在matlab下使用预训练模型Alex Net进行迁移学习的实验与分析
摘要:
针对预训练模型对于个性化图片分类准确度很低,应用了迁移学习的方法,在训练集照片达到30张时,在测试集上就能达到80以上的正确率。
一:研究背景
深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(AI, Artificial Intelligence)。
深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。
深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步
二:预训练模型Alex Net
Alex Net是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。这对于传统的机器学习分类算法而言,已经相当的出色。
Alex Net中包含了几个比较新的技术点,也首次在CNN中成功应用了ReLU、Dropout和LRN等技巧。同时Alex Net也使用了GPU进行运算加速。Alex Net将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。Alex Net主要使用到的新技术点如下:
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到Alex Net的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是Alex Net将其实用化,通过实践证实了它的效果。在Alex Net中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,Alex Net全部使用最大池化,避免平均池化的模糊化效果。并且Alex Net中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(5)使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。Alex Net使用了两块GTX 580 GPU进行训练,单个GTX 580只有3GB显存,这限制了可训练的网络的最大规模。因此作者将Alex Net分布在两个GPU上,在每个GPU的显存中储存一半的神经元的参数。因为GPU之间通信方便,可以互相访问显存,而不需要通过主机内存,所以同时使用多块GPU也是非常高效的。同时,Alex Net的设计让GPU之间的通信只在网络的某些层进行,控制了通信的性能损耗。
(6)数据增强,随机地从256256的原始图像中截取224224大小的区域(以及水平翻转的镜像),相当于增加了2*(256-224)^2=2048倍的数据量。如果没有数据增强,仅靠原始的数据量,参数众多的CNN会陷入过拟合中,使用了数据增强后可以大大减轻过拟合,提升泛化能力。进行预测时,则是取图片的四个角加中间共5个位置,并进行左右翻转,一共获得10张图片,对他们进行预测并对10次结果求均值。同时,Alex Net论文中提到了会对图像的RGB数据进行PCA处理,并对主成分做一个标准差为0.1的高斯扰动,增加一些噪声,这个技巧可以让错误率再下降1%
三:现有问题及解决办法
直接应用已经由大公司用海量数据和强大计算能力训练好的深度学习网络可以很方便的直接对图片进行分类,但是也有很明显的缺点,分类的灵活性很低,只能分出模型中的类别,比如在下文实验中使用的Alex Net网络模型,他有1000个分类,可想而知,用于分类的图片若不在这1000类中,便不能很好的分类。
自己训练一个深度学习的模型具有很强的灵活性,但他对使用者的知识储备和资源都提出了很大挑战。首先使用者要对神经网络模型的构建比较熟练,知道面对不同的数据集怎样构造神经网络结构比较好等等。而且深度学习一定程度上依赖于海量数据和极其强大的计算能力,通过一次一次的迭代来不断完善模型。
试想这样一个场景,我们手中有关于十几个水果的较多量照片,他们并不在已有的训练模型中,但是我们学生的身份也确实无法获得海量的图片和极强的计算能力来从头训练一个深度学习的模型。这时使用迁移学习是比较好的方法。在已有训练模型的基础上,用我们现有的一定数量的图片作为训练集,对模型进行进一步的训练,在能满足我们较为个性化的需求同时,使用的图片数量不必很多,消耗的电脑资源也较少。
其实这个办法的理论分析也较为简单,在matlab中有很多已经训练好的并且发布为免费的深度学习模型,可以下载安装后查看其每个层。
不难发现,基本上前面的层是一些卷积层和处理层,用于分离和提取图像元素,这是我们可以借鉴的层,最后倒数第二层是一个全连接层,用于将之前的分离提取后的图片进行预测其处于每一类的可能性,最后一层起一个归一化作用,最后哪个类的可能性最高,就将图片预测为哪一类。可见我们所需要做的更改就是创建一个新的,具有我们想要的类别的全连接层,然后重新用我们的训练集对这个网络进行训练即可。
