第一部分 Python快速入门
第1周 Python基本语法元素
编译:将源代码一次性转换成目标代码的过程(使用编译执行的编程语言叫静态语言,如C/C++,Java)
解释:将源代码逐条转换成目标代码同时逐条运行的过程(使用解释执行的编程语言叫脚本语言,如Python,JavaScript,PHP )
程序的基本编写方法:IPO
编程步骤:分析问题、划分边界(确定IPO)、设计算法、编写程序、调试测试、升级维护
编程体现了一种抽象交互关系、自动化执行的思维模式——计算思维(区别于逻辑思维、实证思维)
掌握语法、熟悉基本概念和逻辑 > 思考程序结构、使用编程套路 > 练习实践、举一反三
33个保留字:

数据类型:整数、浮点数、字符串、列表
赋值语句右侧的数据类型同时作用于变量
评估函数eval()去掉参数最外侧引号并执行余下语句:如eval("1+2")输出3,eval('“1+2”')输出'1+2'
第2周 Python基本图形绘制

- C/C++:Python归Python,C归C
- Java:针对特定开发和岗位需求
- HTML/CSS/JS:不可替代的前端技术,全栈能力
- 其他语言:R/Go/Matlab等,特定领域
Python计算生态 = 标准库 + 第三方库
- 标准库:随解释器直接安装到操作系统中的功能模块
- 第三方库:需要经过安装才能使用的功能模块
- 库Library、包Package、模块Module,统称模块
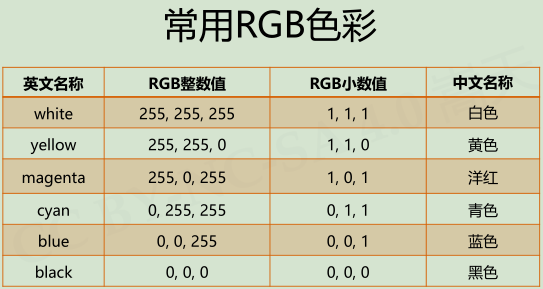
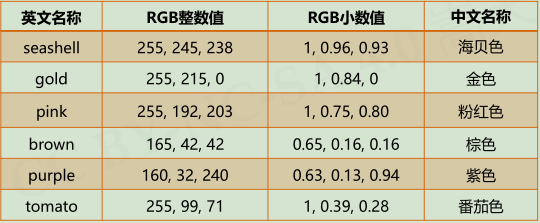
turtle库一些常用函数:
turtle.penup() 别名 turtle.pu():抬起画笔,海龟在飞行
turtle.pendown() 别名 turtle.pd():落下画笔,海龟在爬行
turtle.pensize(width) 别名 turtle.width(width):画笔宽度,海龟的腰围
turtle.pencolor(color):color为颜色字符串或r,g,b值,画笔颜色,海龟在涂装
pencolor(color)的color参与可以有三种形式
- 颜色字符串 :turtle.pencolor(“purple”)
- RGB的小数值:turtle.pencolor(0.63, 0.13, 0.94)
- RGB的元组值:turtle.pencolor((0.63,0.13,0.94))
turtle.forward(d) 别名 turtle.fd(d):向前行进,海龟走直线
turtle.circle(r, extent=None):根据半径r绘制extent角度的弧形
turtle.setheading(angle) 别名 turtle.seth(angle):改变行进方向,海龟走的角度,angle: 行进方向的绝对角度
turtle.left(angle) 海龟向左转,turtle.right(angle) 海龟向右转, angle: 在海龟当前行进方向上旋转的角度
第二部分 Python基础语法
第3周 基本数据类型
3.1 数字类型及操作
浮点数间运算存在不确定尾数,不是bug:
- round(x, d):对x四舍五入,d是小数截取位数
- 浮点数间运算及比较用round()函数辅助
- 不确定尾数一般发生在1e-16 左右,round()十分有效
数学思维 > 计算思维
数值运算操作符:
x // y 整数除,x与y之整数商 10//3结果是3
x % y 余数,模运算 10%3结果是1
x ** y幂运算,x的y次幂
数值运算函数:
divmod(x,y):商余,(x//y, x%y),同时输出商和余数
round(x[, d]):四舍五入,d是保留小数位数,默认值为0,round(-10.123, 2) 结果为 -10.12
int(x):将x变成整数,舍弃小数部分,int(123.45) 结果为123; int(“123”) 结果为123
float(x):将x变成浮点数,增加小数部分,float(12) 结果为12.0; float(“1.23”) 结果为1.23
3.3 字符串类型及操作
转义符形成一些组合,表达一些不可打印的含义:"\b"回退 "\n"换行(光标移动到下行首) "\r" 回车(光标移动到本行首)
字符串操作符:
x + y 连接两个字符串x和y
n * x 或 x * n 复制n次字符串x
x in s 如果x是s的子串,返回True,否则返回False
str(x)返回任意类型x所对应的字符串形式,与eval()对应
hex(x) 或 oct(x)整数x的十六进制或八进制小写形式字符串
字符串处理方法:

