info("reduce方法执行在机器: {}上", InetAddress.getLocalHost());
LOG.info("reduce输入数据: {},{}", key, values);
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
LOG.info("\treduce循环: <{},{}>", key, val.get());
}
this.result.set(sum);
context.write(key, this.result);
LOG.info("本次reduce结束: <{},{}>", key, result);
}
}
public static class IntSumCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
LOG.info("combine方法执行在机器: {}上", InetAddress.getLocalHost());
LOG.info("combine输入数据: {},{}", key, values);
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
LOG.info("\tcombine循环: <{},{}>", key, val.get());
}
this.result.set(sum);
context.write(key, this.result);
LOG.info("本次combine结束: <{},{}>", key, result);
}
}
}如想对比其与hadoop自带WordCount的区别,可自行反编译或去https://blog.csdn.net/songzehao/article/details/91560692复制查看即可。另外,附上我的源文本数据:
[root@bi-zhaopeng04 ~]# hadoop fs -cat /tmp/songzehao/words_input
szh dk tyn cj cj zp zp szh dk szh dk dk dk tyn
szh dk tyn cj cj zp zp szh dk szh dk dk dk tyn运行获取日志
该加的日志输出都已添加完毕,接下来就该运行一把了,最后获取相应日志,并结合理论知识指导进行分析总结。
运行步骤在此不做赘述,有问题可参考https://blog.csdn.net/songzehao/article/details/91560692,那么,本次运行相关的日志从何获取?
很显然,在MR执行过程中,控制台上会输出一些日志,我们姑且称其为console.log,如下:
19/06/13 16:20:06 INFO hadoop.WordCount: main方法执行在机器: bi-zhaopeng04/10.1.4.19上
19/06/13 16:20:06 INFO hadoop.WordCount: Args: [/tmp/songzehao/words_input, /tmp/songzehao/words_output]
19/06/13 16:20:06 INFO hadoop.WordCount: 当前工作目录: /opt/szh
19/06/13 16:20:06 INFO hadoop.WordCount: Jar to run: /opt/szh/wc.jar, false, false
19/06/13 16:20:06 INFO hadoop.WordCount: Input path: /tmp/songzehao/words_input
19/06/13 16:20:06 INFO hadoop.WordCount: Output path: /tmp/songzehao/words_output
19/06/13 16:20:06 INFO client.RMProxy: Connecting to ResourceManager at bi-zhaopeng03/10.1.4.18:8032
19/06/13 16:20:07 INFO input.FileInputFormat: Total input paths to process : 1
19/06/13 16:20:07 INFO mapreduce.JobSubmitter: number of splits:1
19/06/13 16:20:07 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1559721784881_0053
19/06/13 16:20:07 INFO impl.YarnClientImpl: Submitted application application_1559721784881_0053
19/06/13 16:20:07 INFO mapreduce.Job: The url to track the job: http://bi-zhaopeng03:8088/proxy/application_1559721784881_0053/
19/06/13 16:20:07 INFO mapreduce.Job: Running job: job_1559721784881_0053
19/06/13 16:20:11 INFO mapreduce.Job: Job job_1559721784881_0053 running in uber mode : false
19/06/13 16:20:11 INFO mapreduce.Job: map 0% reduce 0%
19/06/13 16:20:15 INFO mapreduce.Job: map 100% reduce 0%
19/06/13 16:20:19 INFO mapreduce.Job: map 100% reduce 13%
19/06/13 16:20:22 INFO mapreduce.Job: map 100% reduce 25%
19/06/13 16:20:26 INFO mapreduce.Job: map 100% reduce 38%
19/06/13 16:20:29 INFO mapreduce.Job: map 100% reduce 50%
19/06/13 16:20:32 INFO mapreduce.Job: map 100% reduce 63%
19/06/13 16:20:35 INFO mapreduce.Job: map 100% reduce 75%
19/06/13 16:20:38 INFO mapreduce.Job: map 100% reduce 88%
19/06/13 16:20:41 INFO mapreduce.Job: map 100% reduce 100%
19/06/13 16:20:41 INFO mapreduce.Job: Job job_1559721784881_0053 completed successfully
19/06/13 16:20:41 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=367
FILE: Number of bytes written=2019909
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=210
HDFS: Number of bytes written=28
HDFS: Number of read operations=51
HDFS: Number of large read operations=0
HDFS: Number of write operations=32
Job Counters
Launched map tasks=1
Launched reduce tasks=16
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=1731
Total time spent by all reduces in occupied slots (ms)=28579
Total time spent by all map tasks (ms)=1731
Total time spent by all reduce tasks (ms)=28579
Total vcore-seconds taken by all map tasks=1731
Total vcore-seconds taken by all reduce tasks=28579
Total megabyte-seconds taken by all map tasks=1772544
Total megabyte-seconds taken by all reduce tasks=29264896
Map-Reduce Framework
Map input records=2
Map output records=28
Map output bytes=206
Map output materialized bytes=303
Input split bytes=116
Combine input records=28
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=303
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =16
Failed Shuffles=0
Merged Map outputs=16
GC time elapsed (ms)=863
CPU time spent (ms)=12960
Physical memory (bytes) snapshot=3826233344
Virtual memory (bytes) snapshot=48430043136
Total committed heap usage (bytes)=3508535296
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=94
File Output Format Counters
Bytes Written=28控制台上确实有日志打印,但是细看只有main方法的日志输出,map、combine和reduce各自的日志跑去哪里了?可访问yarn的web管理地址(masterIp:8088),找到对应应用程序ApplicationId(比如,通过查看console.log,得知我的ApplicationId是application_1559721784881_0053)的History,界面如下:

再分别点进各MapTask和各ReduceTask里获取完整日志,因为我的ReduceTask中只有3个有输出(task_1559721784881_0053_r_000000,task_1559721784881_0053_r_000007,task_1559721784881_0053_r_000008),所以如下贴出map.log和3+1个reduce.log,其中多出的那1个,是13个空跑的reduce中的任意一个代表:
map.log:
2019-06-13 16:20:13,286 INFO [main] org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2019-06-13 16:20:13,344 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s).
