3.1 概述
人类学习一个领域的知识一般是从该领域的词汇和术语开始的。比如,对于知识图谱领域的学习,就要从对“关系提取”“词汇挖掘”“实体识别”等领域词汇的理解开始。一旦机器具备了领域词汇的识别能力,就可以代替人类从事一些简单的知识工作。可以说,对领域词汇的识别与理解是机器理解一个领域的前提和基础。
从图模型的角度来看,构建知识图谱的第一步是获取图谱中的实体。知识图谱中实体的获取主要分为两大步:
- 第一步,从文本语料中挖掘出尽可能多的高质量词汇;
- 第二步,从这些词汇中选出目标知识图谱所需的实体。
本章所述的词汇挖掘与传统图书情报领域的叙词表建设极为相关。叙词表又被称为主题词表,是一个针对特定学科领域的词汇表,也可以是涉及多个学科领域的综合性词汇表。该词表由一些语义相关的规范性名词术语组成。除了领域词汇(又被称为主题词)外,叙词表还包括词与词之间的等价关系、等级关系或相关关系等内容。
传统图书情报领域的叙词表建设往往依赖领域专家,以手工构建为主,但随着大数据时代的到来,领域语料日积月累,为基于统计方法的词汇挖掘提供了方便。采用自动化方法挖掘与构建叙词表对于当前的应用而言是必须的。
3.2 领域短语挖掘
短语挖掘一般应用于构建领域知识图谱,用于发现领域相关的短语,进而找到其中领域相关的实体。
领域短语挖掘的输入是领域语料,输出是领域短语。 需要说明的是,早期将这项工作称为词汇挖掘(Glossary Extraction),现在也使用短语挖掘(Phrase Mining)来描述。
3.2.1 问题描述
领域短语挖掘指的是从给定的领域语料(将大量的文档融合在一起组成一个语料)中自动挖掘该领域的高质量短语的过程。
在给定文档中,一个高质量短语是指连续出现的单词序列,也就是 ,其本质上是一个N-Gram,其中N指短语长度。比如,“support vector machine”的1-Gram有“support” “vector” “machine”,2-Gram有“support vector” “vector machine”,3-Gram有“support vector machine”。对于中文段短语挖掘, 可以是词(比如,“中山大学”可以认为是由“中山”与“大学”构成的词序列),也可以是字符。对于短语的质量,我们一般从下面几个角度来评估。
- 频率。一般来说,一个N-Grame在给定的文档集合中要出现得足够频率才能被视作高质量短语。
- 一致性。一致性指的的N-Grame的搭配频率明显高于其各部分偶然组合在一起的可能性,即反应的是N-Grame中不同单词的搭配是否合理或者是否常见。
- 信息量。一般来说,一个高质量短语应该传达一定的信息,即表达一定的主题或者概念。
- 完整性。一个高质量短语还必须在特定的上下文中是一个完整的语义单元。
领域短语挖掘和隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)主题模型的区别在于:
- LDA主题模型的输入若干篇文档,输出是每篇文档的主题分布和每个主题的词分布,根据这两个分布可以得到每篇文档中词的分数。LDA关注的是主题下字(词)的分布,并不关心如何得到短语。
- 领域短语挖掘的输入不区分多篇文档,而是直接将它们合并成一个大文档,输出的是该领域的高质量短语。