<a>.<b>()是面向对象的一种使用风格,<a>是对象,<b>是对象能提供的功能,称为方法。方法必须要用.的形式来执行。

字符串类型的格式化:<模板字符串>.format(<逗号分隔的参数>)
槽内部对格式化的配置方式:{ <参数序号> : <格式控制标记>}


3.4 模块2: time库的使用

time()获取当前时间戳,即计算机内部时间值,浮点数,>>>time.time() 1516939876.6022282
ctime()获取当前时间并以易读方式表示,返回字符串, >>>time.ctime() ‘Fri Jan 26 12:11:16 2018’
gmtime()获取当前时间,表示为计算机可处理的时间格式, >>>time.gmtime() time.struct_time(tm_year=2018, tm_mon=1,tm_mday=26, tm_hour=4, tm_min=11, tm_sec=16,tm_wday=4, tm_yday=26, tm_isdst=0)
strftime(tpl, ts)tpl是格式化模板字符串,用来定义输出效果,ts是计算机内部时间类型变量,>>>t = time.gmtime() >>>time.strftime(“%Y-%m-%d %H:%M:%S”,t) ‘2018-01-26 12:55:20’
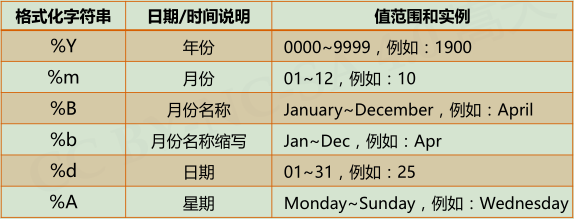
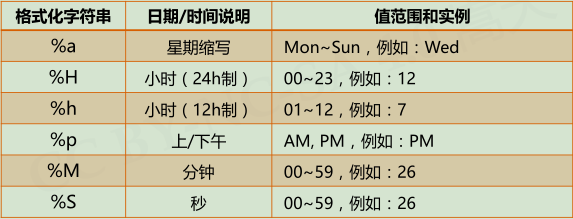
strptime(str, tpl)str是字符串形式的时间值,tpl是格式化模板字符串,用来定义输入效果,>>>timeStr = ‘2018-01-26 12:55:20’ >>>time.strptime(timeStr, “%Y-%m-%d %H:%M:%S”) time.struct_time(tm_year=2018, tm_mon=1,tm_mday=26, tm_hour=4, tm_min=11, tm_sec=16,tm_wday=4, tm_yday=26, tm_isdst=0)
perf_counter()返回一个CPU级别的精确时间计数值,单位为秒,由于这个计数值起点不确定,连续调用差值才有意义 >>>start = time.perf_counter() 318.66599499718114
sleep(s)s拟休眠的时间,单位是秒,可以是浮点数
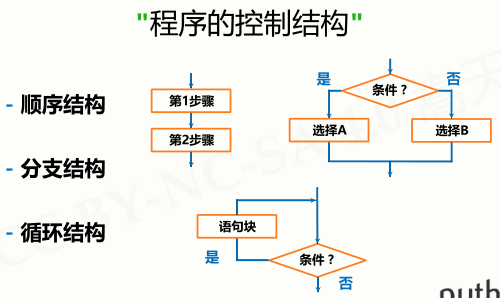
第4周 程序的控制结构
4.1 程序的分支结构
异常处理:

4.3 程序的循环结构
for <循环变量> in <遍历结构> :从遍历结构中逐一提取元素,放在循环变量中,遍历循环:计数、字符串、列表、文件…
for i in range(N) : #计数循环(N次)
for i in range(M,N,K) : #计数循环(特定次)
for c in s : #字符串遍历循环
for item in ls : #列表遍历循环
for line in fi : #文件遍历循环, fi是一个文件标识符,遍历其每行,产生循环while <条件> :无限循环
循环控制保留字:continue退出当次循环,break退出当前循环
4.4 模块3: random库的使用
random库包括两类函数,常用共8个
- 基本随机数函数: seed(), random()
- 扩展随机数函数: randint(), getrandbits(), uniform(), randrange(), choice(), shuffle()
seed(a=None)初始化给定的随机数种子,默认为当前系统时间
random()生成一个[0.0, 1.0)之间的随机小数
choice(seq)从序列seq中随机选择一个元素
shuffle(seq)将序列seq中元素随机排列,返回打乱后的序列
第5周 函数和代码复用
5.1 函数的定义与使用
可选参数要赋初值
可变参数传递:函数定义时可以设计可变数量参数,即不确定参数的总数量
def <函数名>(<参数>, *b ) : #*b为可变参数
<函数体>
return <返回值>局部变量和全局变量:
规则1: 局部变量和全局变量是不同变量
- 局部变量是函数内部的占位符,与全局变量可能重名但不同
- 函数运算结束后,局部变量被释放
- 可以使用global保留字在函数内部使用全局变量
规则2: 局部变量为组合数据类型且未创建,等同于全局变量
lambda函数:<函数名> = lambda <参数>: <表达式>,表达式相当于函数体
5.2 实例7: 七段数码管绘制
理解方法思维
- 模块化思维:确定模块接口,封装功能
- 规则化思维:抽象过程为规则,计算机自动执行
- 化繁为简:将大功能变为小功能组合,分而治之
5.3 代码复用与函数递归
把代码当成资源进行抽象
- 代码资源化:程序代码是一种用来表达计算的”资源”
- 代码抽象化:使用函数等方法对代码赋予更高级别的定义
- 代码复用:同一份代码在需要时可以被重复使用
函数 和 对象 是代码复用的两种主要形式
函数:将代码命名,在代码层面建立了初步抽象
对象:属性和方法,<a>.<b> 和 <a>.<b>(),在函数之上再次组织进行抽象
函数递归:
- 函数 + 分支结构
- 递归链条
- 递归基例
#汉诺塔
count = 0
def hanoi(n, src, dst, mid):
global count
if n == 1 :
print("{}:{}->{}".format(1,src,dst))
count += 1
else :
hanoi(n-1, src, mid, dst)
print("{}:{}->{}".format(n,src,dst))
count += 1
hanoi(n-1, mid, dst, src)5.4 模块4: PyInstaller库的使用
PyInstaller库:将.py源代码转换成无需源代码的可执行文件
使用:(cmd命令行) pyinstaller -F <文件名.py>
常用参数:
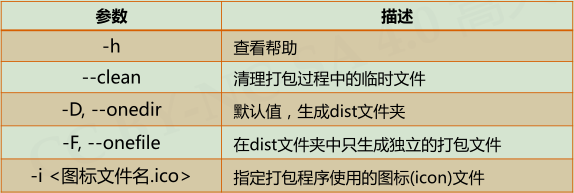
pyinstaller –i curve.ico –F SevenDigitsDrawV2.py
5.5 实例8: 科赫雪花小包裹
#KochDrawV2.py
import turtle
def koch(size, n): # n阶科赫曲线的绘制函数
if n == 0:
turtle.fd(size)
else:
for angle in [0, 60, -120, 60]:
turtle.left(angle)
koch(size/3, n-1)
def main(): # n阶科赫雪花的绘制函数
turtle.setup(600,600)
turtle.penup()
turtle.goto(-200, 100)
turtle.pendown()
turtle.pensize(2)
level = 3 # 3阶科赫雪花,阶数
koch(400, level)
turtle.right(120)
koch(400, level)
turtle.right(120)
koch(400, level)
turtle.hideturtle()
main()
# 在cmd中执行以下代码,打包绘制程序
pyinstaller –i curve.ico –F KochDrawV2.py # 使用图标curve.ico包装第6周 组合数据类型
6.1 集合类型及操作
可变数据类型:列表、字典
非可变数据类型:整数、浮点数、复数、字符串、集合、元组
建立集合类型用 {} 或 set() ,建立空集合类型,必须使用set()
**集合操作符:**6个操作符和4个增强操作符
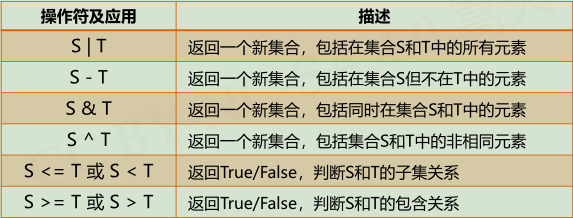