2019-06-13 16:20:13,344 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system started
2019-06-13 16:20:13,351 INFO [main] org.apache.hadoop.mapred.YarnChild: Executing with tokens:
2019-06-13 16:20:13,351 INFO [main] org.apache.hadoop.mapred.YarnChild: Kind: mapreduce.job, Service: job_1559721784881_0053, Ident: (org.apache.hadoop.mapreduce.security.token.JobTokenIdentifier@59309333)
2019-06-13 16:20:13,407 INFO [main] org.apache.hadoop.mapred.YarnChild: Sleeping for 0ms before retrying again. Got null now.
2019-06-13 16:20:13,591 INFO [main] org.apache.hadoop.mapred.YarnChild: mapreduce.cluster.local.dir for child: /yarn/nm/usercache/hdfs/appcache/application_1559721784881_0053
2019-06-13 16:20:13,726 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
2019-06-13 16:20:14,050 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: File Output Committer Algorithm version is 1
2019-06-13 16:20:14,060 INFO [main] org.apache.hadoop.mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2019-06-13 16:20:14,177 INFO [main] org.apache.hadoop.mapred.MapTask: Processing split: hdfs://bi-zhaopeng03:8020/tmp/songzehao/words_input:0+94
2019-06-13 16:20:14,249 INFO [main] org.apache.hadoop.mapred.MapTask: (EQUATOR) 0 kvi 67108860(268435440)
2019-06-13 16:20:14,250 INFO [main] org.apache.hadoop.mapred.MapTask: mapreduce.task.io.sort.mb: 256
2019-06-13 16:20:14,250 INFO [main] org.apache.hadoop.mapred.MapTask: soft limit at 214748368
2019-06-13 16:20:14,250 INFO [main] org.apache.hadoop.mapred.MapTask: bufstart = 0; bufvoid = 268435456
2019-06-13 16:20:14,250 INFO [main] org.apache.hadoop.mapred.MapTask: kvstart = 67108860; length = 16777216
2019-06-13 16:20:14,255 INFO [main] org.apache.hadoop.mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2019-06-13 16:20:14,267 INFO [main] com.szh.hadoop.WordCount: map方法执行在机器: bi-zhaopeng05/10.1.4.20上
2019-06-13 16:20:14,267 INFO [main] com.szh.hadoop.WordCount: 源文本数据(map输入数据): 0 : szh dk tyn cj cj zp zp szh dk szh dk dk dk tyn
2019-06-13 16:20:14,267 INFO [main] com.szh.hadoop.WordCount: map循环: <szh,1>
2019-06-13 16:20:14,267 INFO [main] com.szh.hadoop.WordCount: map循环: <dk,1>
2019-06-13 16:20:14,267 INFO [main] com.szh.hadoop.WordCount: map循环: <tyn,1>
2019-06-13 16:20:14,267 INFO [main] com.szh.hadoop.WordCount: map循环: <cj,1>
2019-06-13 16:20:14,267 INFO [main] com.szh.hadoop.WordCount: map循环: <cj,1>
2019-06-13 16:20:14,267 INFO [main] com.szh.hadoop.WordCount: map循环: <zp,1>
2019-06-13 16:20:14,267 INFO [main] com.szh.hadoop.WordCount: map循环: <zp,1>
2019-06-13 16:20:14,267 INFO [main] com.szh.hadoop.WordCount: map循环: <szh,1>
2019-06-13 16:20:14,267 INFO [main] com.szh.hadoop.WordCount: map循环: <dk,1>
2019-06-13 16:20:14,267 INFO [main] com.szh.hadoop.WordCount: map循环: <szh,1>
2019-06-13 16:20:14,267 INFO [main] com.szh.hadoop.WordCount: map循环: <dk,1>
2019-06-13 16:20:14,267 INFO [main] com.szh.hadoop.WordCount: map循环: <dk,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <dk,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <tyn,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: 本次map结束!
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map方法执行在机器: bi-zhaopeng05/10.1.4.20上
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: 源文本数据(map输入数据): 47 : szh dk tyn cj cj zp zp szh dk szh dk dk dk tyn
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <szh,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <dk,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <tyn,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <cj,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <cj,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <zp,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <zp,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <szh,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <dk,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <szh,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <dk,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <dk,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <dk,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: map循环: <tyn,1>
2019-06-13 16:20:14,268 INFO [main] com.szh.hadoop.WordCount: 本次map结束!