领域短语挖掘和关键词抽取的区别在于: 关键词抽取是从语料中抽取最重要、最有代表性的短语,抽取的短语数量一般比较小。
领域短语挖掘和新词发现的区别在于: 新词发现主要目标是发现词汇库中不存在的新词汇,而领域短语挖掘不区别新短语和词汇库中已有的短语。新词发现可以通过领域短语挖掘的基础上进一步过滤已有词汇表来实现。
3.2.2 领域短语挖掘方法
早期的短语挖掘主要基于规则来挖掘名词性短语。最直接的方法是通过预定义的词性标签(POS Tag)规则来识别文档中的高质量名词短语。但规则一般是针对特定领域手工设计的,存在一定的局限性,如下:
- 一方面,人工定义的规则通常适用于特定领域,难以适用于其他领域。
- 另一方面,人工定义规则代价高昂,难以穷举所有的规则,因此在召回率存在一定的局限性。
近年来,利用短语的统计指标特征来挖掘词汇成为主流方法之一。基于统计指标的领域短语挖掘方法可以分为无监督学习和监督学习两大类方法。无监督学习适用于缺乏标注数据的场景,监督学习适用于有标注数据的场景。
无监督方法主要通过计算候选短语的统计指标特征来挖掘领域短语,主要流程如下图所示,包括以下几步。
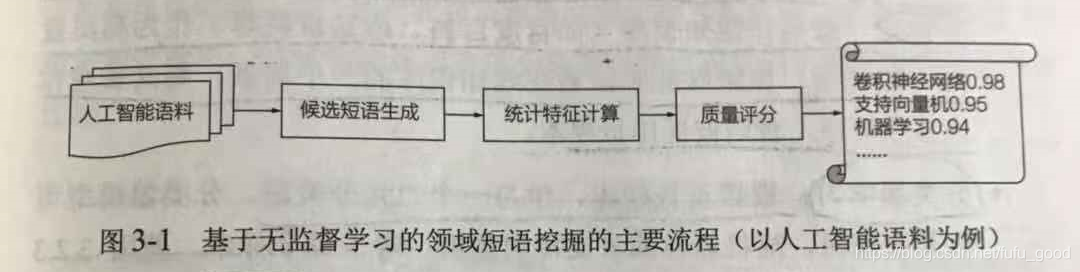
(1)候选短语生成:这里的候选短语就是高频的N-Grame(连续N个字/词序列)。首先设定N-Grame出现的最低阈值(阈值和语料大小成正比),通过频繁模式挖掘得到出现次数大于或等于阈值的N-Grame作为候选短语。
(2)统计特征计算:根据语料计算候选短语的统计指标特性,如TF-IDF(频率-逆文档频率)、PMI(点互信息)、左邻字熵以及右邻字熵等。
(3)质量评分:将这些值融合得到候选短语的最终分数,用该分数来评估短语的质量。
(4)排序输出:对所有候选短语按照分数由高到低排序,通常取前K个短语或者取根据阈值筛选出来的短语作为输出。
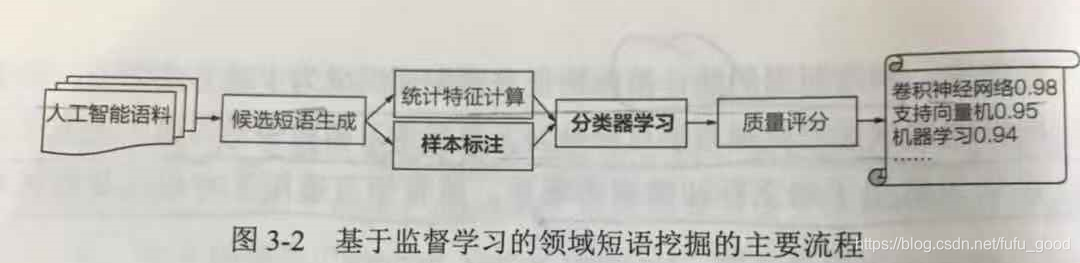
基于监督学习的领域短语挖掘在无监督方法的基础上增加了两个步骤(其主要流程如 下图所示):样本标注和分类器学习。前者负责构造训练样本,后者根据样本训练一个二元分类器以预测候选短语是否是高质量的短语。
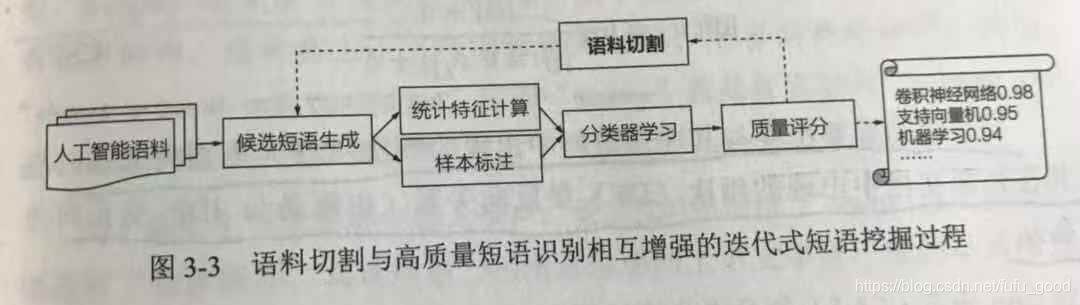
基于监督学习的领域短语挖掘方法经过优化后,采用迭代式计算框架,在迭代的每一轮先后进行语料切割和统计指更新,其过程如下图所示。
3.2.3 统计指标特征
1. TF-IDF
首先可以采用TF-IDF(Term Frequency-Inverse Document Frequency,即词频-逆文档频率)方法来评估短语质量。TF-IDF一般用来评价一个短语在语料中的重要性。考虑到通用词汇(比如“的” “是”等等)通常在外部文档中也有很高的频率出现,但是领域词汇在外部文档中出现的频率则要低很多,因此通常引入逆文档频率来识别领域特有的高质量短语。如果某个短语在领域语料中频繁出现但是在外部文档中很少出现,则该短语很可能是该领域的高质量词汇。
TF-IDF形式化地表达为TF乘以IDF。对于某个词汇
,其TF值定义为语料中该词汇出现的频次(
)除以该语料中所有词汇的累计词频,如公式(3-1)所示。IDF定义为外部文档总数除以包含该词汇的外部文档数(通常使用比值的对数形式);为了避免外部文档中从未出现某个词汇所导致的分母为0的异常情况,一般会在IDF公式的分子和分母上加一个非零正常数
