环境信息
- 系统:CentOS Linux release 7.6.1810
- solr:solr-7.7.2
- java:openjdk 1.8.0_222
- IKAnalyzer:ik-analyzer-solr7-7.x
集成IK分词器
solr安装参见博文----Apache solr入门
- 下载分词器jar包,github地址
- 将ik-analyzer-solr7-7.x.jar包上传到 $SOLR_INSTALL_HOME/server/solr-webapp/webapp/WEB-INF/lib目录下
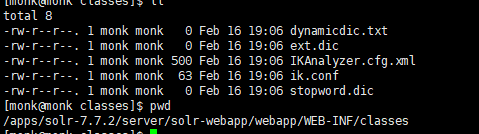
- 在$SOLR_INSTALL_HOME/server/solr-webapp/webapp/WEB-INF目录下新建目录classes目录,并将IK分词器中源码的资源文件上传到该目录下,如图所示:
- 编辑$SOLR_INSTALL_HOME/server/solr/test_core/conf/managed-schema,引入IK分词器,在文件底部加入以下内容(PS:在schema标签内):
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
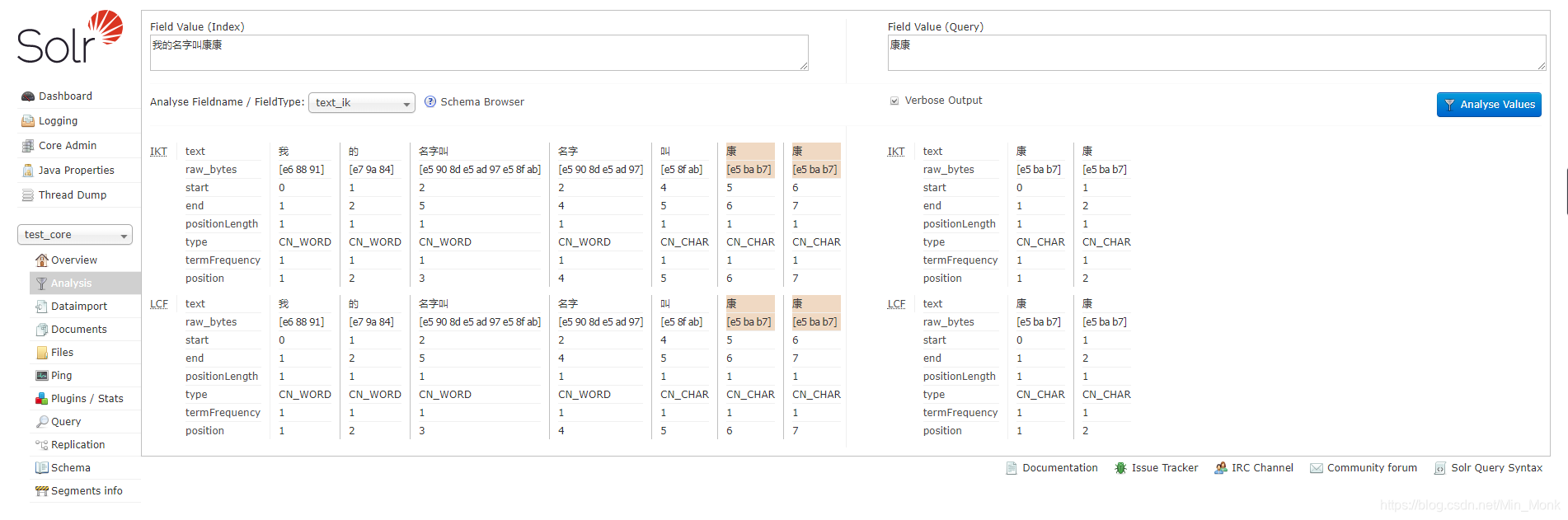
- 重启solr,在界面测试,如图所示:
集成solr自带中文分词器
- 分词器的jar包到solr-webapp目录下
cp $SOLR_INSTALL_HOME/contrib/analysis-extras/lucene-libs/lucene-analyzers-smartcn-7.7.2.jar $SOLR_INSTALL_HOME//server/solr-webapp/webapp/WEB-INF/lib/
- 编辑$SOLR_INSTALL_HOME/server/solr/my_core/conf/managed-schema文件,引入IK分词器,在文件底部加入以下内容(PS:在schema标签内):
<!-- solr自带分词器 -->
<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="0">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
- 重启solr,在界面测试,如图所示:
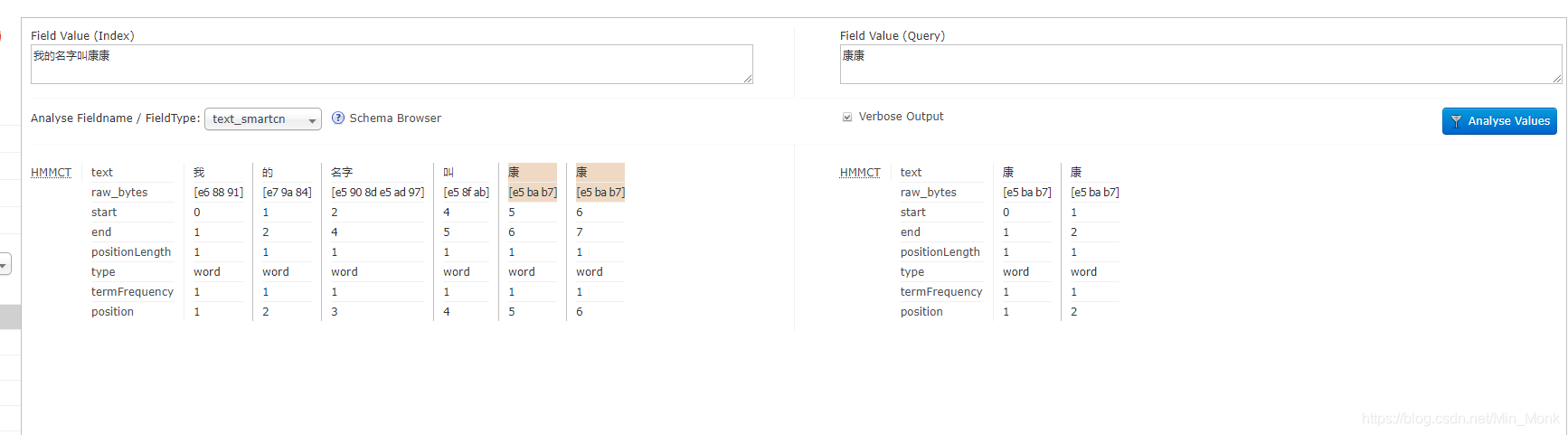
这么一比较起来,个人觉得IK分词器的效果更细腻一些,在关键字搜索的时候,命中率会更高一些。