2019-06-13 16:20:14,275 INFO [main] org.apache.hadoop.mapred.MapTask: Starting flush of map output
2019-06-13 16:20:14,275 INFO [main] org.apache.hadoop.mapred.MapTask: Spilling map output
2019-06-13 16:20:14,275 INFO [main] org.apache.hadoop.mapred.MapTask: bufstart = 0; bufend = 206; bufvoid = 268435456
2019-06-13 16:20:14,275 INFO [main] org.apache.hadoop.mapred.MapTask: kvstart = 67108860(268435440); kvend = 67108752(268435008); length = 109/16777216
2019-06-13 16:20:14,283 INFO [main] org.apache.hadoop.io.compress.CodecPool: Got brand-new compressor [.snappy]
2019-06-13 16:20:14,290 INFO [main] com.szh.hadoop.WordCount: combine方法执行在机器: bi-zhaopeng05/10.1.4.20上
2019-06-13 16:20:14,290 INFO [main] com.szh.hadoop.WordCount: combine输入数据: szh,org.apache.hadoop.mapreduce.task.ReduceContextImpl$ValueIterable@2ccca26f
2019-06-13 16:20:14,290 INFO [main] com.szh.hadoop.WordCount: combine循环: <szh,1>
2019-06-13 16:20:14,290 INFO [main] com.szh.hadoop.WordCount: combine循环: <szh,1>
2019-06-13 16:20:14,290 INFO [main] com.szh.hadoop.WordCount: combine循环: <szh,1>
2019-06-13 16:20:14,290 INFO [main] com.szh.hadoop.WordCount: combine循环: <szh,1>
2019-06-13 16:20:14,290 INFO [main] com.szh.hadoop.WordCount: combine循环: <szh,1>
2019-06-13 16:20:14,290 INFO [main] com.szh.hadoop.WordCount: combine循环: <szh,1>
2019-06-13 16:20:14,290 INFO [main] com.szh.hadoop.WordCount: 本次combine结束: <szh,6>
2019-06-13 16:20:14,292 INFO [main] com.szh.hadoop.WordCount: combine方法执行在机器: bi-zhaopeng05/10.1.4.20上
2019-06-13 16:20:14,292 INFO [main] com.szh.hadoop.WordCount: combine输入数据: zp,org.apache.hadoop.mapreduce.task.ReduceContextImpl$ValueIterable@3542162a
2019-06-13 16:20:14,292 INFO [main] com.szh.hadoop.WordCount: combine循环: <zp,1>
2019-06-13 16:20:14,292 INFO [main] com.szh.hadoop.WordCount: combine循环: <zp,1>
2019-06-13 16:20:14,292 INFO [main] com.szh.hadoop.WordCount: combine循环: <zp,1>
2019-06-13 16:20:14,292 INFO [main] com.szh.hadoop.WordCount: combine循环: <zp,1>
2019-06-13 16:20:14,292 INFO [main] com.szh.hadoop.WordCount: 本次combine结束: <zp,4>
2019-06-13 16:20:14,293 INFO [main] com.szh.hadoop.WordCount: combine方法执行在机器: bi-zhaopeng05/10.1.4.20上
2019-06-13 16:20:14,293 INFO [main] com.szh.hadoop.WordCount: combine输入数据: cj,org.apache.hadoop.mapreduce.task.ReduceContextImpl$ValueIterable@698122b2
2019-06-13 16:20:14,293 INFO [main] com.szh.hadoop.WordCount: combine循环: <cj,1>
2019-06-13 16:20:14,293 INFO [main] com.szh.hadoop.WordCount: combine循环: <cj,1>
2019-06-13 16:20:14,293 INFO [main] com.szh.hadoop.WordCount: combine循环: <cj,1>
2019-06-13 16:20:14,293 INFO [main] com.szh.hadoop.WordCount: combine循环: <cj,1>
2019-06-13 16:20:14,293 INFO [main] com.szh.hadoop.WordCount: 本次combine结束: <cj,4>
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine方法执行在机器: bi-zhaopeng05/10.1.4.20上
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine输入数据: dk,org.apache.hadoop.mapreduce.task.ReduceContextImpl$ValueIterable@698122b2
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine循环: <dk,1>
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine循环: <dk,1>
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine循环: <dk,1>
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine循环: <dk,1>
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine循环: <dk,1>
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine循环: <dk,1>
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine循环: <dk,1>
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine循环: <dk,1>
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine循环: <dk,1>
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine循环: <dk,1>
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: 本次combine结束: <dk,10>
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine方法执行在机器: bi-zhaopeng05/10.1.4.20上
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine输入数据: tyn,org.apache.hadoop.mapreduce.task.ReduceContextImpl$ValueIterable@698122b2
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine循环: <tyn,1>
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine循环: <tyn,1>
2019-06-13 16:20:14,294 INFO [main] com.szh.hadoop.WordCount: combine循环: <tyn,1>
2019-06-13 16:20:14,295 INFO [main] com.szh.hadoop.WordCount: combine循环: <tyn,1>
2019-06-13 16:20:14,295 INFO [main] com.szh.hadoop.WordCount: 本次combine结束: <tyn,4>
2019-06-13 16:20:14,296 INFO [main] org.apache.hadoop.mapred.MapTask: Finished spill 0
2019-06-13 16:20:14,299 INFO [main] org.apache.hadoop.mapred.Task: Task:attempt_1559721784881_0053_m_000000_0 is done. And is in the process of committing
2019-06-13 16:20:14,353 INFO [main] org.apache.hadoop.mapred.Task: Task 'attempt_1559721784881_0053_m_000000_0' done.
2019-06-13 16:20:14,454 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping MapTask metrics system...
2019-06-13 16:20:14,454 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system stopped.
2019-06-13 16:20:14,454 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: MapTask metrics system shutdown complete.reduce-00000.log:
2019-06-13 16:20:17,153 INFO [main] org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2019-06-13 16:20:17,210 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s).
2019-06-13 16:20:17,210 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system started
2019-06-13 16:20:17,217 INFO [main] org.apache.hadoop.mapred.YarnChild: Executing with tokens:
2019-06-13 16:20:17,217 INFO [main] org.apache.hadoop.mapred.YarnChild: Kind: mapreduce.job, Service: job_1559721784881_0053, Ident: (org.apache.hadoop.mapreduce.security.token.JobTokenIdentifier@59309333)
2019-06-13 16:20:17,273 INFO [main] org.apache.hadoop.mapred.YarnChild: Sleeping for 0ms before retrying again. Got null now.
