最近因为要使用STM32做毕业设计,需要用LCD显示中文,STM32开发板用的是原子的战舰STM32开发板,给的LCD显示例程里貌似没有中文显示,那么需要自己去编写中文显示程序。
软件编写对我来说并不是什么难事,关键就是在这个过程中遇到了一个非常奇葩的问题。
我用的取模软件是PCtoLCD2002.exe,这在很多地方都能找到。生成字模后,在每一个字模的最后有对应的中文注释,但是将生成的字模复制到程序中发现一个问题,中文显示成了问号,显示如下:

我想,这很简单,无非就是中文编码格式不一样嘛,新建一个文本文档,然后用notepad++打开,将生成的字模粘贴进去,发现可以正常显示:

然后看一下它的编码格式,发现是UTF-8编码:
这意味着在keil5里使用UTF-8编码就可以正常显示了,在keil5菜单栏点击Edit->Configuration:
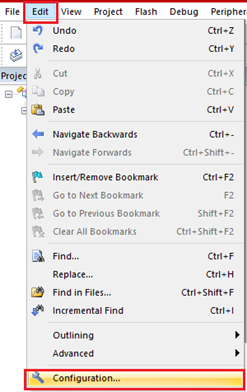
在弹出的框中发现keil5中是用ANSI解码的,现在我们换成UTF-8解码,然后点击OK:
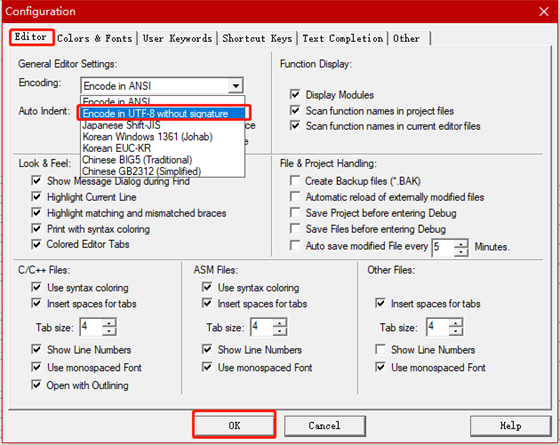
完了之后会发现,刚刚复制过来的字模,中文注释怎么还是一个问号啊,别着急,这是因为,之前将UTF-8的编码内容复制进了ANSI解码的文档中,keil5会将无法解码的部分直接替换成一个问号,也就是说,此时keil5中这个问号并不是乱码,这是一个真真正正的问号啊。(这里有必要提一下,为什么只有中文乱码了而英文和数字没有乱码,那是因为英文和数字都是用ASCLL编码的,而ASCLL码是所有编码的一个子集,也就是说,无论你用什么方式编码,ASCLL码那部分都是不会乱码的。)OK,接下来要解决这个问题也很简单,将复制过来的字模删掉,然后重新粘贴,因为这时keil5已经是用UTF-8解码的了,所以是能够正常显示UTF-8编码的中文了:

等等,我好像发现了什么,虽然复制过来的字模可以显示成中文了,但是之前的中文注释好像乱码了:
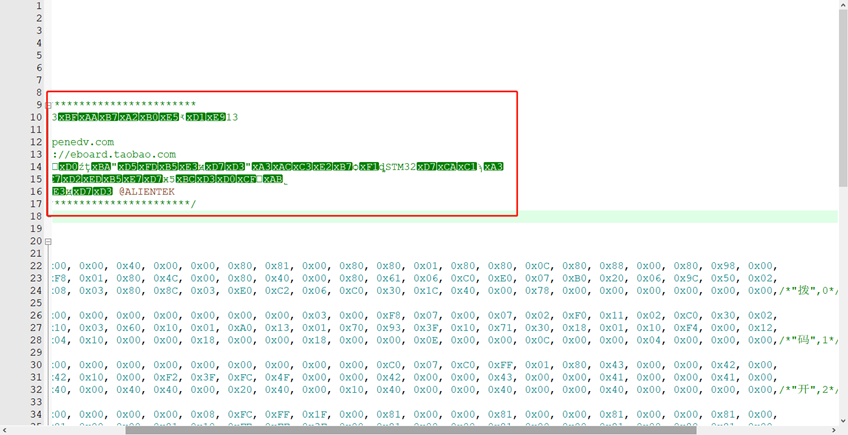
好吧,因为我需要参考很多原子的例程,那么我们还是将keil5的解码方式改回ANSI。那么又如何能正常显示从字模软件里拷贝过来的中文注释呢,很简单,只要转换就好了啊,notepad++就有这个功能。我将拷贝的字模放在新建的文本文档中,然后用notepad++打开,这时可以看到notepad++中用的是UTF-8编码,并且能够正常显示。
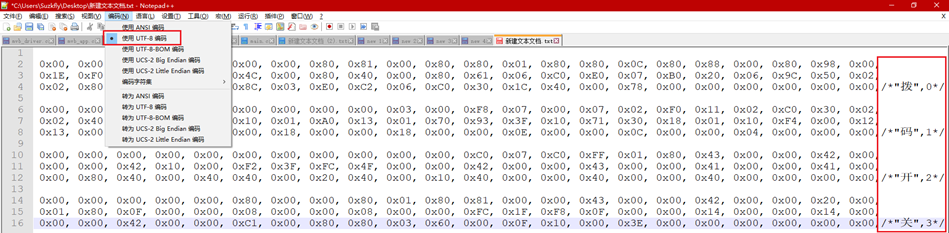
这时我将文件转为ANSI编码:
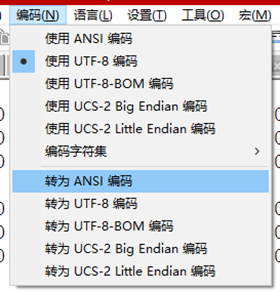
然后再将转换过后的文字复制进keil5,这时迷惑的事情来了,keil5中显示的还是一个问号。经过核对之后能保证在notepad++中使用的已经是ANSI编码了,而且keil5中也是使用ANSI解码的,但为什么keil5中还是显示问号呢,肯定是某个环节有问题。这时我做了个实验,在keil5中将解码方式设置成了UTF-8,然后再将notepad++中以ANSI编码的汉字复制进keil5中,发现能正常显示,这能说明notepad++没有成功转码吗?既然如此,我们再在notepad++上以UTF-8解码,发现在notepad++上不能正常显示中文:

