不管是面试,还是工作中,我们都要带着理论去实践,这样做出来的项目才更健壮
先说说索引的类型:
普通索引 index
唯一索引 unique
主键索引 primary key
全文索引(myisam独有) fulltext
索引的常见模式:
哈希表
有序列表
二叉树
Btree(innoDB的B+tree)
索引优化记录:
首先我们要知道,索引的创建是需要物理空间的,一般都在mysql的data目录下,每一个数据库都有相应的文件,比如我下面的文件:

分别是表数据,表索引等数据文件
MYI是索引文件,当你创建表索引的时候,就会将算法实实在在的写入到这个文件中,可以理解为写了一个目录在里面
组合索引优化
利用组合索引进行查询有一个技巧
多列索引的情况下,必需要使用到最左边的列字段,否则是不会使用到索引的
还有一种情况是如果查询条件中有索引字段,还是依然可以使用到索引的,这时候不分左右顺序
模糊查询
当使用一个索引字段进行模糊查询时,需要注意,如果在字段前使用%号,则这个字段是用不到索引的,在后面加%是可以的。
如果一定要在字段前面检索内容,则只能考虑使用全文索引了
or用法索引相关
or用法在使用索引字段的时候,只要需要了or关键字查询的字段都要建立索引才能使用到,否则不会使用到索引
所以,在开发过程中,尽量避免使用or关键字
tips:
关于如果要查询的条件字段中,列是字符串的话,一定要用单引号,否则不会使用索引 ,这是Mysql规定的
#中间说一个关于查询索引 使用率的方法
show status like 'handler_read%';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| Handler_read_first | 0 |
| Handler_read_key | 4 |
| Handler_read_last | 0 |
| Handler_read_next | 0 |
| Handler_read_prev | 0 |
| Handler_read_rnd | 0 |
| Handler_read_rnd_deleted | 0 |
| Handler_read_rnd_next | 16000044 |
+--------------------------+----------+handler_read_key 越大越好 handler_read_rnd_next 越小越好
group by分组查询优化
在使用分组查询的时候,Mysql默认自动排序,如果你在查询时没有特定的排序要求,就不需要这样的开销了
可以使用下面的语句来消除默认排序
select * from 表名 group by 字段名 order by null;explain 之后会发现extra这一项没有了using filesort 文件排序这一列
多表查询
当有两个表需要联表查询时,你可能第一想法是如下
select t1.name from 表1 as t1 , 表2 as t2 where t1.id = t2.id;最好是不要像上面那样写,应该用join如下
select t1.name from 表1 as t1 inner join 表2 as t2 on t1.id = t2.id;
select t1.name from 表1 as t1 join 表2 as t2 on t1.id = t2.id;
select t1.name from 表1 as t1 left join 表2 as t2 on t1.id = t2.id;都是可以的,就看你前面查询的字段是在左表还是右表了
关于存储引擎
什么时候该用什么引擎,首先得知道有什么引擎是不是
常见的两种引擎:
myisam
innodb
一、当这个表被设计为不需要事务处理,查询与插入数据为主的,选择myisam
二、当涉及到财务类的,钱,财产的都需要用到事务的,就必需使用innodb
区别:
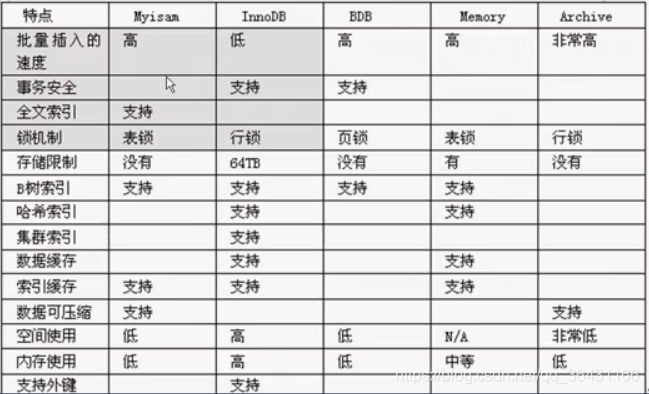
如果面试,不需要全部说出来,说几下几点就行了:
1、事务,innodb支持
2、添加速度myisam更快
3、全文索引myisam支持
4、锁机制,myisam表锁,innodb行锁
5、外键,innodb支持
有这五点,就够了。