2019-06-13 16:20:17,454 INFO [main] org.apache.hadoop.mapred.YarnChild: mapreduce.cluster.local.dir for child: /yarn/nm/usercache/hdfs/appcache/application_1559721784881_0053
2019-06-13 16:20:17,595 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
2019-06-13 16:20:17,922 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: File Output Committer Algorithm version is 1
2019-06-13 16:20:17,932 INFO [main] org.apache.hadoop.mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2019-06-13 16:20:17,964 INFO [main] org.apache.hadoop.mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@1a760689
2019-06-13 16:20:17,978 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: MergerManager: memoryLimit=535088320, maxSingleShuffleLimit=133772080, mergeThreshold=353158304, ioSortFactor=64, memToMemMergeOutputsThreshold=64
2019-06-13 16:20:17,980 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: attempt_1559721784881_0053_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
2019-06-13 16:20:17,987 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: attempt_1559721784881_0053_r_000000_0: Got 1 new map-outputs
2019-06-13 16:20:17,987 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: Assigning bi-zhaopeng05:13562 with 1 to fetcher#10
2019-06-13 16:20:17,988 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: assigned 1 of 1 to bi-zhaopeng05:13562 to fetcher#10
2019-06-13 16:20:18,088 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.Fetcher: for url=13562/mapOutput?job=job_1559721784881_0053&reduce=0&map=attempt_1559721784881_0053_m_000000_0 sent hash and received reply
2019-06-13 16:20:18,094 INFO [fetcher#10] org.apache.hadoop.io.compress.CodecPool: Got brand-new decompressor [.snappy]
2019-06-13 16:20:18,097 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.Fetcher: fetcher#10 about to shuffle output of map attempt_1559721784881_0053_m_000000_0 decomp: 12 len: 26 to MEMORY
2019-06-13 16:20:18,099 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput: Read 12 bytes from map-output for attempt_1559721784881_0053_m_000000_0
2019-06-13 16:20:18,100 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 12, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->12
2019-06-13 16:20:18,101 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: EventFetcher is interrupted.. Returning
2019-06-13 16:20:18,101 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: bi-zhaopeng05:13562 freed by fetcher#10 in 113ms
2019-06-13 16:20:18,105 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
2019-06-13 16:20:18,110 INFO [main] org.apache.hadoop.mapred.Merger: Merging 1 sorted segments
2019-06-13 16:20:18,110 INFO [main] org.apache.hadoop.mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 6 bytes
2019-06-13 16:20:18,112 INFO [main] org.apache.hadoop.io.compress.CodecPool: Got brand-new compressor [.snappy]
2019-06-13 16:20:18,115 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merged 1 segments, 12 bytes to disk to satisfy reduce memory limit
2019-06-13 16:20:18,115 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merging 1 files, 30 bytes from disk
2019-06-13 16:20:18,116 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
2019-06-13 16:20:18,116 INFO [main] org.apache.hadoop.mapred.Merger: Merging 1 sorted segments
2019-06-13 16:20:18,118 INFO [main] org.apache.hadoop.mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 6 bytes
2019-06-13 16:20:18,187 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2019-06-13 16:20:18,194 INFO [main] com.szh.hadoop.WordCount: reduce方法执行在机器: bi-zhaopeng05/10.1.4.20上
2019-06-13 16:20:18,194 INFO [main] com.szh.hadoop.WordCount: reduce输入数据: szh,org.apache.hadoop.mapreduce.task.ReduceContextImpl$ValueIterable@4218500f
2019-06-13 16:20:18,194 INFO [main] com.szh.hadoop.WordCount: reduce循环: <szh,6>
2019-06-13 16:20:18,195 INFO [main] com.szh.hadoop.WordCount: 本次reduce结束: <szh,6>
2019-06-13 16:20:18,299 INFO [main] org.apache.hadoop.mapred.Task: Task:attempt_1559721784881_0053_r_000000_0 is done. And is in the process of committing
2019-06-13 16:20:18,327 INFO [main] org.apache.hadoop.mapred.Task: Task attempt_1559721784881_0053_r_000000_0 is allowed to commit now
2019-06-13 16:20:18,332 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: Saved output of task 'attempt_1559721784881_0053_r_000000_0' to hdfs://bi-zhaopeng03:8020/tmp/songzehao/words_output/_temporary/1/task_1559721784881_0053_r_000000
2019-06-13 16:20:18,350 INFO [main] org.apache.hadoop.mapred.Task: Task 'attempt_1559721784881_0053_r_000000_0' done.
2019-06-13 16:20:18,451 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping ReduceTask metrics system...
2019-06-13 16:20:18,451 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system stopped.
2019-06-13 16:20:18,451 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system shutdown complete.reduce-00007.log:
2019-06-13 16:20:26,195 INFO [main] org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2019-06-13 16:20:26,255 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s).
2019-06-13 16:20:26,255 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system started
2019-06-13 16:20:26,263 INFO [main] org.apache.hadoop.mapred.YarnChild: Executing with tokens:
2019-06-13 16:20:26,263 INFO [main] org.apache.hadoop.mapred.YarnChild: Kind: mapreduce.job, Service: job_1559721784881_0053, Ident: (org.apache.hadoop.mapreduce.security.token.JobTokenIdentifier@59309333)
2019-06-13 16:20:26,320 INFO [main] org.apache.hadoop.mapred.YarnChild: Sleeping for 0ms before retrying again. Got null now.