进行平滑处理,如公式(3-2)所示。其中,
是第
篇外部文档,|D|是外部文档总数。
一个词的重要程度与其在该语料中出现的频次(TF)呈正向关系,与其在外部文档出现的频次(DF)呈反向关系(也就是与IDF呈正向关系)。
2.C-value
C-Value在词频基础上还考虑了短语的长度,以及父子短语对于词频统计的影响。公式(3-3)给出了其具体的定义。
在公式(3-3)中,
是用来奖励较长的短语的,
是u的所有父短语,
是父短语的数量。同时u可能存在多个父短语,故公式的第二个式子中减去了短语u的父短语出现的平均频次,以消除因父短语重复计数所带来的偏差。
3. NC-value
NC-value在C-value的基础上,考虑候选短语
的上下文单词
的影响,如公式(3-4)所示,其中
指的是b作为u的上下文出现的次数,weight(b)是衡量b的重要性的权重。
为了避免上下文单词中混入噪声,可以先通过C-value值对候选短语进行排序,再选取前5%候选短语的上下文中所出现的单词作为b。上下文单词b的重要性值weight(b)可以定义为公式(3-5),其中n是前5%候选短语的数量,t(b)是前5%候选短语与单词b在文中共同出现的次数。
4. PMI
PMI(Pointwise Mutual Information,点互信息)值刻画了短语组成部分之间的一致性(Concordance)程度。假设某个短语u由
与
两部分组成,
与
的PMI值越大,u越可能是
与
的一个有意义的组合。PMI用公式(3-6)来计算:
当u="电影院"且
=“电影”、
="院"时,
分别表示语料中“电影”与“院”独立出现的概率,
表示“电影院”出现的概率。如果
与
在语料中的出现相互独立的,那么
。如果
远大于
,也就是联合出现的概率远远大于两者在独立情况下随机共现的概率,说明这两个部分的共现是一个有意义的搭配,预示这两者应该组成一个有意义的短语而非纯粹偶然共现。
一个候选短语往往存在多种拆分方式。同一个候选短语所有可能的拆分方式下得到的PMI值往往不同。因此,需要枚举候选短语所有可能的拆分方式,一般取最小的PMI值作为该短语的最终PMI值(此时 是各种拆分方式下的最大值,即 本身都是最常见的单词或短语)。
5. 左邻字熵与右邻字熵
一个好的短语应该有着丰富的左右搭配,即好的短语应该有着丰富的左邻字集合与右邻字集合。反之,如果左右邻字总是某一词汇,则预示着其自身不是好的短语。
左邻字熵与右邻字熵用来刻画短语的自由运用程度,即用来衡量一个词的左邻字集合与右邻字集合的丰富程度。 熵表达了事件的不确定性(随机性),熵越大则不确定程度越高。给定某候选短语u,其左(右)邻字熵用公式(3-7)来计算:
其中,p(x)为某个左(右)邻字x出现的概率,
是u的所有左邻(右邻)字的集合。一般而言,我们希望一个候选短语的左邻字熵和右邻字熵都叫较大,最后选择左邻字熵与右邻字熵中较小值来衡量该短语的质量。
统计指标特征小结

3.3 同义词挖掘
3.3.1 概述
同义词指意义相同或相近的词。同义词的主要特征是它们在语义上相同或相似。语言中的同义关系十分复杂,同义关系至少包含以下几类。
- 不同国家的语言互译。例如,“汽车”对应的英文为“car”。
