作为高性能的NIO通信框架,性能优势是Netty的核心竞争力之一,自Netty4.x引入内存池机制后,Netty默认采用内存池模式创建ByteBuf对象,性能得到很大提升,GC压力也得到很大缓解。
内存池原理分析
主要数据结构
Netty内存池内存的几种类型
具体分配
主要数据结构
1.PooledArena: 代表内存中一大块连续的区域,PoolArena由多个Chunk组成,每个Chunk由多个Page组成。内存池包含一组PooledArena,用于提升并发性能。
2.PoolChunk: 用来组织和管理多个Page的内存分配和释放,默认16M。
3.PoolSubpage: 一个小于Page的内存,Netty在Page中完成分配。每个Page会被切分成大小相等的多个存储块,存储块的大小由第一次申请的内存块大小决定。假如一个Page为8字节,如果第一次申请块大小是4字节,那么这个Page就包含两个存储块。一个Page只能用于分配与第一次申请时大小相同的内存,比如,1个4字节的Page,如果第一次分配了1字节的内存,如果有一个申请2字节的内存的请求,就需要在新的Page中进行分配。
一个Arena由两个PoolSubpage数组和多个ChunkList组成。两个PoolSubpage数组分别为tinySubpagePools和smallSubpagePools,多个ChunkList是双向链表排列的,每个ChunkList中包含多个Chunk,每个Chunk包含多个Page(默认2048个),每个Page(默认大小为8K字节)由多个Subpage组成。
每个Arena的ChunkList构成:
- PoolChunkList qInit:存储内存利用率0-25%的chunk
- PoolChunkList q000:存储内存利用率1-50%的chunk
- PoolChunkList q025:存储内存利用率25-75%的chunk
- PoolChunkList q050:存储内存利用率50-100%的chunk
- PoolChunkList q075:存储内存利用率75-100%的chunk
- PoolChunkList q100:存储内存利用率100%的chunk
每个ChunkList里的Chunk数量会动态变化,如Chunk内存利用率发生变化时会向其他ChunkList移动。
Netty内存池内存的几种类型
Netty内存池内存的分类:
- tiny:小于512B
- small:大于等于512B,小于8KB
- normal:大于等于8KB,小于等于16M
- huge:大于16M(非池化内存)
内存分配策略:通过PooledByteBufAllocator申请内存时,首先从PoolThreadLocalCache中获取与线程绑定的缓存池PoolThreadCache,如果不存在线程私有缓存池,则轮询分配一个Arena数组中的PooledArena,创建一个新的PoolThreadCache作为缓存池使用。
PooledArena进行内存分配对预分配内存做容量判断,相关场景:
- 需要分配的内存小于PageSize(默认8K),分配tiny(tinySubpagePools)或small(smallSubpagePools)内存。
- 需要分配的内存介于PageSize和ChunkSize之间,分配normal(PoolChunkList中的Chun中分配)内存。
- 需要分配的内存大于ChunkSize时,分配huge内存(非池化内存)。
具体分配
为了能够简单的操作内存,必须保证每次分配内存是连续的。Netty底层的内存分配和回收管理主要有PoolChunk实现,其内部维护一颗二叉树。PoolChunk用memoryMap和depthMap来表示二叉树。

PoolChunk默认为16M,包含2048个Page,每个Page为8KB。
1、如果需要分配的内存为8K内存,则只需在11层,找到第一个可用节点即可。
2、如果需要分配的内存为16K内存,则只需在10层,找到第一个可用节点即可。
3、如果节点1024已经存在一个被分配的子节点2048,如需要分配大小为16K的内存,不能直接分配1024,因为2048节点已被分配,1024节点只剩8K。
memoryMap初始化:
memoryMap = new byte[maxSubpageAllocs << 1];
depthMap = new byte[memoryMap.length];
int memoryMapIndex = 1;
for (int d = 0; d <= maxOrder; ++ d) {
int depth = 1 << d;
for (int p = 0; p < depth; ++ p) {
memoryMap[memoryMapIndex] = (byte) d;
depthMap[memoryMapIndex] = (byte) d;
memoryMapIndex ++;
}
}
memoryMap数组中每个位置保存的是该节点所在的层数,对于节点512,其层数是9,则:
1、如果memoryMap[512] = 9(memoryMap[id]=depthMap[id]),则表示其本身到下面所有的子节点都可以被分配;
2、如果memoryMap[512] = 10(memoryMap[id]>depthMap[id]), 则表示节点512下有子节点已经分配过,则该节点不能直接被分配,而其子节点中的第10层还存在未分配的节点;
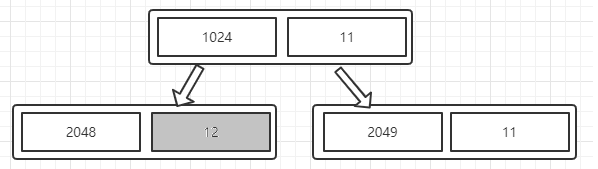
3、如果memoryMap[512] = 12 (即总层数 + 1)(memoryMap[id]=最大深度(默认11)+1), 可分配的深度已经大于总层数, 则表示该节点下的所有子节点都已经被分配。
假如申请4KB的内存,内部更新情况:
第一步:分配内存,同时标记节点被占用
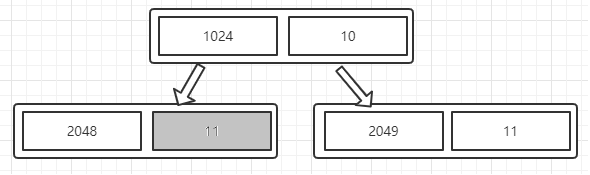
第二步:当前被分配占用的节点修改
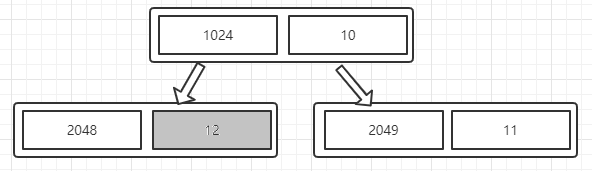
第三步:更新父节点为两子节点较小的值