*特征工程是一个复杂活,本人认为它一般包括以下几个过程:特征初筛、特征衍生(加工)、特征选择;
特征筛选是一个精细活,需要考虑很多因素,比如:预测能力、相关性、稳定性、合规性、业务可解释性等等。
从广义上,特征筛选可从业务指标和技术指标两大类出发:
1.业务指标包括:
1). 合规性:用以加工变量的数据源是否符合国家法律法规?是否涉及用户隐私数据?例如,如果某块爬虫数据被监管,那么相关变量的区分度再好,我们也只能弃用。
2). 可得性:数据未来是否能继续采集?这就涉及产品流程设计、用户授权协议、合规需求、模型应用环节等诸多方面。例如,如果产品业务流程改动而导致某个埋点下线,那么相关埋点行为变量只能弃用。又比如,如果需要做额度授信模型,那么只能利用在额度阶段能采集到的实时数据,这就需要提前确认数据采集逻辑。
3). 稳定性:一方面,数据源采集稳定是变量稳定性的基本前提。例如,外部数据常会因为政策性、技术性等原因导致接入不稳定,这就需要做好数据缓存,或者模型降级机制。另一方面,变量取值分布变化是导致不稳定的直接原因。我们将会采取一些技术指标展开分析,下文将会介绍。
4). 可解释性:需要符合业务可解释性。如果变量的业务逻辑不清晰,那么我们宁可弃之。同时,这也是保证模型可解释性(参数 + 变量)的前提。
5). 逻辑性:也就是因果逻辑,特征变量是因,风控决策是果。如果某个变量是风控系统决策给出的,那么我们就不能入模。例如,用户历史申贷订单的利率是基于上一次风控系统决策的结果,如果将“用户历史申贷订单的利率”作为变量,那么在实际使用时就会有问题。
6). 可实时上线:模型最终目的是为了上线使用。如果实时变量不支持加工,那么对应的离线变量就只能弃之。例如,某个离线变量在统计时限定观察期为180天,但线上只支持观察期为90天,那么就不可用。对于不熟悉线上变量加工逻辑的新手,往往容易踩坑而导致返工。
2.技术指标包括:缺失率、变异系数、稳定性、信息量、特征重要性、变量聚类、线性相关性、多重共线性、逐步回归、P-Vaule显著性检验,以及特征选择系列算法等;
2.1 基于缺失率(Missing Rate)
1)功能:统计变量缺失率,并计算缺失率的均值、标准差。
2)指标:缺失率 = 未覆盖样本数 / 总样本数 × 100%
3)业务理解:变量缺失率越高,可利用价值越低。缺失率变化不稳定的变量,尤其是缺失率趋势在升高,代表未来数据源采集率下降,不建议采用。数据源是特征变量的基础,数据源不稳定,直接导致模型稳定性变差。
2. 基于变异系数(Coefficient of Variation,CV)
1)功能:基于数据分布EDD,选择某个指标(如均值mean)计算变异系数CV,用来衡量变量分布的稳定性,再设置阈值进行筛选。
2)指标:变异系数 CV =( 标准偏差 SD / 平均值Mean )× 100%
3)业务理解:变异系数越小,代表波动越小,稳定性越好。缺点在于CV没有统一的经验标准。
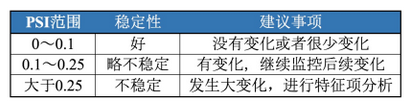
3. 基于稳定性(Population Stability Index,PSI)
1)功能:以训练集(INS)分布为期望分布,计算变量的群体稳定性指标PSI,再根据PSI的经验阈值进行筛选。
2)指标:psi计算公式;
3)业务理解:需分申请层、放款层,分别评估变量稳定性。通常会选择0.1作为阈值,只要任意一个不满足稳定性要求就弃用。PSI无法反映很多细节原因,比如分布是右偏还是左偏。此时需要从EDD上进行分析。
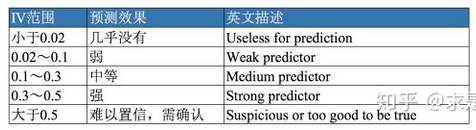
4. 基于信息量(Information Value,IV)
1)功能:统计变量的IV,再根据IV的经验阈值来筛选。
2)指标:IV。可参考《WOE与IV指标的深入理解应用》
3)业务理解:用以评估变量的预测能力。通常情况下,IV越高,预测能力越强。但IV过高时,我们就要怀疑是否发生信息泄漏(leakage)问题,也就是在自变量X中引入了Y的信息。
5. 基于特征重要性
1)功能:根据树模型训练后给出的特征重要性,一般选择累积重要性Top 95%的变量。若要为降低一次训练所导致的随机性影响,可综合多次结果来筛选。
2)指标:特征重要性。
XGBoost实现中Booster类get_score方法输出特征重要性,其中importance_type参数支持三种特征重要性的计算方法:weight、gain、cover;
3)业务理解:在特征变量特别多的时候,可用于快速筛选特征。从机器学习可解释性角度而言,特征重要性只具有全局可解释性,无法对单个case给出解释。
6. 变量聚类(Variable Cluster,VarClus)
功能:列聚类,将所有变量进行层次聚类,再根据聚类结果,剔除IV相对较低的变量。
7. 基于线性相关性(Linear Correlation)
1)功能:计算变量的线性相关性,相关性较高的多个变量里,保留IV较高的变量。
2)指标:皮尔逊相关系数(Pearson Correlation Coefficient),系数的取值为[-1, 1],两变量相关系数越接近0,说明线性相关性越弱;越接近1或-1,说明线性相关性越强。
3)业务理解:逻辑回归作为一种线性模型,其基础假设是:自变量 (x1, x2) 之间应相互独立。当两变量间的相关系数大于阈值时(一般阈值设为0.6),剔除IV值较低的变量。
8. 基于多重共线性(Multicollinearity)
1)功能:计算变量的方差膨胀因子(Variance Inflation Factor,VIF),适用于线性模型,再根据阈值剔除VIF较高的变量。
2)指标:通常用VIF衡量一个变量和其他变量的多重共线性。
3)业务理解:VIF取值的业务含义为:
若VIF < 3,说明基本不存在多重共线性问题
若VIF > 10,说明问题比较严重。
9. 基于逐步回归(stepwise)
- 前向选择(forward selection):逐步加入变量,计算指标进行评估,若不合格则不加入,直到评估完所有变量。
- 后向选择(backward selection):初始时加入所有变量,根据指标逐渐剔除不合格的变量。
- 逐步选择(stepwise):将向前选择和向后选择的结合,逐步放入最优的变量、移除最差的变量。
10. 基于P-Vaule显著性检验
1)功能:用于检验自变量X与因变量Y之间的相关性,可剔除P值大于0.05的变量。
2)指标:P-Vaule。
3)业务理解:根据逻辑回归参数估计表,剔除P值大于0.05的变量。
11.特征选择系列算法
- 过滤式:互信息(MI)、最大信息系数(MIC)、信噪比(IR)等
- 封装式:BPSO-SVM等,这个不常用;
- 嵌入式:lasso、K-split lasso、iter_lasso等;
- 集成式:多个特征选择方法结果集成,可解决不稳定的问题;
- 其它:也可多种方法混合成一种新的特征选择方法,如:过滤式+嵌入式的模式等;