- 具有相同含义的词。例如,男生与男孩,枯萎与干枯。
- 中国人的字、名、号、雅称、尊称、官职、谥号等。例如,宋太祖与赵匡胤,苏轼与苏东坡、周杰伦与周董。
- 动植物、药品、疾病等的别称或俗称。例如,番茄与西红柿、小儿麻痹症与骨髓灰质炎。
- 简称。例如,福建省简称为“闽”。
需要注意的是,同义词表达的是词汇之间的语义相似性,而不是相关性。比如,猫和狗十分相关,但是它们显然不是同义词。
3.3.2 典型方法
1. 基于同义词资源的方法
已有的同义词资源主要来自字典、网络字典以及百科词条。其中字典中的同义词资源是经由专家手工整理而成的,通常质量较高,但难以完整收入(因为人力成本太高)。近年来,随着网络百科的发展,互联网上的知识资源日益丰富,维基百科、百度百科成了新的同义词来源。从同义词资源挖掘得到的同义词往往只包含书面用语,收录不完整,这是该方法的缺点所在。
首先介绍字典和网络字典,典型的字典资源包括WordNet、汉语大词典等。通过查询一个词在这些字典中的同义词,便可以挖掘其同义词,这种方面简单有效,但挖掘出的词条偏向书面用语。
类似的,通过查询百科词条,也可以获得一个词汇的同义词。常见的百科词条资源有维基百科、百度百科等。通过爬取一个词汇的百科词条页面,并分析其Infobox中的信息,便可以获取同义词。这种方法挖掘出来的同义词通常质量较高,并且百科词条往往覆盖了各领域的词汇,覆盖面很全。以百度百科词条“彼岸花”为例,如下图所示,可以提取“拉丁学名”,“别称”属性。

2. 基于模式匹配的方法
基于模式匹配的方法利用同义词在句子中被提及的文本模式从句子中挖掘同义词。首先需要定义同义词抽取的模式(Pattern),常见的中文模式如下表所示。
| 模式(X、Y表示一组同义词) | 举例 |
|---|---|
| X又称Y | 番茄又称西红柿 |
| X(Y) | 明太祖(朱元璋),摩拜(Mobike) |
| X简称Y | 巴塞罗那简称巴萨 |
| X,亦称Y | 计量,亦称测量 |
| X,别名Y | 曼珠沙华,别名彼岸花 |
| X的全称是Y | 皇马的全称是皇家马德里 |
| X,俗称Y | 骨髓灰质炎,俗称小儿麻痹症 |
基于模式匹配的同义词挖掘通常具有较高的准确率,但在召回率方面存在局限性。此外还有以下局限性:
- 很多同义词对在文本中没有明显的表达模式,甚至很少在句子中同时出现。比如,谦虚与谦逊是同义词,但是文本中很少同时出现,类似“小明是一个很谦虚,又称谦逊的人”的句子不太可能出现。
- 不同语言。不同语料中的同义关系的表达模型也不尽相同,很难穷举各种同义关系的表达模式。
- 每个新语料都需要花费大量的人力手工定义匹配模式,代价十分高昂。
3. 自举法
自举法是对基于模式匹配的方法的改进,从一些种子样本或者预定义模式出发,不断地从语料中学习同义词在文本中的新表达模式,从而提高召回率。自举法是一个循环迭代的过程,每轮循环发现新模式、召回新同义词对,循环往复直至达到终止条件。下图是自举法的基本流程。
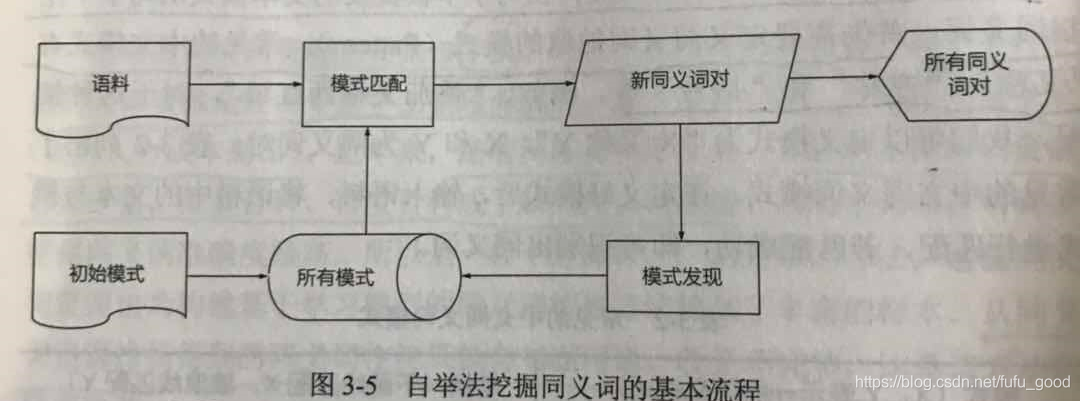
自举法可以自动挖掘新模式。新模式召回了更多的同义词对,因此提高了召回率。但是自动学习获得的新模式的质量难以得到保证,导致挖掘出的同义词对的准确率有所下降。有各种方法可以解决自举法模型枚举的质量问题,一种直接的方法是对模式质量进行评估。