集合处理方法:


# while也可以遍历组合数据类型
try:
while True:
print(A.pop(), end=""))
except:
pass数据去重:集合类型所有元素无重复:
>>> ls = ["p", "p", "y", "y", 123]
>>> s = set(ls) # 利用了集合无重复元素的特点
{'p', 'y', 123}
>>> lt = list(s) # 还可以将集合转换为列表
['p', 'y', 123]6.2 序列类型及操作
序列类型通用操作符:

序列类型通用函数和方法:

元组是序列类型的一种扩展
- 使用小括号 () 或 tuple() 创建,元素间用逗号 , 分隔
- 可以使用或不使用小括号
列表是序列类型的一种扩展,十分常用
- 使用方括号 [] 或list() 创建,元素间用逗号 , 分隔
- 列表中各元素类型可以不同,无长度限制
方括号 [] 真正创建一个列表,赋值仅传递引用
列表类型操作函数和方法:


6.3 实例9: 基本统计值计算
# 获取多数据输入:从控制台获取多个不确定数据的方法
def getNum(): #获取用户不定长度的输入
nums = [] #创建空列表用以保存数据
iNumStr = input("请输入数字(回车退出): ")
while iNumStr != "":
nums.append(eval(iNumStr))
iNumStr = input("请输入数字(回车退出): ")
return nums
# 通过函数分隔功能6.4 字典类型及操作
字典类型是“映射”的体现
- 字典是键值对的集合,键值对之间无序
- 采用大括号{}和dict()创建,键值对用冒号: 表示
字典类型操作函数和方法:

d.keys()和d.values()返回的不是列表类型,而是一种dict_keys类型和dict_values类型,可以用for...in...遍历,不能当做列表操作
d.items()返回一种dict_items类型,包括字典d中所有键值对

