visual bag of words 词袋用于SLAM重定位
DBOW
bags of binary words for fast place recognition in image sequence (https://ieeexplore.ieee.org/document/6202705) 这篇文章参考了前文,是ORBSLAM2中重定位模块的基础。首先按照文章的结构介绍这一篇文章。
Binary features
- 文章中使用FAST特征点和BRIEF描述子。
- FAST和BRIEF特征点计算速度快。
- 使用二进制的BRIEF描述子计算二进制距离可以使用位运算符(xor),计算hamming距离。
Image database
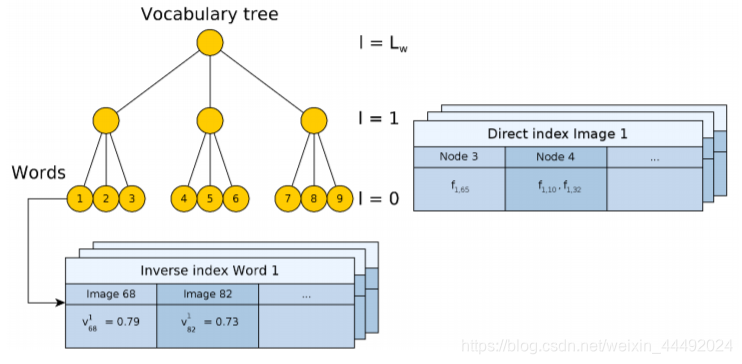
- 预先离线收集图像,建立vocabulary。主要包括Inverse index 和Direct index。Inverse index是针对每一个词袋的单词,并且记录每个单词在每个关键帧的权重。Direct index是对每个层的记录,记录了在一张图片在当前层有哪些节点包含了图片中的特征word。
- 使用k means和k medians clustering。使用tf-idf作为权重。
- Inverse index是为了以后计算中更快的访问每个单词的权重。
- Direct index是为了更加方便的存储每张图片的每个节点的特征信息。
- 对于一张新图片,对每个特征点在词袋中寻找hamming距离最近的word。最终encoding成一个t维的向量(t为单词的数量)。
Loop detection
A. Data base query
- 简单的来说就是寻找队列中距离最近的一个关键帧。
- 文章中使用一个归一化的score。具体定义可以参见原文章。
B. Matching grouping
- 如果当前的图片和候选人X很“接近”,那么当前图片和X邻近的的一些关键帧也会同样接近。这不是我们想要的。
- 所以文章提出讲候选图片先grouping据类成一个个island。每个island中只会有一个最终的结果。
C. Temporal consistency
- 如果当前图片和某一个候选人很接近,那么上一帧应该和这个候选人很接近才对。
- 所以下一步的检验是候选人帧和上一帧的匹配检测。
- 最终得到最终候选人。
D. Efficient geometrical consistency
- 在获取最终的候选人之后要进行几何验证。
- 首先是使用之前的Direct index找到可能相似的特征匹配候选。
- 使用RANSAC fundament matrix匹配。
结果分析
- BRIEF特征点找到的匹配大多数是中距离和远距离的。因为BRIEF没有scale信息。
- SURF特征点点对近距离的特征效果更好。
ORBSLAM2 中的Relocalization
根据词袋计算得到候选
- 这一个流程基本和前面的ABC思想一致。
- 在所有关键帧中找与当前帧有公用单词的帧。
- 提取中存在足够过共有单词的关键帧。
- 计算相似分数,并且根据co-visibility累积分数。
- 返回所有高分的候选。
下一步计算位姿
- 类似上面的C步骤,使用Direct Index寻找特征点匹配。
- 使用PnP RANSAC,寻找更加准确的匹配点,并且设置位姿初始值。
- Pose optimization (bundle adjustment)优化位姿,得到最终结果。
使用方法
下面以FBOW为例子,介绍BOW的整个使用步骤。
1. 创建图像数据集并且提取对应的特征点数据
提取方式有很多,这里就不赘述了。
2. 创建Vocabulary
根据上面提取的特征点数据,将描述子的格式转变为一个vector。然后选择适当的创建参数,最后开始创建。整个过程需要一段时间完成。但是这是一个一次性的工作,一旦建立完成,就不需要再重复了。
这一步的图片数据库选择(图片的分布,数据量大小等),会影响之后的匹配结果,所以一定要仔细思考慎重选择。
// vSIFTdescritpors is a set of sift feature points
std::vector<cv::Mat> vSIFTdescritpors;
// the vocabulary creation options
fbow::VocabularyCreator::Params params;
params.k = 10;
params.L = 6;
params.nthreads = 4;
params.maxIters = 11;
params.verbose = true;
// create the creator
fbow::VocabularyCreator voc_creator;
std::cout << "Creating a " << params.k << "^" << params.L << " vocabulary..." << std::endl;
// record time
auto t_start=std::chrono::high_resolution_clock::now();
// create the sift feature vocabulary
try{
voc_creator.create(voc,vSIFTdescritpors,"sift", params);
}catch(std::exception &ex){
std::cerr << ex.what() << std::endl;
}
// end of creation
auto t_end = std::chrono::high_resolution_clock::now();
