任务一:模拟数据
•课程中使用的模拟数据如左表所示,一共25个节点66条边,节点均是数字。
•我们现在需要重新模拟边关系,使用mapreduce生成从1到100共100个节点的边,要求:
•不少于1000条边,且每个节点至少有一条边
•边不能重复(思考利用key不能重复的特点构造,且a,b和b,a是两个边不用去重)
•随机生成边权重,从0-1
•最后的生成结构为“点1,权重,点2”,如:
•1,0.512,5
•2,0.677,8
•2,0.898,188
•…
•999,0.123,763
•100,0.876,552
任务二:改造PeopleRank使之能够接受权重
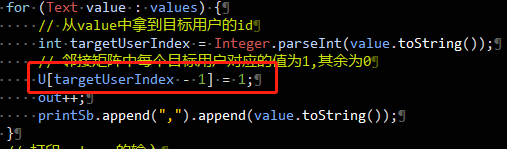
•按照任务一的数据,改造实例工程的代码使之能够实现按照边权重的计算
•提示:PeopleRank中初始化矩阵权重的地方在:
•改造后运行整个工程,生成PeopleRank最终结果
任务三:小型hadoop任务监控系统
•通过自定义计数器,实现一个小型hadoop任务监控系统,能够监控以下几个指标:
•监控器名字(对应groupName)叫MYCOUNTER
•各个计数值(对应counterName):
•Map任务读了多少行:map-read
•Map写了多少行:map-write
•Reduce读了多少个key:reduce-read-key
•Reduce读了多少个value:reduce-read-value
•Reduce输出了多少行:reduce-write
•运行wordcount工程,将屏幕显示在计数器的输出页面上检查,以检查顺序记录成绩
任务四:按照key的长度排序
•改造WordCount工程,使得该工程能够按照key的长度而不是字典序排序
•检查:以老人与海的文章为输入,检查最终的结果
