§1.1 统计学习(statistical learning)
又称统计机器学习,目的是:对数据进行分析或预测。统计学习关于数据的基本假设是同类数据具有一定的统计规律性,可以用概率统计的方法处理。
§1.2 统计学习分类
♧1.2.1 基本分类
统计学习或强化学习一般包括监督学习、无监督学习和强化学习。有时还包括半监督学习和主动学习。
♡1 监督学习
本质是学习输入到输出的映射的统计规律。 每个具体的输入实例是一个特征,所有特征组成特征空间,输入空间不同于特征空间时,应将输入空间映射到特征空间。
输入变量和输出变量为连续变量的预测问题为回归问题;输入变量和输出变量为离散变量的预测问题为分类问题;输入变量和输出变量为序列的预测问题为标注问题。
基本假设:输入和输出的随机变量具有联合概率分布。
假设空间(hypothesis space):由输入空间到输出空间的映射集合。假设空间确定代表着学习范围确定。监督学习的模型分为概率模型和非概率模型。模型描述出输入与输出随机变量之间的映射关系。
♡2 无监督学习
从无标注的数据中学习预测模型。本质是学习数据中的统计规律或潜在结构。 输出由输入的类别、转换、概率表示。模型对数据进行:聚类、降维、或概率统计。
♡3 强化学习
指智能体在与环境的连续互动中学习最优行为策略的机器学习,基于马尔科夫决策过程,智能系统观测的是与环境互动得到的数据序列。
需要强调的是Q-function和value function的区别:Q-function是基于当前状态和动作的而value function是基于当前状态的。
还有就是强化学习的方法:model-based和model-free(包括:优化policy和优化value两种方法)。
详细内容
♡4 半监督学习
♡5 主动学习
指机器不断主动给出实例让教师进行标注,然后利用标注数据学习预测模型的机器学习问题。
与监督学习的区别在于:主动学习的目标是找出对学习有帮助的数据让教师标注,不像监督学习,标注的数据是随机的。
♧1.2.2 按模型分类
♡1 概率模型和非概率模型

♡2 线性模型和非线性模型

♡3 参数化模型和非参数化模型

♧1.2.3 按算法分类
♡ 在线学习(on-line)和批量学习(batch)

利用随机梯度下降的感知机器学习方法就是在线学习。
♧1.2.4 学习技巧分类
♡1 贝叶斯学习(Bayesaian learning)


♡2 核方法
 技巧在于:不显示地定义这个映射,而是直接定义核函数。
技巧在于:不显示地定义这个映射,而是直接定义核函数。
§1.3 统计学方法三要素
模型+方法+算法。按照什么样的准则学习或选择模型(策略),求解最优模型(算法)。
♧模型

♧策略
-
损失函数:度量模型一次预测的好坏。
-
风险函数:度量平均意义下模型预测的好坏。
风险函数 = 损失函数的期望

-
经验风险:对于训练数据集的平均损失。经验风险最小化:

-
结构风险最小化:

♧算法
要求:全局最优;高效。
§1.4 模型评估与模型选择
♧训练误差与测试误差
测试误差:与经验风险的数学表达式相同只不过,测试误差将经验风险的训练集换成了测试集中的数据。
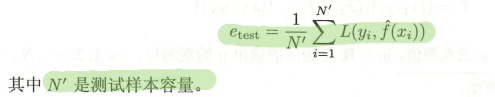
♧过拟合

§1.5 正则化与交叉验证
♧正则化
正则化是结构风险策略最小化的实现,所以正则化的一般形式和结构风险相同:
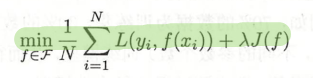
♧交叉验证
§1.6 泛化能力
♧泛化误差
所学到的模型的期望风险。
♧泛化误差的上界


§1.6 判别模型与生成模型