4. 其他方法
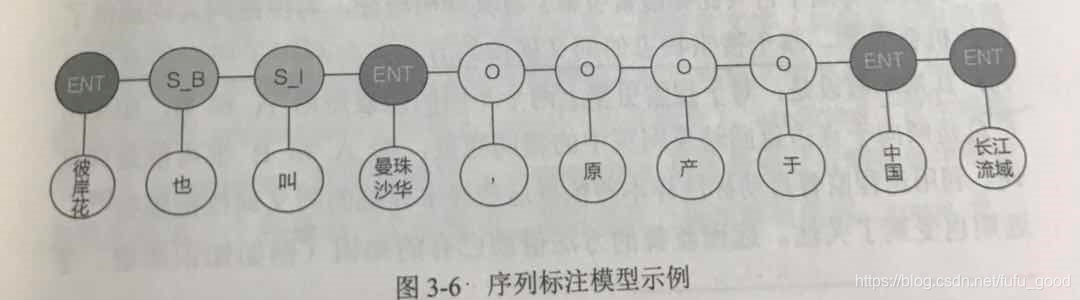
一类是借助序列标注模型自动挖掘同义词的文本描述模式。比如,定义“ENT”表示实体,“S_B”表示模式开始的位置,“S_I”表示模式继续的位置,“O”表示其他成分。基于标注好的文本数据,通过序列标注模式学习出新的模式。例如,对于句子“彼岸花也叫曼珠沙华,原产于中国长江流域”,通过序列标注模式可以得到下图标注结果,并且发现了“也叫”这种新的表达同义关系的模型。
另一类是基于图模型挖掘同义词。基于词与词之间的各种相似性可以构建一张词汇关联表。同义词在图上往往呈现出“抱团”的结构特性。也就是同义词之间关联紧密,不同义的词之间关系稀疏。这个特性就是复制网络中的社团结构。
上述思路的第一步是构造由词汇组成的语义关联图。可以通过:计算每对词语相应的词向量之间的余弦相似度,如果相似度大于特定阈值,在图中添加边。下一步就是计算图上的划分。存在多种划分节点的方式,显然我们希望找到划分内尽可能紧密且划分间尽可能稀疏的划分方式。划分的好坏可以通过模块度进行度量。因此,可以通过模块度对图进行划分。模块度(Modularity)的定义如下:
其中
是节点i和节点j之间边的权重,边不带权时,边权可以看作1,
表示i的度,
表示节点i所属的社团,
表示所有边的数目。
表达了节点i和节点j之间存在一条边在统计意义下的显著性。
此外,有些平台(比如搜索引擎)有其鲜明特征,为挖掘同义词提供了新的机会。基于搜索日志的同义词挖掘方法充分利用了用户的点击行为,其基本假设是:对于搜索引擎上两个不同的搜索短语A和B,如果用户总是倾向于点击返回结果页面中的相同页面,则A和B很可能是同义词。
3.4 缩略词抽取
缩略词(Abbreviation)是同义词的一种重要形式,也是自然语言中常见的现象之一。缩略词表达一个词汇的缩略形式。
3.4.1 缩略词的概念与形式
缩略词指的是一个词或者短语的缩略形式。缩略词的英文“Abbreviation”出自拉丁语,原意同“short”。缩略词广泛存在于英文、中文等各种不同的语言中。缩略词通常由原词中的一些组成部分构成,同时保持原词含义。
在不同语言中,缩略词的形式有所不同。介绍缩略词在一些表音(字母)文字(如拉丁语系)以及一些表意文字(如中文)中的形式。
(1)表音(字母)文字
以拉丁语系为例,缩略词形式包括contractions(简称)、crasis(元音融合)、acronyms(首字母缩写)和initialisms(首字母缩写)。拉丁语系中不同类别的缩略词形式如下:

(2)表意文字
这类文字常常不存在词边界,在自然语言处理中依赖分词算法来对其词边界进行划分。缩略词往往是从每个词中选取一个或者对个字组成,剩下的那些字则直接省略。中文缩略词的主要形式如下图所示。

3.4.2 缩略词的检查与抽取
缩略词的检测及抽取方法以模式匹配为主。但是,自动抽取的结果常常包含大量噪声。为了解决抽取的结果中存在大量噪声的问题,可以利用统计信息结合各类机器学习方法来对抽取结果进行清洗。
1. 基于文本模式的抽取
在缩略词抽取中常见的基于文本模式的抽取规则如下图所示。

2. 抽取结果的清洗和筛选
有两种方法:
- 利用数据集有关缩写的统计指标进行识别,如频率(包括原词出现频率、缩略词出现频率以及原词与缩略词共现频率等形式)、卡方检验、互信息以及最大熵等;
- 使用机器学习模型构建二元分类模型(可采用支持向量机、逻辑回归等模型),以此判断抽取出的缩略词正确与否。
两者优缺点:单纯利用统计信息的缩略词识别方法能够准确识别常见的缩略词模式,但对于长尾模式的识别往往效果较差;而机器学习模型通常具有一定的泛化能力,因此能够适应不同文本和不同领域,对低频缩略词模式的识别能力更强,但对训练数据和训练模型的依赖也更强。
3. 枚举并剪枝
枚举并剪枝方法的输入是语料以及某个确定实体。这一方法首选穷举目标实体名称所有子序列即所有可能的缩略形式,进一步排除没有在文本中出现过的或者出现次数太少的候选缩略词。由于缩略词和原词往往会出现在相似的语境中,因此可以通过构建下图所示的候选缩略词与高频词的共现图来对候选缩略词打分,最终得出“港大”作为“香港大学”的缩略词可能性最大。

3.4.3 缩略词的预测
1. 基于规则的方法
虽然缩略词的形式没有统一的标注,但仍然存在一些缩略词生成规则,这些规则大致分为两种。一种是针对特定字符和词语形式的局部规则,大致包括如下规则。
(1)基于词性:如数字常常被保留(“厦门市第一中学”——“厦门一中”)
(2)基于位置:如国家名往往用第一个字作为简称(“中国”——“中”)
(3)基于词与词之间的相互关联:如相邻的同类型词往往会各保留一部分,例如,在“中日友好协会”中,“中国”和“日本”最为同类型词采用了相同的缩略,对应的缩略词为“中日友协”
第二种是依赖语言环境的全局规则。例如,我们知道“中大”一般指的是“中山大学”,因此在预测“中南大学”时需要避开结果“中大”。
2. 条件随机场(CRF)
绝大多数的缩略词都由全称中包含的字符组成,并且字符间的顺序会保留。缩略词的这一特性使得序列标注模型成为可能。条件随机场(CRF)是较早用于进行缩略词生成的序列标注模型。
3. 深度学习
在神经网络中,词或字符被表示为一个低维稠密空间中的向量。基于这些向量表示,可使用典型的网络结构【如卷积神经网络(CNN)、循环神经网络(RNN)】抽取字词之间的组合特征。与传统的手工特征的方法相比,深度神经网络能捕捉到更多隐性的语义特征,在训练数据充足的情况下深度神经网络模型往往能取得更优异的性能。下图展示了一种典型的用于缩略词预测的深度神经网络模型,其主体结构为长短期记忆网络(LSTM)。
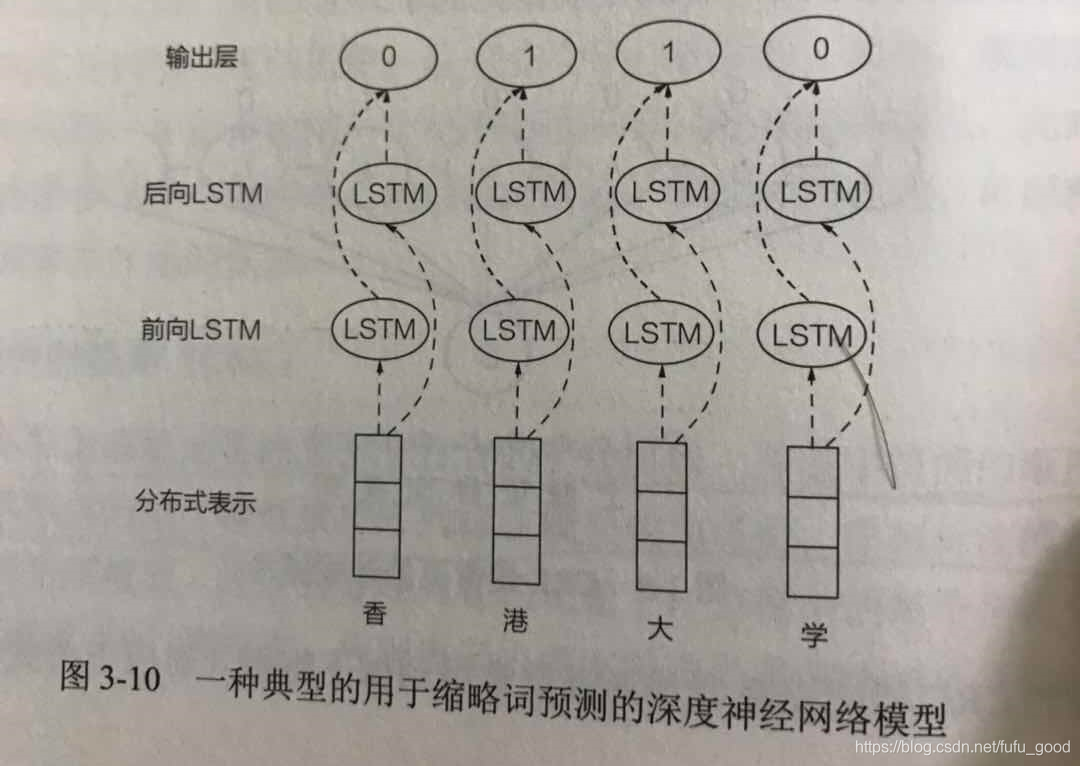
深度神经网络模型常常需要使用预训练好的词向量来提升模型的性能。对于中文缩略词问题而言,字符本身的语义和字符在整个词语中的语义常常存在很大的区别。在中文相关的处理中,通常要将字符级向量表示及词汇级向量表示等不同粒度的语言信息输入到深度神经网络中,才能取得较好的效果。
3.5 实体识别
实体是知识图谱最重要的组成,命名实体识别(Named Entity Recognition,NER)对于知识图谱构建具有重要意义。
3.5.1 概述
命名实体是一个词或短语,它可以在具有相似属性的一组事物中清楚地标识出某一事物(例如,小明和一群朋友,可以使用“小明”这个命名实体清楚的从一群人中标识出小明这个人)。命名实体识别(NER) 则是指在文本中定位命名实体的边界并分类到预定义类型集合的过程。实体是一个认知概念,指代世界上存在的某个特定事物。命名实体可以理解为有文本标识的实体。实体在文本中的表示形式通常被称作实体指代(Mention,或者直接被称为指代)。比如林俊杰,在文本中有时被称作“JJ Lin”,有时又被称作“JJ”。