2019-06-13 16:20:26,497 INFO [main] org.apache.hadoop.mapred.YarnChild: mapreduce.cluster.local.dir for child: /yarn/nm/usercache/hdfs/appcache/application_1559721784881_0053
2019-06-13 16:20:26,637 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
2019-06-13 16:20:26,960 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: File Output Committer Algorithm version is 1
2019-06-13 16:20:26,970 INFO [main] org.apache.hadoop.mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2019-06-13 16:20:26,999 INFO [main] org.apache.hadoop.mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@1a760689
2019-06-13 16:20:27,012 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: MergerManager: memoryLimit=535088320, maxSingleShuffleLimit=133772080, mergeThreshold=353158304, ioSortFactor=64, memToMemMergeOutputsThreshold=64
2019-06-13 16:20:27,014 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: attempt_1559721784881_0053_r_000007_0 Thread started: EventFetcher for fetching Map Completion Events
2019-06-13 16:20:27,021 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: attempt_1559721784881_0053_r_000007_0: Got 1 new map-outputs
2019-06-13 16:20:27,021 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: Assigning bi-zhaopeng05:13562 with 1 to fetcher#10
2019-06-13 16:20:27,021 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: assigned 1 of 1 to bi-zhaopeng05:13562 to fetcher#10
2019-06-13 16:20:27,130 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.Fetcher: for url=13562/mapOutput?job=job_1559721784881_0053&reduce=7&map=attempt_1559721784881_0053_m_000000_0 sent hash and received reply
2019-06-13 16:20:27,135 INFO [fetcher#10] org.apache.hadoop.io.compress.CodecPool: Got brand-new decompressor [.snappy]
2019-06-13 16:20:27,139 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.Fetcher: fetcher#10 about to shuffle output of map attempt_1559721784881_0053_m_000000_0 decomp: 11 len: 25 to MEMORY
2019-06-13 16:20:27,141 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput: Read 11 bytes from map-output for attempt_1559721784881_0053_m_000000_0
2019-06-13 16:20:27,141 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 11, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->11
2019-06-13 16:20:27,142 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: EventFetcher is interrupted.. Returning
2019-06-13 16:20:27,142 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: bi-zhaopeng05:13562 freed by fetcher#10 in 120ms
2019-06-13 16:20:27,145 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
2019-06-13 16:20:27,151 INFO [main] org.apache.hadoop.mapred.Merger: Merging 1 sorted segments
2019-06-13 16:20:27,151 INFO [main] org.apache.hadoop.mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 6 bytes
2019-06-13 16:20:27,152 INFO [main] org.apache.hadoop.io.compress.CodecPool: Got brand-new compressor [.snappy]
2019-06-13 16:20:27,156 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merged 1 segments, 11 bytes to disk to satisfy reduce memory limit
2019-06-13 16:20:27,157 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merging 1 files, 29 bytes from disk
2019-06-13 16:20:27,157 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
2019-06-13 16:20:27,157 INFO [main] org.apache.hadoop.mapred.Merger: Merging 1 sorted segments
2019-06-13 16:20:27,159 INFO [main] org.apache.hadoop.mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 6 bytes
2019-06-13 16:20:27,220 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2019-06-13 16:20:27,227 INFO [main] com.szh.hadoop.WordCount: reduce方法执行在机器: bi-zhaopeng05/10.1.4.20上
2019-06-13 16:20:27,227 INFO [main] com.szh.hadoop.WordCount: reduce输入数据: zp,org.apache.hadoop.mapreduce.task.ReduceContextImpl$ValueIterable@4218500f
2019-06-13 16:20:27,227 INFO [main] com.szh.hadoop.WordCount: reduce循环: <zp,4>
2019-06-13 16:20:27,227 INFO [main] com.szh.hadoop.WordCount: 本次reduce结束: <zp,4>
2019-06-13 16:20:27,323 INFO [main] org.apache.hadoop.mapred.Task: Task:attempt_1559721784881_0053_r_000007_0 is done. And is in the process of committing
2019-06-13 16:20:27,355 INFO [main] org.apache.hadoop.mapred.Task: Task attempt_1559721784881_0053_r_000007_0 is allowed to commit now
2019-06-13 16:20:27,360 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: Saved output of task 'attempt_1559721784881_0053_r_000007_0' to hdfs://bi-zhaopeng03:8020/tmp/songzehao/words_output/_temporary/1/task_1559721784881_0053_r_000007
2019-06-13 16:20:27,378 INFO [main] org.apache.hadoop.mapred.Task: Task 'attempt_1559721784881_0053_r_000007_0' done.
2019-06-13 16:20:27,478 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping ReduceTask metrics system...
2019-06-13 16:20:27,479 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system stopped.
2019-06-13 16:20:27,479 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system shutdown complete.reduce-00008.log:
2019-06-13 16:20:29,221 INFO [main] org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2019-06-13 16:20:29,275 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s).
2019-06-13 16:20:29,275 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system started
2019-06-13 16:20:29,282 INFO [main] org.apache.hadoop.mapred.YarnChild: Executing with tokens:
2019-06-13 16:20:29,283 INFO [main] org.apache.hadoop.mapred.YarnChild: Kind: mapreduce.job, Service: job_1559721784881_0053, Ident: (org.apache.hadoop.mapreduce.security.token.JobTokenIdentifier@59309333)
2019-06-13 16:20:29,338 INFO [main] org.apache.hadoop.mapred.YarnChild: Sleeping for 0ms before retrying again. Got null now.
