一、jvm是干什么的?
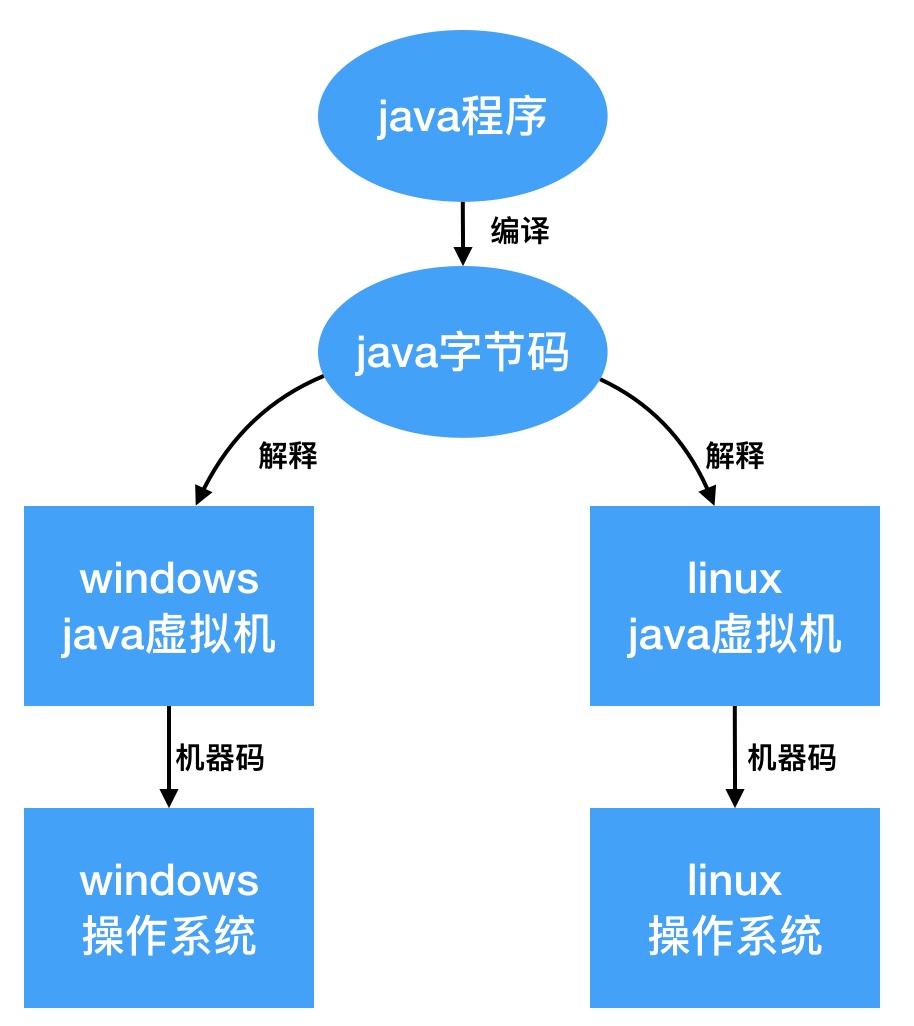
大家都知道java是跨平台语言,一次编译可以在不同操作系统上运行,怎么做到的呢,看下图:
javac把写的源代码(java文件),编译成字节码(class文件),字节码部署到linux/windows/..上,被对应的jvm解释成机器码运行,jvm的工作就是这个。
大家都知道,java不需要开发者写代码来申请、释放和管理内存,jvm在运行时帮助我们做了这个事情,即便如此,我们还是需要了解jvm的内存结构,以便排查各种和内存有关的问题,比如oom,性能调优。
二、jvm内存结构是怎样的?
Java的兄弟,有没有曾经碰到过这些问题,出现OOM是什么原因?性能慢打dump发现是在等待内存分配,怎么查?了解jvm内存结构,当出现内存相关问题时,便于分析解决问题。
下图比较清晰的展示了jvm内存结构:
1、jvm内存结构分3大块:堆内存Heap、方法区Method Area和栈Stack堆;
2、堆内存Heap:分为年轻代Young Generation和老年代Old Generation;
3、年轻代YG:又分为3部分,Eden Space、From Survivor Space、To Survivor Space.