四:实验及分析
4.1 图片获取
我设想在实验中加入12类水果,来试验迁移学习的结果。这需要在互联网上获取比较大量的图片,人为手动下载显然不可能,采用了python爬虫代码来爬取照片。
代码如下(参考的网络资源):在联网状态下python3中运行即可
import re,os
import requests
from urllib.request import urlretrieve
def download(url,filename,filepath): path=os.path.join(filepath,filename)
try:
urlretrieve(url,path)
except:
print('【错误】当前图片无法下载')
def search(word="",localpath="data/", page=None):
localpath += word
os.makedirs(localpath , exist_ok=True)
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word={word}&pn={pn}&gsm={gsm:x}&ct=&ic=0&lm=-1&width=0&height=0'.format(word=word, pn=20 * page, gsm=40 + 20 * page)
print("HHHC:0====>page=%d,url=\"%s\"" % (page,url))
try:
html = requests.get(url).text
except:
print("【错误】requests.get 失败")
return False
pic_url = re.findall('"objURL":"(.*?)",', html, re.S)
i = 0;
for url in pic_url:
print(url)
i = i + 1; filename=os.path.split(url)[1].split('?')[0]
if len(filename.split(".")) != 2:
print("【错误】文件名异常:" + filename)
download(url, filename, localpath)
return
def search_20_page(word):
for i in range(1, 20):
search(word, "data/", i)
def test_search_list():
obj_list = [ "菠萝","草莓","车厘子","番石榴","桔子","龙眼","芒果","猕猴桃","苹果","葡萄","山竹","西瓜"]
for obj in obj_list:
search_20_page(obj)
if __name__ =='__main__':
test_search_list()
获得data文件夹及其文件
由于是直接从百度搜索获得图片,其中不免有一些混杂,比如苹果的搜索结果中含有了一部分苹果手机的照片,用于实验的照片与其标签应该是真实有效的,所以这些不合格照片就需要人手工来剔除一下。并且由于爬虫程序有时运行会有卡顿,我重新执行了几次,因此获得的照片数量并不一致。不过都能保证至少在80张以上。
4.2 使用matlab进行迁移学习
主体代码及其注释如下:
fruits=imageDatastore('data','IncludeSubfolders',true,'LabelSource','foldernames');
%使用Datastore数据变量储存所有在网页上获得的图片,并储存文件夹名字作为标签名,以作下一步处理。
[fruitTrain1,fruitTest1] = splitEachLabel(fruits,50,'randomized');
%在所有照片中随机选择50张组成训练集,剩余的相片作为测试集
fruitTrain=augmentedImageDatastore([227227],fruitTrain1,'ColorPreprocessing','gray2rgb');
%处理训练集图像大小至深度训练模型要求的227*227*3
fruitTest=augmentedImageDatastore([227227],fruitTest1,'ColorPreprocessing','gray2rgb');
%处理测试集图像大小至深度训练模型要求的227*227*3
anet = Alex Net;%导入alenet深度训练模型