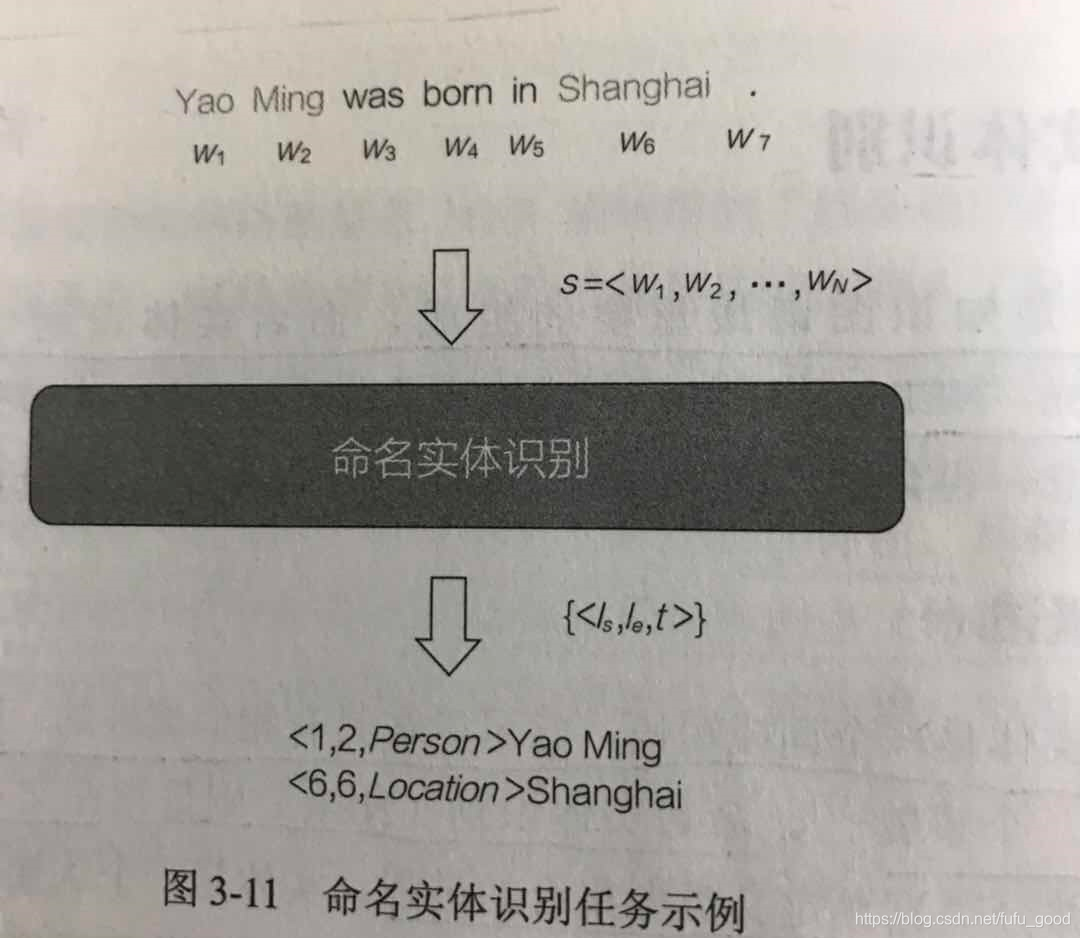
NER的输入是一个句子对应的单词序列
,输出是一个三元组集合,其中每个元组形式为
,表示s中的一个命名实体,其中
和
分别表示命名实体在s中的开始和结束位置,而t是实体类型。如下图所示,对于输入序列“Yao Ming was born in Shanghai”,NER会识别并输出<1,2,Person>(对应实体Yao Ming)和<6,6,Location>(对应实体Shanghai)。
命名实体识别可以分为:
- 粗粒度命名实体识别(Coarse-grained Entity Typing):预定义实体类型集合较小,并且为每个命名实体只分配一种类型。
- 细粒度命名实体识别(Fine-grained Entity Typing):预定义实体类型集合较大,一个实体可以被分类到多个类型标签。
3.5.2 传统的NER方法
传统的NER方法主要分为三类:基于规则、词典和在线知识库的方法,监督学习方法和半监督学习方法。
1. 基于规则、词典和在线知识库的方法
这类方法是早期常见的NER方法。它们基于规则、词典和在线知识库,依赖语言学专家手工构造规则。通常每条规则都会被赋予权值,当遇到规则冲突的时候,选择权值最高的规则来判断命名实体的类型。
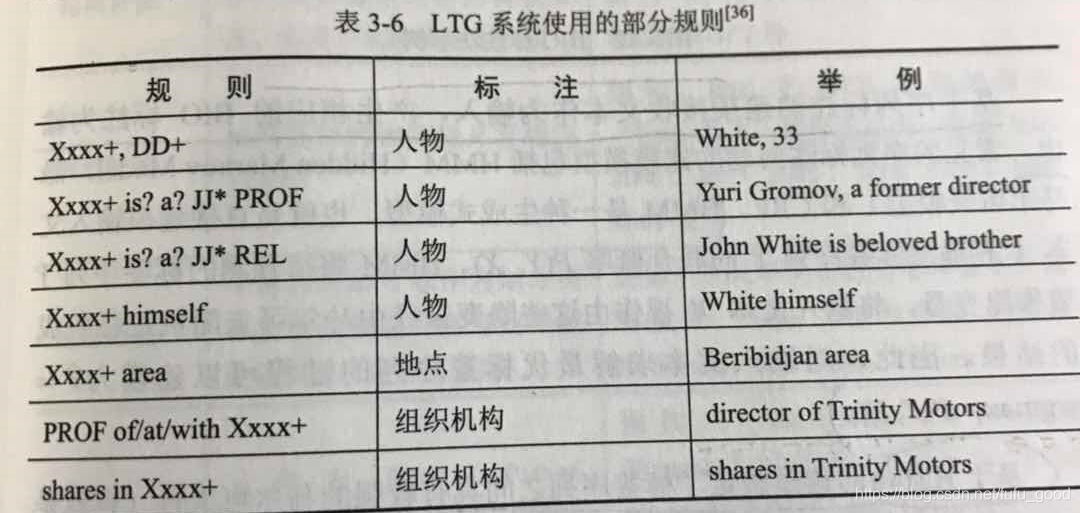
比较著名的基于规则的NER系统包括:LaSIE-II、NetOwl、Facile、SRA、FASTUS和LTG等系统。这些系统主要基于人工制定的语义和句法规则来识别实体,LTG系统使用的部分规则如下图所示(其中,“Xxxx+”代表大写单词序列,“DD”代表数字,“PROF”代表职业,“REL”代表人物关系,“JJ*”代表形容词序列)。基于规则的实体识别系统往往还需要借助实体词典,对候选实体进一步的确认。当词典详尽无遗时,基于规则的系统效果很好。但是基于特定领域的规则和并不完整的词典,往往会导致NER系统有着较低的召回率,而且这些规则难以应用到其他领域。
这一方法无须认为定义模式,也无须标注样本,有时也被归类到无监督学习方法中。无监督学习方法更多被用于NER任务中确定实体类别的部分。
2. 监督学习方法
当应用监督学习方法时,NER被建模为序列标注问题。NER任务使用BIO标注法。BIO标注法是NER任务常用的标注法,其中B表示实体的起始位置,I表示实体的中间或结束位置,O表示相应字符不是实体。如下图所示,B-PER表示这个字符是一个人物命名实体的起始位置,I-PER表示相应字符为人物实体的中间或结束位置;类似的,B-LOC与I-LOC代表地点名的起始位置和中间或结束位置。
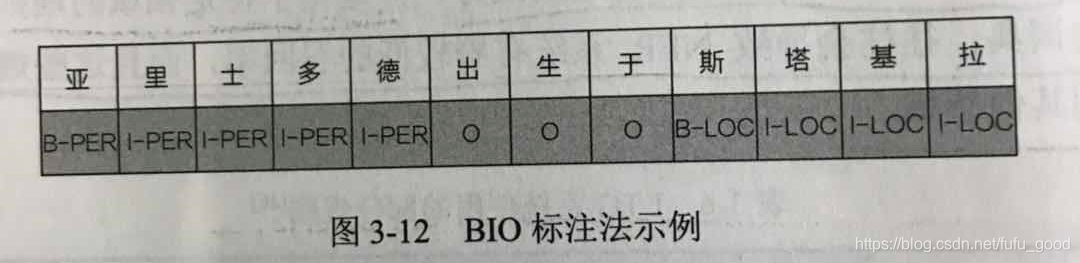
基于序列标注的建模接收文本作为输入,产生相应的BIO标注为输出。常见的序列标注问题的建模模型包括:HMM(Hidden Markov Model,隐马尔可夫模型)和CRF(条件随机场)。