再来看看主要的几个参数:
▪ -Xms设置堆的最小空间大小;
▪ -Xmx设置堆的最大空间大小;
▪ -XX:NewSize设置新生代最小空间大小;
▪ -XX:MaxNewSize设置新生代最大空间大小;
▪ -XX:PermSize设置永久代最小空间大小;
▪ -XX:MaxPermSize设置永久代最大空间大小;
▪ -Xss设置每个线程的堆栈大小。
三、各内存空间分别存放一些什么东西,我们写的代码对应了哪些内存空间?
1、堆内存Heap,存的是对象,所有的对象在实例化后的整个运行周期内,都被存放在堆内存中
2、方法区Method Area,存的是已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据
3、栈Stack,存的是基本数据类型和堆中对象的引用

堆内存,又分年轻代和老年代,那么,什么情况下用年轻代,什么情况下会进入老年代呢?
1、运行时,新创建的对象分配在年轻代的Eden,随着时间推移,Eden会满,这时候就会触发MinorGC.
2、有几种情况,会触发对象进入老年代:
1)JVM会给对象增加一个年龄(age)的计数器,对象每“熬过”一次GC,年龄就+1,当年龄达到设置的阈值(默认为15)就会被移到老年代。(可通过-XX:MaxTenuringThreshold调整阈值, 一次Minor GC后,对象年龄就会+1,达到阈值的对象就移动到老年代,其他存活下来的对象会继续保留在新生代中)
2)不用等待15次GC之后进入老年代,大致是,如果一批对象的总大小大于这块Survivor(From/To)内存的50%,那么大于这批对象年龄的对象就进入老年代
3)如果设置了参数-XX:PretenureSizeThreshold,那么如果创建的对象大于这个参数值,就直接把这个对象放入老年代,不经过新生代。这么做就可以避免大对象在新生代,屡次躲过GC,还得把他们来回复制,最后才进入老年代,浪费时间。
四、上面大致了解了内存结构,写的代码JVM是怎么分配内存的,那么什么样的对象用到的内存该回收了,怎么回收呢?
先来看第一个问题,什么样的对象用的内存该回收了?肯定是没用的对象就回收了,要用的对象你千万别给回收了是吧。怎么判断对象没用了,变成垃圾了,下面介绍它的几个算法:
1、引用计数法
在 Java 中,引用和对象是有关联的。如果要操作对象则必须用引用进行。因此,很显然一个简单的办法是通过引用计数来判断一个对象是否可以回收。简单说,即一个对象如果没有任何与之关联的引用,即他们的引用计数都不为0,则说明对象不太可能再被用到,那么这个对象就是可回收对象。 据说此算法存在循环引用问题,欢迎读者朋友们,帮忙留言补充什么是循环引用问题,最好能举例子哦,多谢多谢!
2、可达性分析
为了解决引用计数法的循环引用问题,Java 使用了可达性分析的方法。通过一系列的“GC roots”对象作为起点搜索。如果在“GC roots”和一个对象之间没有可达路径,则称该对象是不可达的。要注意的是,不可达对象不等价于可回收对象,不可达对象变为可回收对象至少要经过两次标记过程。两次标记后仍然是可回收对象,则将面临回收。
上面辨别出来了垃圾,接下来就是要看这些垃圾该怎么回收了:
1、标记清除算法(Mark-Sweep)
最基础的垃圾回收算法,分为两个阶段,标注和清除。标记阶段标记出所有需要回收的对象,清除阶段回收被标记的对象所占用的空间。很明显,这个算法很直接,但会造成碎片是不,来个大对象,可能找不到一块连续的内存空间给她用。
2、复制算法(copying)
为了解决 Mark-Sweep 算法内存碎片化的缺陷而被提出的算法。按内存容量将内存划分为大小一样的两块。每次只使用其中一块,当这一块内存满后将尚存活的对象复制到另一块上去,把已使用 的内存清掉。很直接吧,把上面说有碎片的问题就解决了,但是也有个缺点,内存是不是有点浪费,只能用一半。
3、标记整理算法(Mark-Compact)