std::cout << "time = " << double(std::chrono::duration_cast<std::chrono::milliseconds>(t_end-t_start).count()) << " msecs ";
std::cout << " nblocks = " << voc.size() << std::endl;
std::cerr << "Saving " << save_path << std::endl;
// save the created vocabulary to file for further use
voc.saveToFile(save_path);
3. 新图像匹配
同样,先提取新图片的特征点,转换为FBOW需要的格式,再调用 " voc.transform(desCV);" 将描述子转换为FBOW的单词出现的二进制向量。最后使用“vv.score(vv, keyframesBOW[i]);”将这个向量分别与词袋中的其他图片比较,得到新图片与旧图片的分数比较。最后可以排序这些分数,得到我们想要的结果。
void Ulocalization::MatchImage(FeatureDescriptors &descriptors)
{
std::cout << " [FBOW] Register new image. " << std::endl;
// transform the descriptor type
cv::Mat desCV;
eigen2cv(descriptors, desCV);
fbow::fBow vv;
int avgScore = 0;
int counter = 0;
std::chrono::steady_clock::time_point t1 = std::chrono::steady_clock::now();
vv = voc.transform(desCV);
std::map<double, int> score;
// rank the scores
int numTop = 5;
int bestIdx = 0;
double bestScore = 0;
for (size_t i = 0; i<keyframesBOW.size(); ++i){
// calculate the score
double score1 = vv.score(vv, keyframesBOW[i]);
// TODO: rank the socre
// or we can just take the highest score as result
if (score1 > bestScore){
bestScore = score1;
bestIdx = i;
}
}
std::chrono::steady_clock::time_point t2 = std::chrono::steady_clock::now();
double ttrack= std::chrono::duration_cast<std::chrono::duration<double> >(t2 - t1).count();
std::cout << " using time : " << ttrack << " seconds. " << std::endl;
}
4. 增加新图片进数据库
也可以增加新图片进之前建立的数据库Vocabulary,代码见下面。
void Ulocalization::AddImagesToVoc()
{
std::cout << " [FBOW] Add the dataset images to the directionary. " << std::endl;
std::chrono::steady_clock::time_point t1 = std::chrono::steady_clock::now();
keyframesBOW.clear();
for (const auto idx : framesIds ){
cv::Mat desCV; // = new cv::Mat();
FeatureDescriptors descriptors = database->ReadDescriptors(idx);
eigen2cv(descriptors, desCV);
fbow::fBow vv = voc.transform(desCV);
keyframesBOW.push_back(vv);
}
std::chrono::steady_clock::time_point t2 = std::chrono::steady_clock::now();
double ttrack= std::chrono::duration_cast<std::chrono::duration<double> >(t2 - t1).count();
std::cout << " [FBOW] done, using time : " << ttrack << " seconds. " << std::endl << std::endl;
}
VINS 的重定位模块
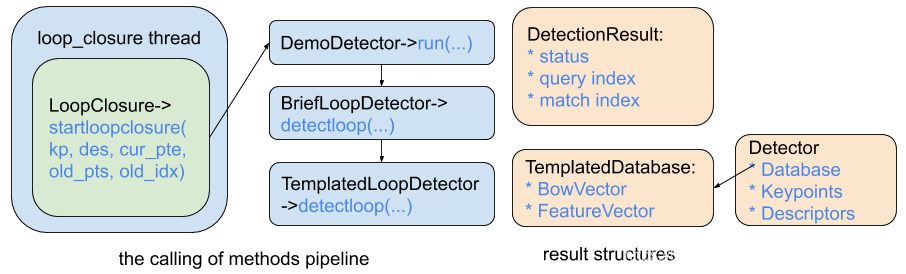
VINS的重定位线程的调用如上图的左半边所示。主要是启动一个loop_closure的thread线程。在这个线程中,会从bufffer中调取keyframe关键帧,输入到LoopClosure方法中去寻找回环。最终调用的函数是在TemplatedLoopClosure中的 detectloop函数。
- 将描述符转换为bowvector和featurevector(这是dbow的类型)。
BowVector bowvec;
FeatureVector featvec;
if(m_params.geom_check == GEOM_DI)
