博客系统:
1 表关系 2 登录验证(基于ajax与用户认证组件) 3 注册 (基于ajax与forms组件) 4 首页文章列表 5 个人站点页面设计 6 点赞与踩灭 7 评论
一
(1)FileField与ImageField
models.py
class userinfo:
avatar = models.FileField(upload_to='avatars/', default="/avatars/default.png")
views.py
avatar=request.FILES.get("avatar_img")
UserInfo.objects.create_user(username=user,password=pwd,email=email,avatar=avatar)
Django会在项目的根目录创建avatars文件夹,将上传文件下载到该文件夹中,avatar字段保存的是文件的相对路径。
(2)设置上传文件存储文件夹
if 配置 MEDIA_ROOT=os.path.join(BASE_DIR,"blog","media")
Django会MEDIA_ROOT下创建avatars文件夹,将上传文件下载到该文件夹中,avatar字段保存的是文件的相对路径。
(3)配置用户上传文件可访问
url.py
# media 配置
url(r'^media/(?P<path>.*)$', serve, {'document_root': settings.MEDIA_ROOT}),
settings.py
MEDIA_URL="/media/"
浏览器可以直接访问http://127.0.0.1:8000/media/avatars/lufei.jpg,即我们的用户上传文件
二
admin:对模型表进行增删改查
admin.py
admin.site.register(UserInfo)
http://127.0.0.1:8000/admin/blog/category/
http://127.0.0.1:8000/admin/blog/category/add/
http://127.0.0.1:8000/admin/blog/category/4/change/
http://127.0.0.1:8000/admin/blog/category/4/delete/
三
表与表之间的关系:一对多,多对多,一对一
book
ID title publish
1 go 苹果出版社
2 python 苹果出版社
3 linux 香蕉出版社
book
ID title publish_id
1 go 1
2 python 1
3 linux 1
Publish
ID name email addr charcher
1 苹果出版社 123 beijing egon
一旦确定是一对多的关系,就得创建关联字段
publish_id
Foreignkey publish_id Refference Publish(ID)
#################################################################
四 分组
1-------
book
ID title publish
1 go 苹果出版社
2 python 苹果出版社
3 linux 香蕉出版社
select count(*),publish from Book group by publish
2-------
book
ID title publish_id
1 go 1
2 python 1
3 linux 2
Publish
ID name email addr charcher
1 苹果出版社 123 beijing egon
2 橘子出版社 123 beijing alex
# 查询每一个出版社对应的书籍个数
select count("title") from Book group by publish_id
# 查询每一个出版社的名字以及对应的书籍个数
select * from book left join publish on book.publish_id=Publish.ID
ID title publish_id ID name email addr charcher
1 go 1 1 苹果出版社 123 beijing egon
2 python 1 1 苹果出版社 123 beijing egon
3 linux 2 2 橘子出版社 123 beijing alex
select Publish.name,count(*) from book left join publish on book.publish_id=Publish.ID group by Publish.ID,Publish.name
ORM分组查询:(annotate():按annotate前面的select字段进行group by)(关键词:每一个)
多表:
Publish.objects.all().annotate(c=Count(book)).values("name","c")
Book.objects.all().annotate(c=Count(authors)).values("title","c")
Author.objects.all().annotate(x=Max(book__prcie))
单表:
Book.objects.all().values("publish").annotate(Count("title"))
'''
1.
ret=Article.objects.all().values("user").annotate(c=Count("title")).values("user_id","c")
SELECT "blog_article"."user_id", COUNT("blog_article"."title") AS "c" FROM "blog_article" GROUP BY "blog_article"."user_id"
2.
ret=Category.objects.filter(blog=blog).annotate(c=Count("article")).values("title","c")
SELECT "blog_category"."title", COUNT("blog_article"."nid") AS "c"
FROM "blog_category" LEFT OUTER JOIN "blog_article"
ON ("blog_category"."nid" = "blog_article"."category_id")
WHERE "blog_category"."blog_id" = 1
GROUP BY "blog_category"."nid", "blog_category"."title", "blog_category"."blog_id"
'''
#####################################################################
文章日期归档
1
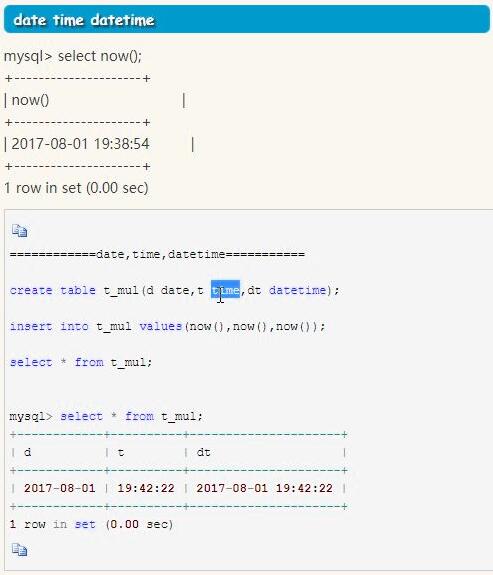
MySQL: date_format
sqlite: striftime
2 extra
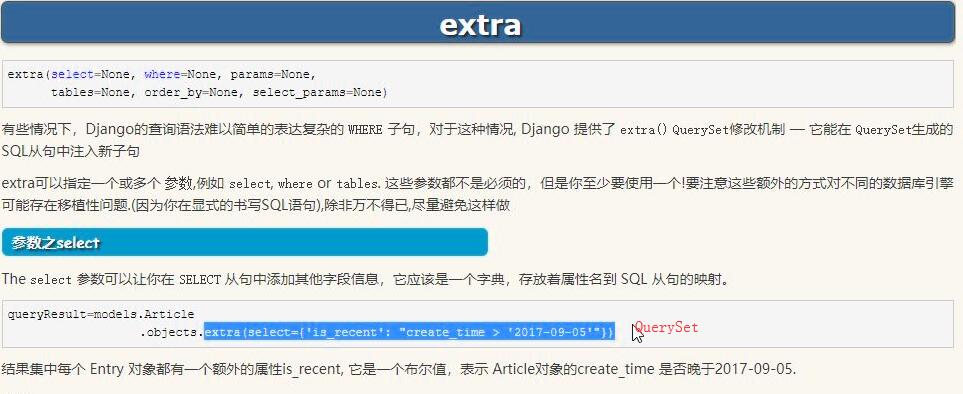
models.Article.objects
.extra(select={"standard_time":"strftime('%%Y-%%m-%%d',create_time)"})
.values("standard_time","nid","title")
3 ORM分组查询(单表)