这说明notepad++上的ANSI编码和keil5上的ANSI解码不一致???
经过查阅资料后发现尼玛ANSI真的不是一种统一标准,但他们都会对应一种真实编码,参考:
https://blog.csdn.net/weixin_30216561/article/details/99139847
而在网上搜“ANSI编码表”也确实找不到具体的编码表,这一点也可以佐证ANSI不是一种具体的编码。但还有一个疑问就是,即使ANSI不是一种具体编码,但在同一台电脑上那应该是同一种编码吧。干脆用最直接的方式来验证,notepadd++和keil5中使用的ANSI编码到底对应了哪一种真实编码。我们在notepad++和keil5中打开的文档中都使用ANSI编码,并且删掉所有的内容,只留下一个“拨”字,然后分别保存这两个文件,接下来用另一个强大的工具,winhex来打开他们,我们发现在keil5中编辑的“拨”字和notepad++中编辑的“拨”字,他们对应的编码:


都是B2A6………………….(陷入沉思)
并且可以查到,B2A6如果代表的是汉字的“拨”,那么它对应的真实编码就是GBK编码:

好吧,这让我很惆怅,想来想去,发现中间确实有一环是不严谨的,之前将notepad++和keil5都设置成ANSI编码的时候,我是将notepad++中的字复制到keil5中发现显示问号,这次我是直接在keil5中用键盘打出了“拨”这个字,因此我要将notepad++中的“拨”字复制到keil5中去。操作之后,发现在keil5中,真的就显示成了一个问号,保存keil5中的文件再用winhex查看的时候,发现编码已经变成3F了,而3F正是ASCLL码表中的问号。
OK,既然这样,我将keil5中的“拨”字拷贝到notepad++中会怎样呢。结果,它变成了这样:
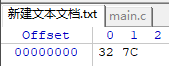
什么?????keil5中用ANSI编码的B2A6复制到notepad++中,notepad++也为ANSI编码,结果却变成了327C?那么B2A6和327C又有什么联系呢。为了进一步验证,我将keil5中的“寒武纪奥陶纪志留纪泥盆纪石炭纪侏罗纪”复制到notepad++中,发现它变成了这样:

进一步验证发现keil5中的一个汉字复制到notepad++中并不一定是2个字节对应2个字节,而且变化后的字节以问号居多,而从notepad++中拷贝到keil5中的汉字则全部变成问号。
总之一句话就是“你没问题,我也没问题,是复制粘贴这个操作有问题”,而且测试发现使用键盘复制和使用鼠标数字是一样的结果。
经过了半个小时的休息,我想问题仍然在ANSI这种特殊编码之上,如果我将编码改为GBK编码,是不是就好了呢,然鹅keil5中没有GBK编码的选项,只有GB2312编码(这里需要提一下的是,GBK编码比GB2312编码收录了更多的汉字,而且可以认为GB2312编码是GBK编码的子集,常用汉字用GB2312编码就够够的了)将keil5中的编码方式改为GB2312。发现原子的例程中文注释并没有乱码,然后在字模软件中将字模复制,在nodepad++中粘贴,注意这时notepad++中使用的是UTF-8编码,然后再转为ANSI编码,然后再复制,再到keil5中粘贴,这时,便不再乱码。
虽然问题解决了,但是用ANSI编码的文件中的汉字不能互相复制粘贴的原因还是没有找到。