m_database->getVocabulary()->transform(descriptors, bowvec, featvec,
m_params.di_levels);
else
m_database->getVocabulary()->transform(descriptors, bowvec);
- 如果查询id足够大。将转换后的两个向量查询到单词包数据库中查找匹配项。
* 无论如何,将这两个向量添加到单词包数据库中。
QueryResults qret;
m_database->query(bowvec, qret, m_params.max_db_results, max_id);
// update database
m_database->add(bowvec, featvec); // returns entry_id
- 删除得分较低的候选人,然后将匹配指数初始化为得分最高的候选人,如果存在的话。
* 并将查询结果转换为一个“island”向量(即按id的升序将所有candidate分块)
* 找到得分最高的island。
// compute islands
vector<tIsland> islands;
computeIslands(qret, islands);
const tIsland& island =
*std::max_element(islands.begin(), islands.end());
- 通过isgeometricallyconsistent_DI检查几何一致性。
* 使用得分最高的岛(我们在上面找到)来检查
if(m_params.geom_check == GEOM_DI) {
// all the DI stuff is implicit in the database
detection = isGeometricallyConsistent_DI(island.best_entry,
keys, descriptors, featvec, cur_pts, old_pts);
} else {
detection = true;
//printf("don't check detec true\n");
}
- 保存关键点、描述子(用于几何检查)和这个bowvector(用于nss规范化)。
// update record
// m_image_keys and m_image_descriptors have the same length
if(m_image_keys.size() == entry_id) {
//printf("image size = entry_id %d\n", entry_id);
m_image_keys.push_back(keys);
m_image_descriptors.push_back(descriptors);
} else {
//printf("image size != entry_id %d\n", entry_id);
m_image_keys[entry_id] = keys;
m_image_descriptors[entry_id] = descriptors;
}
// store this bowvec if we are going to use it in next iteratons
if(m_params.use_nss && (int)entry_id + 1 > m_params.dislocal) {
m_last_bowvec = bowvec;
}
使用FBOW匹配特征点
1. 首先整理关键帧图像数据库
keyframesBOW.clear();
keyframesBOW.reserve(keyframeSize);
for (int i = 0; i < keyframeSize; i ++){
fbow::fBow vv = vocFBOW.transform(vKeyFrames[i].descriptors);
keyframesBOW.push_back(vv);
}
2. 提取新输入图片的向量
fbow::fBow vv;
vv = vocFBOW.transform(newImage.descriptors);
3. 从数据库中匹配得到匹配值最高的图片
BOWResult *bowresults = new BOWResult[keyframeSize];
for (size_t i = 0; i<keyframesBOW.size(); ++i){
double score = vv.score(vv, keyframesBOW[i]);
bowresults[i].index = i;
bowresults[i].score = score;
}
// rank the scores
// TODO: we can delete the low scores, then loop, which will be faster than sort
std::sort(bowresults, bowresults + keyframeSize);
其中BOWResult定义如下:
struct BOWResult
{
int index;
double score;
};
// compare the score of the result
// define the operator for using std::sort
bool operator<(const BOWResult &a, const BOWResult &b) {
return a.score > b.score;
}
4. 选取candidate进行特征点匹配
这里尝试使用词袋的数模型来加速匹配,但是感觉没有得到理想的效果。如果有大神路过,发现我的逻辑问题,请一定留步指导一下!谢谢!