2019-06-13 16:20:29,513 INFO [main] org.apache.hadoop.mapred.YarnChild: mapreduce.cluster.local.dir for child: /yarn/nm/usercache/hdfs/appcache/application_1559721784881_0053
2019-06-13 16:20:29,665 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
2019-06-13 16:20:30,002 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: File Output Committer Algorithm version is 1
2019-06-13 16:20:30,011 INFO [main] org.apache.hadoop.mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2019-06-13 16:20:30,043 INFO [main] org.apache.hadoop.mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@1a760689
2019-06-13 16:20:30,057 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: MergerManager: memoryLimit=535088320, maxSingleShuffleLimit=133772080, mergeThreshold=353158304, ioSortFactor=64, memToMemMergeOutputsThreshold=64
2019-06-13 16:20:30,059 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: attempt_1559721784881_0053_r_000008_0 Thread started: EventFetcher for fetching Map Completion Events
2019-06-13 16:20:30,068 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: attempt_1559721784881_0053_r_000008_0: Got 1 new map-outputs
2019-06-13 16:20:30,068 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: Assigning bi-zhaopeng05:13562 with 1 to fetcher#10
2019-06-13 16:20:30,068 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: assigned 1 of 1 to bi-zhaopeng05:13562 to fetcher#10
2019-06-13 16:20:30,171 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.Fetcher: for url=13562/mapOutput?job=job_1559721784881_0053&reduce=8&map=attempt_1559721784881_0053_m_000000_0 sent hash and received reply
2019-06-13 16:20:30,177 INFO [fetcher#10] org.apache.hadoop.io.compress.CodecPool: Got brand-new decompressor [.snappy]
2019-06-13 16:20:30,180 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.Fetcher: fetcher#10 about to shuffle output of map attempt_1559721784881_0053_m_000000_0 decomp: 30 len: 44 to MEMORY
2019-06-13 16:20:30,182 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput: Read 30 bytes from map-output for attempt_1559721784881_0053_m_000000_0
2019-06-13 16:20:30,183 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 30, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->30
2019-06-13 16:20:30,183 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: EventFetcher is interrupted.. Returning
2019-06-13 16:20:30,184 INFO [fetcher#10] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: bi-zhaopeng05:13562 freed by fetcher#10 in 116ms
2019-06-13 16:20:30,187 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
2019-06-13 16:20:30,192 INFO [main] org.apache.hadoop.mapred.Merger: Merging 1 sorted segments
2019-06-13 16:20:30,192 INFO [main] org.apache.hadoop.mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 25 bytes
2019-06-13 16:20:30,193 INFO [main] org.apache.hadoop.io.compress.CodecPool: Got brand-new compressor [.snappy]
2019-06-13 16:20:30,197 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merged 1 segments, 30 bytes to disk to satisfy reduce memory limit
2019-06-13 16:20:30,197 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merging 1 files, 48 bytes from disk
2019-06-13 16:20:30,197 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
2019-06-13 16:20:30,197 INFO [main] org.apache.hadoop.mapred.Merger: Merging 1 sorted segments
2019-06-13 16:20:30,199 INFO [main] org.apache.hadoop.mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 25 bytes
2019-06-13 16:20:30,259 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2019-06-13 16:20:30,266 INFO [main] com.szh.hadoop.WordCount: reduce方法执行在机器: bi-zhaopeng03/10.1.4.18上
2019-06-13 16:20:30,266 INFO [main] com.szh.hadoop.WordCount: reduce输入数据: cj,org.apache.hadoop.mapreduce.task.ReduceContextImpl$ValueIterable@4218500f
2019-06-13 16:20:30,266 INFO [main] com.szh.hadoop.WordCount: reduce循环: <cj,4>
2019-06-13 16:20:30,266 INFO [main] com.szh.hadoop.WordCount: 本次reduce结束: <cj,4>
2019-06-13 16:20:30,266 INFO [main] com.szh.hadoop.WordCount: reduce方法执行在机器: bi-zhaopeng03/10.1.4.18上
2019-06-13 16:20:30,266 INFO [main] com.szh.hadoop.WordCount: reduce输入数据: dk,org.apache.hadoop.mapreduce.task.ReduceContextImpl$ValueIterable@4218500f
2019-06-13 16:20:30,266 INFO [main] com.szh.hadoop.WordCount: reduce循环: <dk,10>
2019-06-13 16:20:30,267 INFO [main] com.szh.hadoop.WordCount: 本次reduce结束: <dk,10>
2019-06-13 16:20:30,267 INFO [main] com.szh.hadoop.WordCount: reduce方法执行在机器: bi-zhaopeng03/10.1.4.18上
2019-06-13 16:20:30,267 INFO [main] com.szh.hadoop.WordCount: reduce输入数据: tyn,org.apache.hadoop.mapreduce.task.ReduceContextImpl$ValueIterable@4218500f
2019-06-13 16:20:30,267 INFO [main] com.szh.hadoop.WordCount: reduce循环: <tyn,4>
2019-06-13 16:20:30,267 INFO [main] com.szh.hadoop.WordCount: 本次reduce结束: <tyn,4>
2019-06-13 16:20:30,371 INFO [main] org.apache.hadoop.mapred.Task: Task:attempt_1559721784881_0053_r_000008_0 is done. And is in the process of committing
2019-06-13 16:20:30,407 INFO [main] org.apache.hadoop.mapred.Task: Task attempt_1559721784881_0053_r_000008_0 is allowed to commit now
2019-06-13 16:20:30,412 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: Saved output of task 'attempt_1559721784881_0053_r_000008_0' to hdfs://bi-zhaopeng03:8020/tmp/songzehao/words_output/_temporary/1/task_1559721784881_0053_r_000008
2019-06-13 16:20:30,433 INFO [main] org.apache.hadoop.mapred.Task: Task 'attempt_1559721784881_0053_r_000008_0' done.
2019-06-13 16:20:30,533 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping ReduceTask metrics system...
2019-06-13 16:20:30,534 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system stopped.
2019-06-13 16:20:30,534 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system shutdown complete.reduce-00009.log:
2019-06-13 16:20:29,205 INFO [main] org.apache.hadoop.metrics2.impl.MetricsConfig: loaded properties from hadoop-metrics2.properties
2019-06-13 16:20:29,263 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Scheduled snapshot period at 10 second(s).
2019-06-13 16:20:29,263 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system started
2019-06-13 16:20:29,270 INFO [main] org.apache.hadoop.mapred.YarnChild: Executing with tokens:
2019-06-13 16:20:29,270 INFO [main] org.apache.hadoop.mapred.YarnChild: Kind: mapreduce.job, Service: job_1559721784881_0053, Ident: (org.apache.hadoop.mapreduce.security.token.JobTokenIdentifier@59309333)
2019-06-13 16:20:29,324 INFO [main] org.apache.hadoop.mapred.YarnChild: Sleeping for 0ms before retrying again. Got null now.
