mysql数据库的优化和创建索引
1、了解为什么要优化数据库
数据库优化的目的
-
避免出现页面访问错误
- 由于数据库连接timeout产生页面5xx错误
- 由于慢查询造成页面无法加载
- 由于阻塞造成数据无法提交
-
增加数据库的稳定性
- 很多数据库问题都是由于低效的查询引起的
-
优化用户体验
- 流畅页面的访问速度
- 良好的网站功能体验
2、了解数据库优化的几种方式
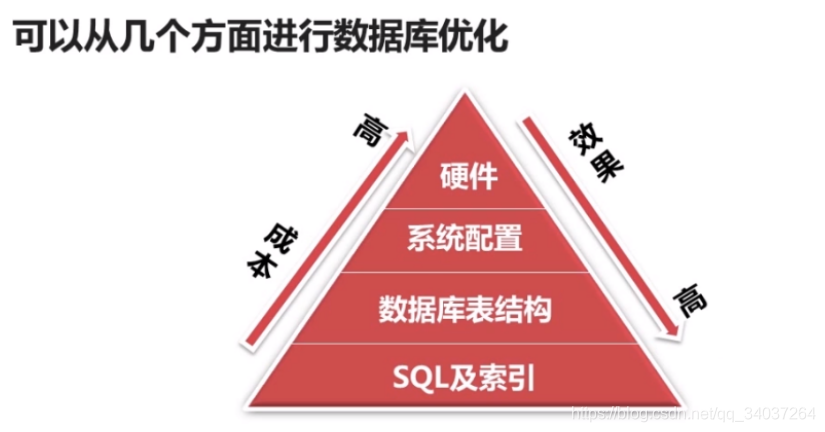
3、熟练掌握使用索引和优化数据表结构来优化数据库查询
1、如何查看sql的查询效率
-
在日常工作中,我们会有时会开慢查询做记录一些执行时间比较久的sql语句,找出这些sql语句并不意味着完事了,此时我们常常用到explain这个命令来查看一个这些sql语句的执行计划,查看该sql语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看. 所以我们深入了解MySql的基于开销的优化器,还可以获得很多可能被优化器考虑到的访问策略的细节,以及当运行sql语句时哪种策略预计会被优化器采用
-
–实际SQL,查找用户名为msfh的用户
-
select * from user where name = 'msfh'
-
-
–查看SQL是否使用索引,前面加上explain即可
-
explain select * from user where name = 'msfh'
-
2、explain解读

explain出来的信息有10列,分别是id,select_type,tabl,type,possible_keys,key,key_len,ref,rows,Extra
概要描述:
id:选择标识符
select_type:表示查询的类型
table:输出结果集的表
partitions:匹配的表
type:表示表的连接类型
possible_keys:表示查询时,可能使用的索引
key:
表示实际使用的索引
key_len:索引字段的长度
ref:索引字段的长度
ref:列与索引的比较
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤的行百分比
Extra:执行情况的描述和说明
对表访问方式,表示MySQL在表中找到所需行的方式,又称"访问类型"
常用的类型有:ALL、index、range、ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
ALL:FUll Table Scan,MySQL将便利全表以找到匹配的行
index: Full Index Scan , index与ALL区别为index类型只便利索引树
range: 只检索给定范围的行 , 使用一个索引引来选择行
ref: 表示上述表的连接匹配条件 , 即哪些列或常量被用于查找索引列上的值
3、索引创建原则
1、ORDER BY +LIMIT组合的索引优化 , 如果一个SQL语句如:
SELECT [column1],[column2],…. FROM [TABLE] ORDER BY [sort] LIMIT [offset],[LIMIT];
这个SQL语句优化比较简单,在[sort]这个栏位上建立索引即可
2、WHERE + ORDER BY + LIMIT组合的索引优化
如果一个SQL语句如:
SELECT [column1],[column2],…. FROM [TABLE] WHERE [columnX] = [VALUE] ORDER BY [sort] LIMIT [offset],[LIMIT];
这个语句,如果你仍然采用第一个例子中建立索引的方法,虽然可以用到索引,但是效率不高.
更高效的方法是建立一个联合索引(columnX,sort)
3、怎么加快查询速度,优化查询效率,主要原则就是应尽量避免全表扫描,英爱考虑在where及order by 设计的列上建立索引.
建立索引不是建的越多越好,原则是:
- 一个表的索引不是越多越好,也没有一个具体的数字,根据以往的经验,一个表的索引最多不能超过6个,欣慰索引越多,对update和insert操作也会有性能的影响,设计到索引的新建和重建操作.
- 建立索引的方法论位:
- 多数查询经常使用的列;
- 很少进行修改操作的列;
- 索引需要建立在数据差异大的列上
4、四种索引的使用场景
PRIMARY , INDEX , UNIQUE 这三种是一类
PRIMARY主键 . 就是 唯一 且 不能为空
INDEX 索引, 普通的
UNIQUE 唯一索引. 不予许有重复.
FULLTEXT是全文索引 , 用于在一篇文章中 , 检索文本信息的 .
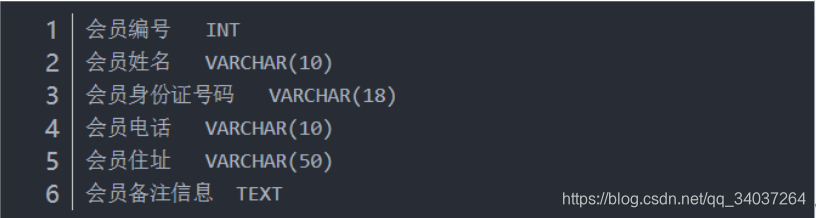
举个例子来说 , 比如你在为某商场做一个会员卡的系统
这个系统有一个会员表
有下列字段
5、SQL查询注意部分
1. 任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
2. 应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
3. 应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
4. 应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
应改为:
select id from t where num=10 union all select id from t where num=20
6、表结构方面优化
1. 选择最合适的字段属性,使用可以存在数据的最小的数据类型,例如邮政编码,手机号码这类定长的数字可 以用char(6),char(11);性别或者是否这种判断性文字可以用tinyint;字段属性尽量为not null这样不用判断是否 为空,减少一个步骤(用其他方式表达你想表达的NULL,比如 -1);如果一定要用text这种类型,最好是采用 分表存储;
2.将常用信息和不常用信息分表存储,比如一个商城网站的用户表,用户的昵称,头像,密码,账号这类字段用 户登录就会用到,而用户的兴趣爱好了,喜欢的颜色了这种字段就分表存储,相信大家京东账号中的个人信息 可能也就在注册的时候打开过,以后就再没注意过了吧。
