为什么不直接从源系统写入到Hadoop集群呢?这是因为原系统有成千上万的机器,实时写入到HDFS时,namenode会产生很多小文件,对hadoop压力会非常大。所以引入了中间系统--Flume。Flume真正做的是实时推送事件,数据流是持续且量级很大的情况。
Flume把数据理解成一条条事件。
每个Flume Agent都包含三个主要组件:Source、Channel、Sink,下图是Flume Agent架构图

一、Source组件
是从一些其他产生数据应用中接收数据。有自己产生数据的source,不过这些Source通常用于测试目的。Source可以监听一个或多个网络端口,用于接收数据或者可以从本地文件系统读取数据。每个source必需至少连接一个Channel。
下图是Source、选择器、拦截器的交互过程
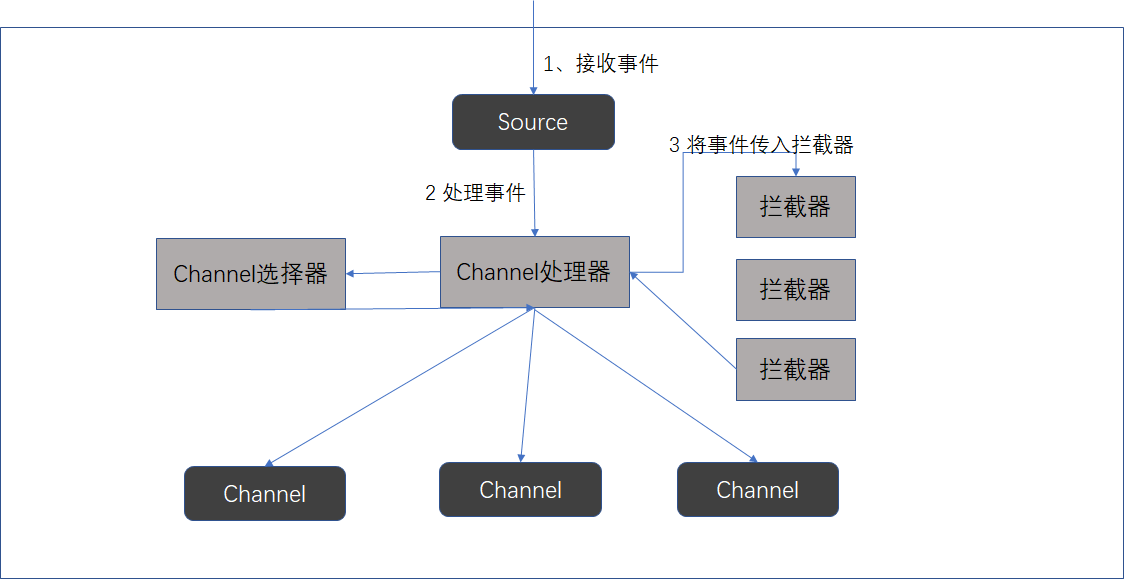
二、Channel
一般来说,channcel是被动组件。sink从channel中读取数据。
三、Sink组件
四、配置Flume Agent
采用属性文件格式
k1 = v1
k2 = v2
在Flume Agent中有一些组件可以有若干实例,像Source、Sink、Channel等,需要对这些组件进行命名。配置文件必需使用下面格式列出Source、Sink、Channel组的名称,该列表称为活跃列表:
agent1.sources = source1 source2
agent1.sinks = sink1 sink2 sink3 sink4
agent1.sinkgroups = sg1 sg2
agent1.channels = channel1 channel2
上面的配置片段表示名为agent1的Flume Agent。带有两个Source,两个Sink组、两个channel、四个sink。