6.5 模块5: jieba库的使用
jieba是优秀的中文分词第三方库
- jieba库提供三种分词模式,最简单只需掌握一个函数
jieba分词的三种模式:
- 精确模式:把文本精确的切分开,不存在冗余单词
- 全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式基础上,对长词再次切分
jieba库常用函数:
jieba.lcut(s):精确模式,返回一个列表类型的分词结果
jieba.lcut(s,cut_all=True):全模式,返回一个列表类型的分词结果,存在冗余
jieba.lcut_for_search(s):搜索引擎模式,返回一个列表类型的分词结果,存在冗余
6.6 实例10: 文本词频统计
#CalHamletV1.py Hamlet英文词频统计
def getText(): # 文本去噪及归一化
txt = open("hamlet.txt", "r").read()
txt = txt.lower()
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~':
txt = txt.replace(ch, " ")
return txt
hamletTxt = getText()
words = hamletTxt.split()
counts = {}
for word in words:
counts[word] = counts.get(word,0) + 1 #使用.get()方法统计词频
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True) #按value从大到小排列
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))#CalThreeKingdomsV2.py 《三国演义》人物出场统计
import jieba
txt = open("threekingdoms.txt", "r", encoding="utf-8").read()
excludes = {"将军","却说","荆州","二人","不可","不能","如此"} #定义排除词集合
words = jieba.lcut(txt) #使用jieba库分词
counts = {}
for word in words: #需要根据结果进一步优化
if len(word) == 1:
continue
elif word == "诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长":
rword = "关羽"
elif word == "玄德" or word == "玄德曰":
rword = "刘备"
elif word == "孟德" or word == "丞相":
rword = "曹操"
else:
rword = word
counts[rword] = counts.get(rword,0) + 1
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
#《三国演义》人物出场顺序前20:曹操、孔明、刘备、关羽、张飞、吕布、赵云、孙权、司马懿、周瑜、袁绍、马超、魏延、黄忠、姜维、马岱、庞德、孟获、刘表、夏侯惇词频统计进阶:词云
第7周 文件和数据格式化
7.1 文件的使用
文件是数据的抽象和集合
- 文件是存储在辅助存储器上的数据序列,是数据存储的一种形式
- 文件展现形态:文本文件和二进制文件。文件文件和二进制文件只是文件的展示方式,本质上,所有文件都是二进制形式存储
文本文件由单一特定编码组成,如:.txt文件、.py文件等
二进制文件直接由比特0和1组成,没有统一字符编码,如:.png文件、.avi文件等
文件处理的步骤: 打开-操作-关闭
文件的打开:


打开模式:

文件的关闭:

文件内容的读取:
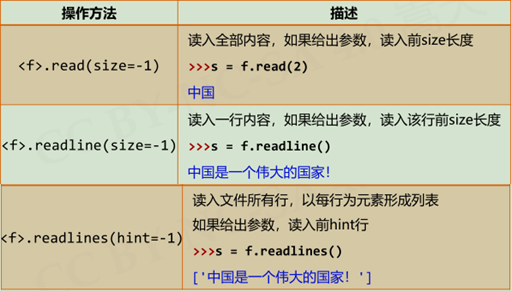
#遍历全文本:方法二
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
txt = fo.read(2)
while txt != "": # 按数量读入,逐步处理
#对txt进行处理
txt = fo.read(2)
fo.close()#逐行遍历文件:方法二
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
for line in fo: #分行读入,逐行处理
print(line)
fo.close()数据的文件写入:
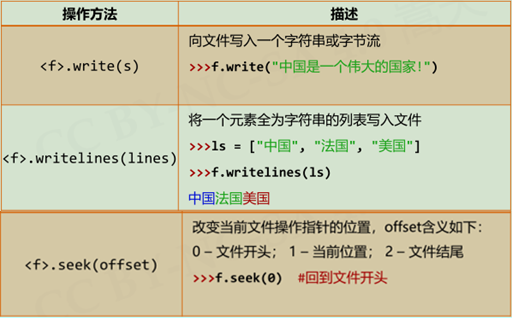
fo = open("output.txt","w+")
ls = ["中国", "法国", "美国"]
fo.writelines(ls) # 写入一个字符串列表
fo.seek(0) #使指针回到文件开头
for line in fo:
print(line) #>>>中国法国美国
fo.close()7.2 实例11: 自动轨迹绘制
- 步骤1:定义数据文件格式(接口)
- 步骤2:编写程序,根据文件接口解析参数绘制图形
- 步骤3:编制数据文件
数据接口定义