2019-06-13 16:20:29,497 INFO [main] org.apache.hadoop.mapred.YarnChild: mapreduce.cluster.local.dir for child: /yarn/nm/usercache/hdfs/appcache/application_1559721784881_0053
2019-06-13 16:20:29,636 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
2019-06-13 16:20:29,969 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: File Output Committer Algorithm version is 1
2019-06-13 16:20:29,978 INFO [main] org.apache.hadoop.mapred.Task: Using ResourceCalculatorProcessTree : [ ]
2019-06-13 16:20:30,006 INFO [main] org.apache.hadoop.mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@1a760689
2019-06-13 16:20:30,019 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: MergerManager: memoryLimit=535088320, maxSingleShuffleLimit=133772080, mergeThreshold=353158304, ioSortFactor=64, memToMemMergeOutputsThreshold=64
2019-06-13 16:20:30,020 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: attempt_1559721784881_0053_r_000009_0 Thread started: EventFetcher for fetching Map Completion Events
2019-06-13 16:20:30,027 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: attempt_1559721784881_0053_r_000009_0: Got 1 new map-outputs
2019-06-13 16:20:30,027 INFO [fetcher#8] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: Assigning bi-zhaopeng05:13562 with 1 to fetcher#8
2019-06-13 16:20:30,027 INFO [fetcher#8] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: assigned 1 of 1 to bi-zhaopeng05:13562 to fetcher#8
2019-06-13 16:20:30,130 INFO [fetcher#8] org.apache.hadoop.mapreduce.task.reduce.Fetcher: for url=13562/mapOutput?job=job_1559721784881_0053&reduce=9&map=attempt_1559721784881_0053_m_000000_0 sent hash and received reply
2019-06-13 16:20:30,135 INFO [fetcher#8] org.apache.hadoop.io.compress.CodecPool: Got brand-new decompressor [.snappy]
2019-06-13 16:20:30,139 INFO [fetcher#8] org.apache.hadoop.mapreduce.task.reduce.Fetcher: fetcher#8 about to shuffle output of map attempt_1559721784881_0053_m_000000_0 decomp: 2 len: 16 to MEMORY
2019-06-13 16:20:30,141 INFO [fetcher#8] org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput: Read 2 bytes from map-output for attempt_1559721784881_0053_m_000000_0
2019-06-13 16:20:30,141 INFO [fetcher#8] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 2, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->2
2019-06-13 16:20:30,142 INFO [EventFetcher for fetching Map Completion Events] org.apache.hadoop.mapreduce.task.reduce.EventFetcher: EventFetcher is interrupted.. Returning
2019-06-13 16:20:30,142 INFO [fetcher#8] org.apache.hadoop.mapreduce.task.reduce.ShuffleSchedulerImpl: bi-zhaopeng05:13562 freed by fetcher#8 in 116ms
2019-06-13 16:20:30,145 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
2019-06-13 16:20:30,150 INFO [main] org.apache.hadoop.mapred.Merger: Merging 1 sorted segments
2019-06-13 16:20:30,150 INFO [main] org.apache.hadoop.mapred.Merger: Down to the last merge-pass, with 0 segments left of total size: 0 bytes
2019-06-13 16:20:30,151 INFO [main] org.apache.hadoop.io.compress.CodecPool: Got brand-new compressor [.snappy]
2019-06-13 16:20:30,154 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merged 1 segments, 2 bytes to disk to satisfy reduce memory limit
2019-06-13 16:20:30,155 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merging 1 files, 20 bytes from disk
2019-06-13 16:20:30,155 INFO [main] org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
2019-06-13 16:20:30,155 INFO [main] org.apache.hadoop.mapred.Merger: Merging 1 sorted segments
2019-06-13 16:20:30,157 INFO [main] org.apache.hadoop.mapred.Merger: Down to the last merge-pass, with 0 segments left of total size: 0 bytes
2019-06-13 16:20:30,216 INFO [main] org.apache.hadoop.conf.Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2019-06-13 16:20:30,224 INFO [main] org.apache.hadoop.mapred.Task: Task:attempt_1559721784881_0053_r_000009_0 is done. And is in the process of committing
2019-06-13 16:20:30,251 INFO [main] org.apache.hadoop.mapred.Task: Task attempt_1559721784881_0053_r_000009_0 is allowed to commit now
2019-06-13 16:20:30,256 INFO [main] org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: Saved output of task 'attempt_1559721784881_0053_r_000009_0' to hdfs://bi-zhaopeng03:8020/tmp/songzehao/words_output/_temporary/1/task_1559721784881_0053_r_000009
2019-06-13 16:20:30,270 INFO [main] org.apache.hadoop.mapred.Task: Task 'attempt_1559721784881_0053_r_000009_0' done.
2019-06-13 16:20:30,371 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: Stopping ReduceTask metrics system...
2019-06-13 16:20:30,371 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system stopped.