numClasses=numel(categories(fruits.Labels));%获取新的分类个数,在此次实验中为12,但为了普遍性,使用一个函数而不是定值。
layers = anet.Layers;%提取anet的层结构,下做更改
fc=fullyConnectedLayer(numClasses); %创建一个新的全连接层,用于替换原来的模型,进行训练。
layers(23) = fc;%用创建的新全连接层替代原来的全连接层
layers(end)= classificationLayer; %用新的全连接层之后的归一化层替代原来的。
opts=trainingOptions('sgdm','InitialLearnRate',0.001);
%这是一个训练的函数,可以在此指定一些训练时的参数,在实验时指定学习率为0.001,其余使用默认值。
[fruitnet,info]=trainNetwork(fruitTrain,layers,opts);
plot(info.TrainingLoss); %打印损失率
testpreds=classify(fruitnet,fruitTest); %用迁移学习后的模型来进行预测测试集。
nnz(testpreds==fruitTest1.Labels)/numel(testpreds); %计算预测结果在测试集中的成功率。
confusionchart(fruitTest1.Labels,testpreds); %打印出各类预测与真值的‘混淆矩阵’
4.3:运行程序,分析结果
将默认值设置为0.8,即使用每个文件夹的所有图片中的80%图片用于训练,剩余的用于测试,来试验之前建立的迁移学习的效果。运行结果如下:


正确率达到87.89%。可见机器识别的正确率已经达到了较令人满意的结果。
4.4 是否进行迁移学习的比较
为探究迁移学习前后模型对于我们个性化的图片的识别能力,我先选取了12项水果的较为清晰,良好的图片用于比对。

在训练后的模型和原有的alenx模型中运行即在命令行运行如下代码:
preds=classify(fruitnet,audtest);
preds1=classify(anet,audstest);
直接查看工作空间的pred和pred1变量的值可以看到结果。(读取顺序有乱序,但不影响)
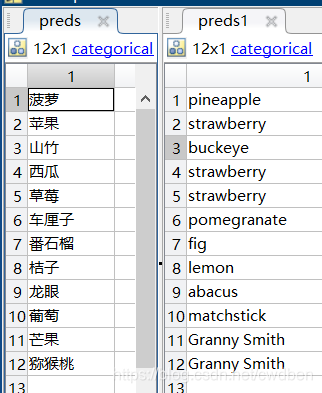
毫无疑问,迁移学习后的模型给出了完全正确的答案,而在迁移学习前的模型里,其对于草莓,菠萝的预测也是正确的,但其余照片的预测结果都是错误的。可见即使是我们一百张左右的照片,这在深度学习中远远不算大量数据,这样的训练量就能使一个预训练的模型在我们想要的领域达到很好的结果。
4.5 不同训练初值的训练结果
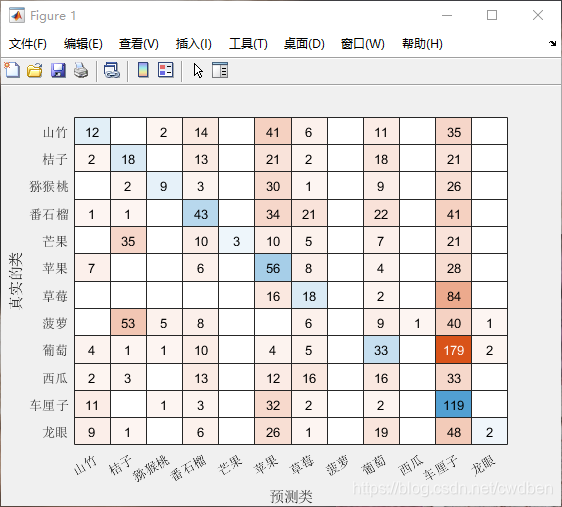
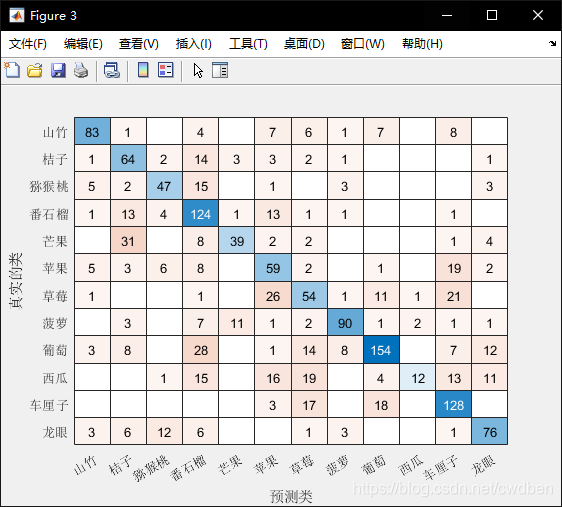
由于不同种类水果在网站上下载的图片数量不一致,在本节中改动代码的初始值,使训练时固定使用1,2,3,4,5,10,20,30,40,50,60,70张照片作为训练用,分别迁移学习一个模型,并观察其在测试集的表现即混淆矩阵和正确率。获得结果节选如下:
1张照片训练结果:
5张照片训练结果:
由于混淆矩阵难以看出各个的变化,以训练图片为横坐标,在测试集上的正确率为纵坐标,绘制图像有:
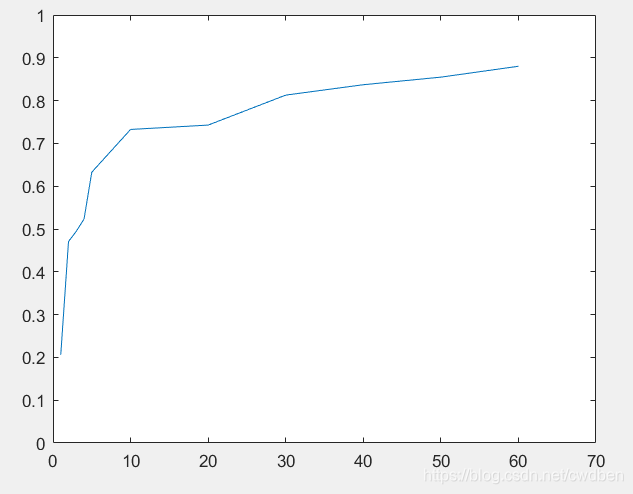
这与我们所学的知识是吻合的,在刚开始,只需要一点点训练量的提升,准确度就能提高很多。后期则需要较多的训练图片才能提高正确率。实验时也会发现,随着训练的深入,计算的时间也明显变长。可见在达到较高准确率后,同样准确度的提升所需要的训练图片增多,算力需求增多,即付出的代价显著增加。
五.结论
本文提出基于Alex Net模型的迁移学习的图像分类方法,在迁移预训练好的CNN模型到小目标集时,保留原有卷积层结构并搭建新全连接层和归一化层对数据进行分类。所设计的水果分类算法,可用于苹果、菠萝、猕猴桃、芒果、柑橘、草莓、龙眼、山竹、西瓜、西番莲、樱桃、桔子十二类。
训练集和测试集均等采用从百度中下载的图片,其变化较多,无论是光照,拍摄角度还是构图,在这样大的变化中,照片识别成功率能达到87左右是很不错的,具有较强的普适性。
六.参考文献
[1] “深度学习”词条,百度百科。[Z]
[2] 廉小亲,成开元,安飒,吴叶兰,关文洋.基于深度学习和迁移学习的水果图像分类[J].测控技术,2019,38(06):15-18.
[3] “Alex Net”词条,百度百科。[Z]
[4] python3-按关键字爬取百度图片https://blog.csdn.net/menghaocheng/article/details/79608328 [Z]