#AutoTraceDraw.py
import turtle as t
t.title('自动轨迹绘制')
t.setup(800, 600, 0, 0)
t.pencolor("red")
t.pensize(5)
#数据读取
datals = []
f = open("data.txt")
for line in f:
line = line.replace("\n","")
datals.append(list(map(eval, line.split(","))))
f.close()
#自动绘制
for i in range(len(datals)):
t.pencolor(datals[i][3],datals[i][4],datals[i][5])
t.fd(datals[i][0])
if datals[i][1]:
t.right(datals[i][2])
else:
t.left(datals[i][2])7.3 一维数据的格式化和处理
数据的操作周期:
一维数据的表示:
如果数据间有序:使用列表类型
如果数据间无序:使用集合类型
#一维数据的读入处理:从空格分隔的文件中读入数据
txt = open(fname).read()
ls = txt.split() #返回列表格式
f.close()
#一维数据的写入处理:采用空格分隔方式将数据写入文件
ls = ['中国', '美国', '日本']
f = open(fname, 'w')
f.write(' '.join(ls)) #
f.close()7.4 二维数据的格式化和处理
二维数据的表示:
使用列表类型:二维列表
CSV数据存储格式:CSV: Comma-Separated Values
数据中含有逗号时,可以使用转义符\或引号‘’
二维数据的处理:
#从CSV格式的文件中读入数据
fo = open(fname)
ls = []
for line in fo:
line = line.replace("\n","")
ls.append(line.split(","))
fo.close()
#将数据写入CSV格式的文件
ls = [[], [], []] #二维列表
f = open(fname, 'w')
for item in ls:
f.write(','.join(item) + '\n')
f.close()7.5 模块6: wordcloud库的使用
wordcloud库把词云当作一个WordCloud对象,以WordCloud对象为基础,配置对象参数、加载词云文本、输出词云文件
wordcloud.WordCloud()代表一个文本对应的词云
w = wordcloud.WordCloud():配置对象参数
w.generate(txt):向WordCloud对象w中加载文本txt,>>>w.generate( “Python and WordCloud” )
w.to_file(filename):将词云输出为图像文件,.png或.jpg格式,>>>w.to_file( “outfile.png” )
wordcloud库所做的事情:

配置对象参数w = wordcloud.WordCloud(<参数>)
width:指定词云对象生成图片的宽度,默认400像素
height:指定词云对象生成图片的高度,默认200像素
min_font_size:指定词云中字体的最小字号,默认4号
max_font_size:指定词云中字体的最大字号,根据高度自动调节
font_step:指定词云中字体字号的步进间隔,默认为1
font_path:指定字体文件的路径,默认None,如:font_path=”msyh.ttc”
max_words:指定词云显示的最大单词数量,默认200
stop_words:指定词云的排除词列表,即不显示的单词列表,如stop_words={“Python”}
mask:指定词云形状,默认为长方形,需要引用imread()函数,格式如下:
>>>from scipy.misc import imread
>>>mk=imread("pic.png")
>>>w=wordcloud.WordCloud(mask=mk)background_color:指定词云图片的背景颜色,默认为黑色,如:background_color=”white”
wordcloud应用实例:
import jieba
import wordcloud
txt = "程序设计语言是计算机能够理解和识别用户操作意图的一种交互体系,它按照特定规则组织计算机指令,使计算机能够自动进行各种运算处理。"
w = wordcloud.WordCloud( width=1000,font_path = "msyh.ttc",height=700)
w.generate(" ".join(jieba.lcut(txt))) #中文需要先分词并组成空格分隔字符串
w.to_file("pywcloud.png")7.6 实例12: 政府工作报告词云
#GovRptWordCloudv1.py
import jieba
import wordcloud
#from scipy.misc import imread
#mask = imread("fivestart.png")
f = open("新时代中国特色社会主义.txt", "r", encoding="utf-8")
t = f.read()
f.close()
ls = jieba.lcut(t)
txt = " ".join(ls)
w = wordcloud.WordCloud( font_path = "msyh.ttc",mask = mask,width = 1000, height = 700, background_color = "white")
w.generate(txt)
w.to_file("grwordcloud.png")第三部分 Python编程思维
第8周 程序设计方法学
8.1 实例13: 体育竞技分析
第9周 Python计算生态纵览
注:原课程为北京理工大学嵩天老师在中国大学慕课开设的《Python语言程序设计》课程