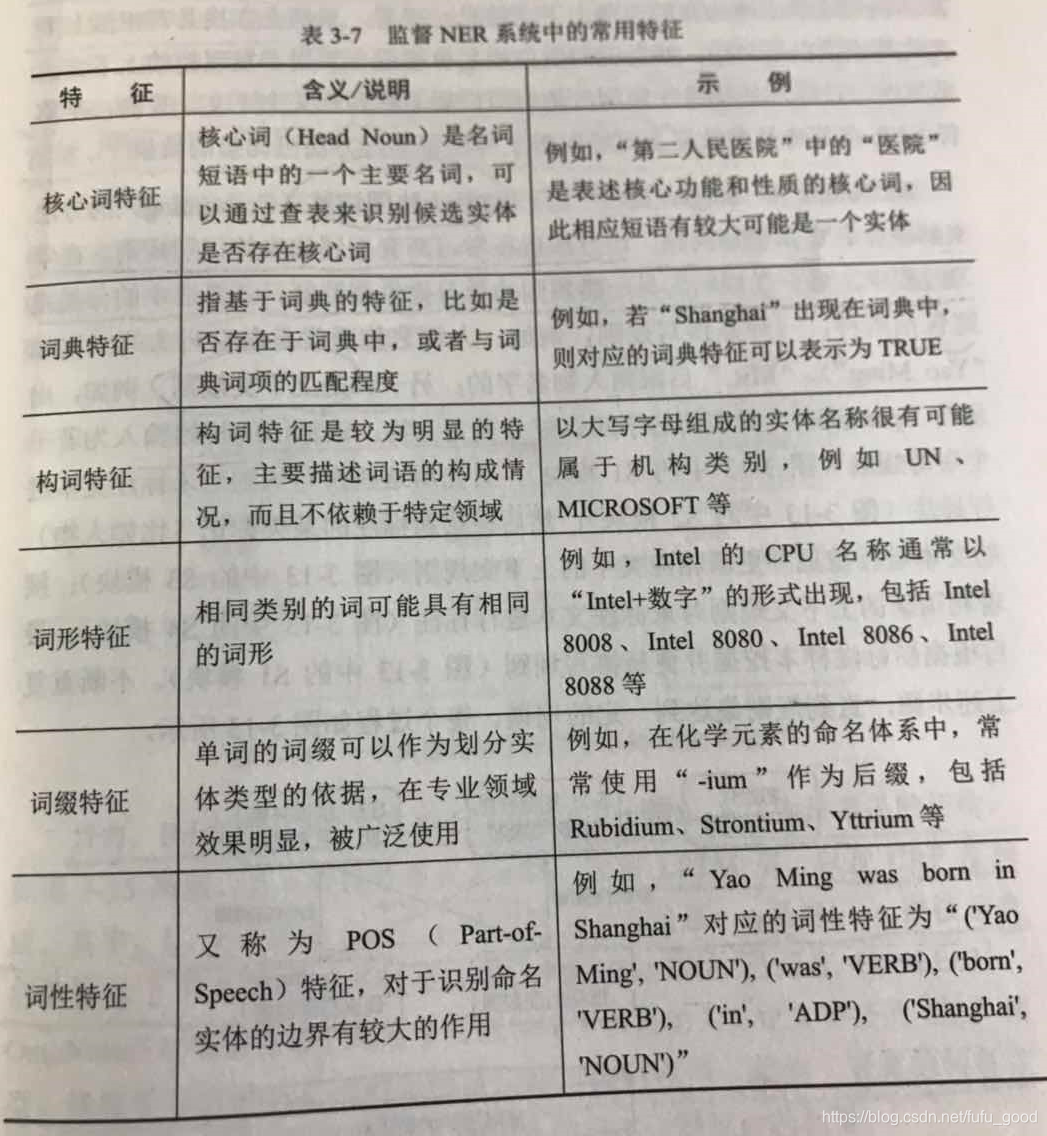
基于监督学习的NER方法从大规模序列标注样本习得文本的实体标注模式,再利用这一模式对新的句子进行标注。NER系统常会用到以下几类典型特征:
- 单词级别的特征(如词法、词性标签)
- 列表查找特征(如维基百科地名录、DBpedia地名字典)
- 文档和语料特征(如语法、共现)
下图给出了这些特征的具体说明:
3. 半监督学习方法
一类典型的半监督学习方法是自举法,通常从少量标注数据、大量未标注数据和一小组假设或分类器开始,迭代生成更多的标注数据,直至达到某个阈值。目前,半监督NER在某些类型数据上已经取得了与监督学习方法可比拟的效果。
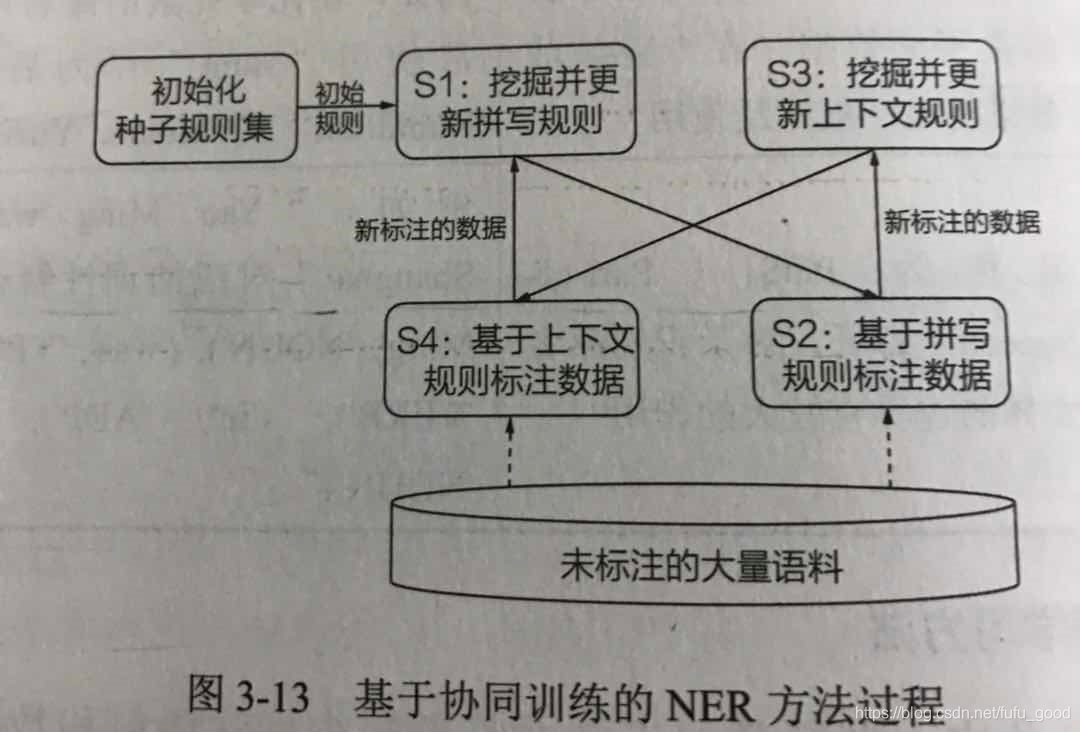
还有一些人(Michael Collins and Yoram Singer(点击需要翻墙))提出了一种协同训练(Co-training) 的方法来解决命名实体识别问题。该方法旨在学习两套不同的实体识别规则。在学习过程中,每一类规则为另一类规则的学习提供弱监督。该算法中的分类规则包括两种:
- 拼写规则,。例如,人物名称通常以首字母大写(比如“Yao Ming”),“MR.”后跟随人物名称。
- 上下文规则。例如,出现在“president”周围的名字应该被分类为人物。
基于协同训练的NER方法过程如下图所示(顺序:S1->S2->S3->S4->S1 不断重复直到达到一定规模)。
3.5.3 基于深度学习的NER方法
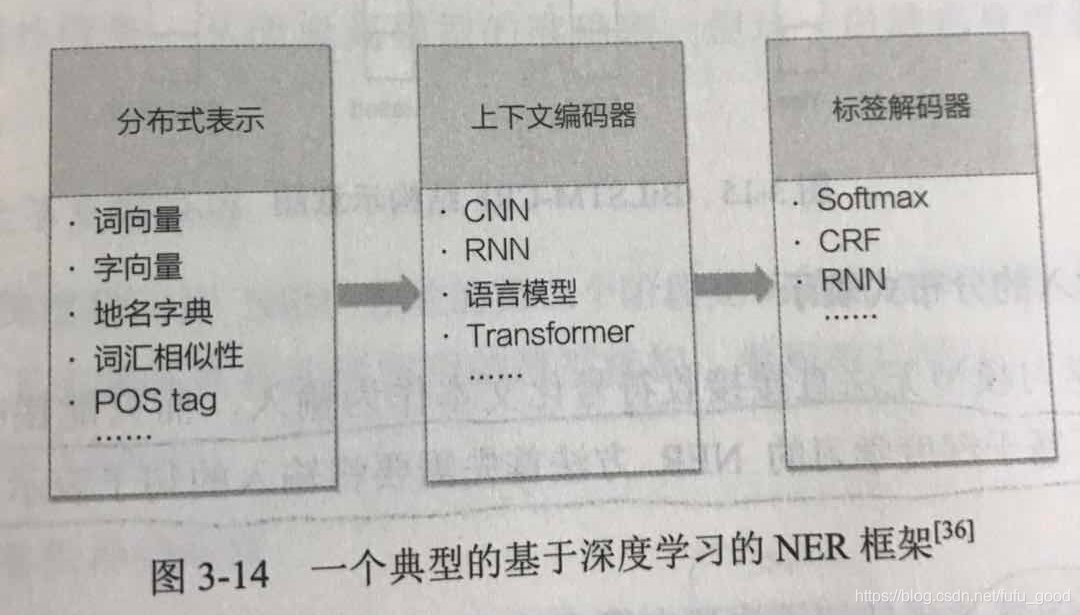
基于深度学习的方法通常将NER问题建模为序列标注的问题。相比于基于传统机器学习的NER模型,基于深度学习的NER方法无须人工制定规则或者繁琐的特征,易于从输入提取隐含的语义信息,灵活且便于迁移到新的领域或其他语言。在NER任务中,常用的深度神经网络有循环神经网络(RNN)和卷积神经网络(CNN),其中CNN主要用于向量特征学习,RNN则可以同时用于向量特征学习和序列标注。RNN中的长短期记忆网络(LSTM)目前已被广泛地应用在NER任务中。
一个典型的基于深度神经网络的NER框架如下图所示。
目前,BiLSTM-CRF是基于深度学习的NER方法中最常见的架构,如下图所示。其中,
分别表示
左右两边的上下文信息,
是将
拼接起来后的整体上下文信息。
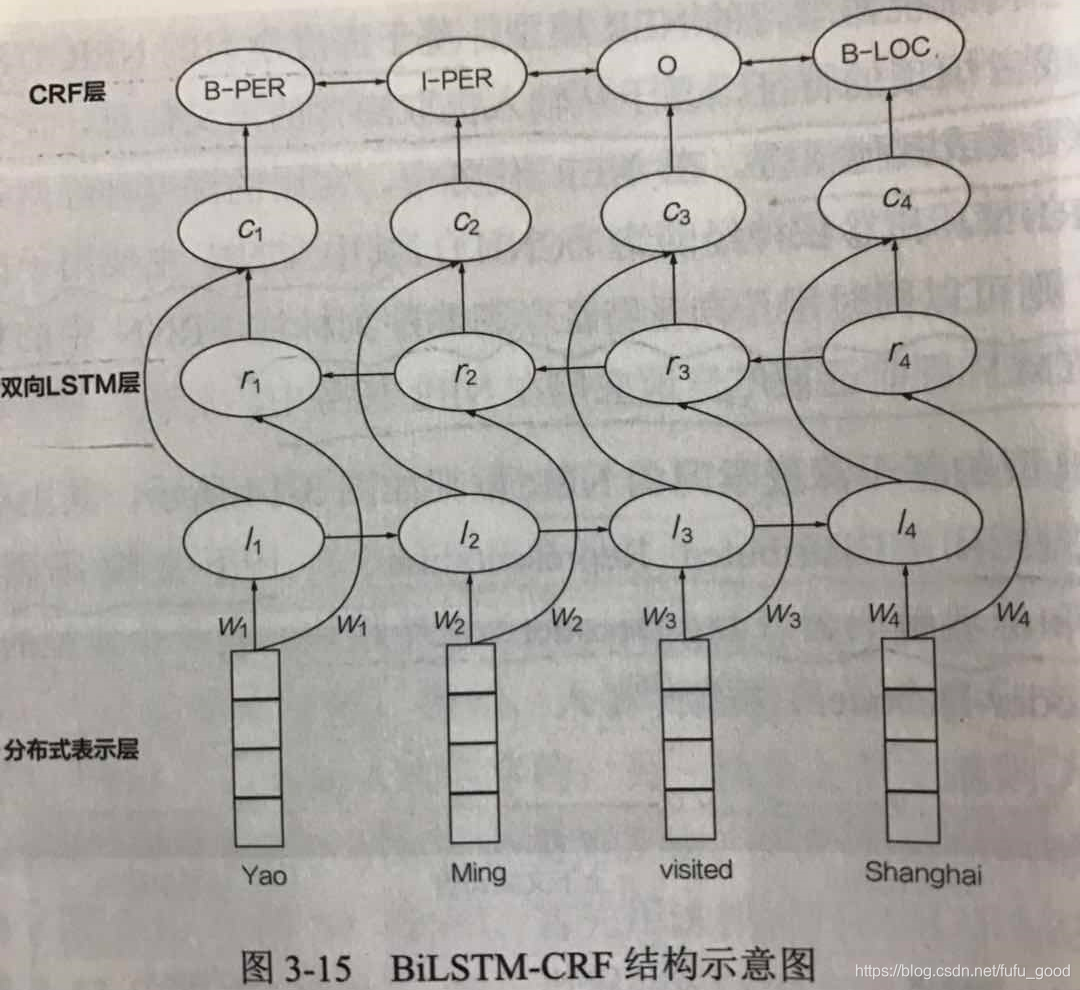
3.5.4 近期的一些方法
1. 注意力机制
NER模型将输入句子编码成一个固定长度的向量表示,对于长度较短的输入句子而言,该模型能够学习到合理的向量表示。然而当输入句子非常长时,输入的表示学习就非常困难。但对于实际任务而言,对结果的显著影响的往往是输入句子中的部分数据。因此,人们引入注意力机制(Attention Mechanism)来解决这一问题。注意力机制使得神经网络能够专注于其输入的特定子集,捕获输入中对NER任务而言最有效的元素。
2. 迁移学习
迁移学习(Transfer Learning)旨在将源域(通常样本丰富)学到的知识迁移到目标域(通常样本稀缺)上执行机器学习任务。
在迁移学习中,源任务和目标任务通常通过共享神经网络参数和特征表示实现知识迁移,利用神经网络的通用性来提高目标任务的性能。