2019-06-13 16:20:30,371 INFO [main] org.apache.hadoop.metrics2.impl.MetricsSystemImpl: ReduceTask metrics system shutdown complete.好了,到这里我们已经拿到了所需的日志文件,再接下来先熟悉一下MapReduce的理论知识,以便结合实际了解掌握。
熟悉MR理论
熟悉MR的理论,可以去翻看各种书籍和网上资源,如《大数据技术原理与应用》第2版的第7章 - MapReduce,这里则贴出MapReduce的百度百科:
由于篇幅略大,这里贴出其工作原理的部分:
工作原理
下图是论文里给出的流程图。一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。图中执行的顺序都用数字标记了。
MapReduce执行流程图
1.MapReduce库先把user program的输入文件划分为M份(M为用户定义),每一份通常有16MB到64MB,如图左方所示分成了split0~4;然后使用fork将用户进程拷贝到集群内其它机器上。
2.user program的副本中有一个称为master,其余称为worker,master是负责调度的,为空闲worker分配作业(Map作业或者Reduce作业),worker的数量也是可以由用户指定的。
3.被分配了Map作业的worker,开始读取对应分片的输入数据,Map作业数量是由M决定的,和split一一对应;Map作业从输入数据中抽取出键值对,每一个键值对都作为参数传递给map函数,map函数产生的中间键值对被缓存在内存中。
4.缓存的中间键值对会被定期写入本地磁盘,而且被分为R个区,R的大小是由用户定义的,将来每个区会对应一个Reduce作业;这些中间键值对的位置会被通报给master,master负责将信息转发给Reduce worker。
5.master通知分配了Reduce作业的worker它负责的分区在什么位置(肯定不止一个地方,每个Map作业产生的中间键值对都可能映射到所有R个不同分区),当Reduce worker把所有它负责的中间键值对都读过来后,先对它们进行排序,使得相同键的键值对聚集在一起。因为不同的键可能会映射到同一个分区也就是同一个Reduce作业(谁让分区少呢),所以排序是必须的。
6.reduce worker遍历排序后的中间键值对,对于每个唯一的键,都将键与关联的值传递给reduce函数,reduce函数产生的输出会添加到这个分区的输出文件中。
7.当所有的Map和Reduce作业都完成了,master唤醒正版的user program,MapReduce函数调用返回user program的代码。
所有执行完毕后,MapReduce输出放在了R个分区的输出文件中(分别对应一个Reduce作业)。用户通常并不需要合并这R个文件,而是将其作为输入交给另一个MapReduce程序处理。整个过程中,输入数据是来自底层分布式文件系统(GFS)的,中间数据是放在本地文件系统的,最终输出数据是写入底层分布式文件系统(GFS)的。而且我们要注意Map/Reduce作业和map/reduce函数的区别:Map作业处理一个输入数据的分片,可能需要调用多次map函数来处理每个输入键值对;Reduce作业处理一个分区的中间键值对,期间要对每个不同的键调用一次reduce函数,Reduce作业最终也对应一个输出文件。

分析日志
知识储备后,进入到真正的分析总结升华阶段,更多的是对理论的验证。
我们有b3,b4,b5三台机器,其中b3为master,通过查看日志可验证以下几点:
1.MR任务确实由集群中的许多节点机器参与,b4跑main(),b5跑了2次map(),b5跑了5次combine(),b5跑了2次reduce(),b3跑了1次reduce();
2.总共有16个reduce Task,对应16个hdfs上的结果输出文件,尽管有13个算是在空跑;
3.源文本文件默认被一行一行读取,map()的输入数据<k,v>具体代表<某行文本在文件中的偏移位置,对应行的文本内容>,当然也可通过InputFormat来自定义读取方式;
4.map()跑了2次代表源文件被逻辑切分了2片;
5.map()的输出数据<k,v>具体代表<单词字符串,1>;
6. combine()的输入数据<k,vlist>具体代表<单词字符串,1的集合>,证明在combine之前,map()的输出数据被进行了整理,即排序;
7.查看reduce-00008.log第16行,得知,在reduce之前,reduce Worker所在节点会先去对应一个或多个map机器(b5)的磁盘“领取”(Fetch)数据;
8.查看/tmp/songzehao/words_output/part-r-00000,得知,每个reduce任务的输出结果,默认都会以key进行排序;
9.shuffle阶段分为在map和在reduce两部分,包括了sort/partition/combine/merge,可在map.log中发现combine的日志,可在各reduce-000xx.log中看到shuffle的处理日志。
以下是程序流程(暂不详细讨论shuffle):
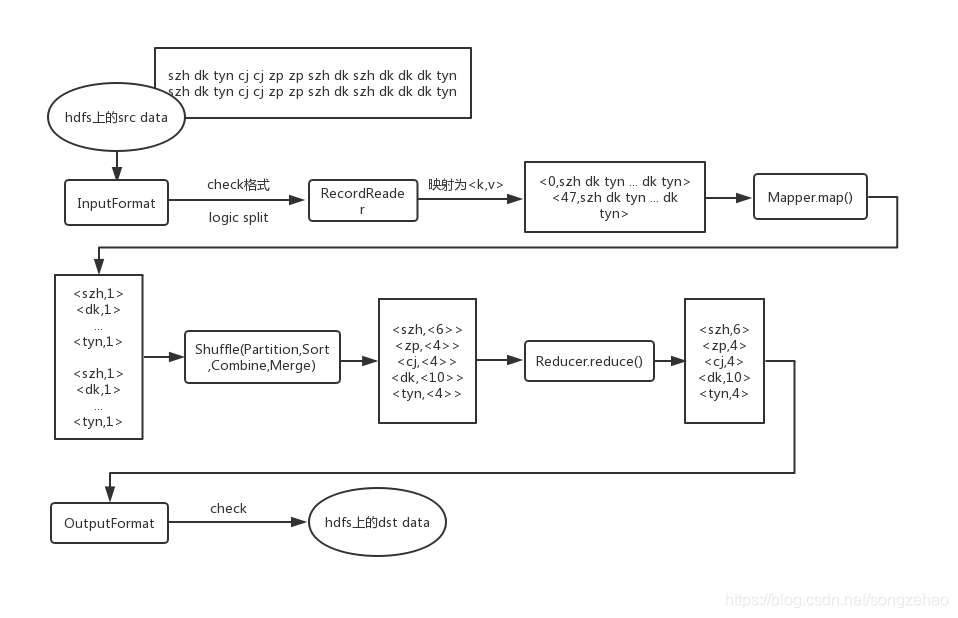
以上只是基于很小数据量下的MR运行的初步了解,若想深扒具体过程,可以阅读《大数据技术原理与应用》章节7.2 - MapReduce的工作流程。