我的想法主要是对每个特征点的词袋向量循环,找到在同一个枝叶下的特征点,然后再比较他们的描述子。如果描述子的距离足够近,那就认为他们是匹配的。代码和具体的解释如下:
std::vector<FBOWMatch> OfflineMap::FindMatchBow(GKeyFrame &newImagekf, const fbow::fBow &newimage, const int oldIndex)
{
fbow::fBow &oldimage = keyframesBOW[oldIndex];
// 准备循环的开始结尾flag
fbow::fBow::const_iterator newimage_it = newimage.begin();
fbow::fBow::const_iterator oldimage_it = oldimage.begin();
const fbow::fBow::const_iterator newimage_end = newimage.end();
const fbow::fBow::const_iterator oldimage_end = oldimage.end();
// 用来记录当前的id位置,以便找到对应的描述子
int index_new = 0;
int index_old = 0;
//double score = 0;
int count = 0;
std::vector<FBOWMatch> fbowMatches;
while(newimage_it != newimage_end && oldimage_it != oldimage_end){
//这里可以得到他们的词袋向量,可以用来计算他们的匹配度(相乘即可)
//const auto& vi = newimage_it->second;
//const auto& wi = oldimage_it->second;
if(newimage_it->first == oldimage_it->first){
// 这里是一些debug输出
/*
std::cout << " [MATCH] find features in the same node. " << index_new << "th feature in new image in "
<< newimage_it->first << "th node, and " << index_old << "th feature in old image in "
<< oldimage_it->first << "th node." << std::endl;
*/
// in the same node -> matched, vi * wi is their match score
// 这里计算score,可以反应出在词袋中两个点的近似程度,fbow
// 的源码就是使用这种方法来计算分数的
//score = vi * wi;
//std::cout << " score is : " << score << std::endl;
// 找到对应的两个描述子并且比较他们的距离。
// 这里计算距离的函数是另外定义的距离。
const cv::Mat &desNew = vKeyFrames[oldIndex].descriptors.row(index_old);
const cv::Mat &desOld = newImagekf.descriptors.row(index_new);
const int dist = DescriptorDistance(desNew,desOld);
//std::cout << " descriptor distance is : " << dist << std::endl;
// 如果距离足够小,则认为是良好的匹配点
if(dist < TH_HIGH){
FBOWMatch fbowMatch(index_new, index_old, dist);
fbowMatches.push_back(fbowMatch);
count++;
}
// 如果两个向量不在用一个节点,则继续寻找下一对的匹配
// move v1 and v2 forward
++newimage_it; ++index_new;
++oldimage_it; ++index_old;
}else if(newimage_it->first < oldimage_it->first){
// move v1 forward
while(newimage_it != newimage_end && newimage_it->first < oldimage_it->first){
++newimage_it; ++index_new;
}
}else{
// move v2 forward
while(oldimage_it!=oldimage_end && oldimage_it->first<newimage_it->first){
++oldimage_it; ++index_old;
}
}
}
// 最后输出结果
std::cout << " [MATCH] found " << count << " matches." << std::endl;
return fbowMatches;
}
ORBSLAM2 implementation DOW2
Finally I checked the implementation of DBOW2 in ORBSLAM, the code is as following:
int SearchByBoW(GKeyFrame* pKF,GKeyFrame &F, vector<GMapPoint*> &vpMapPointMatches)
{
int HISTO_LENGTH = 30;
int TH_LOW = 50;
bool mbCheckOrientation = true;
float mfNNratio = 0.9;
// the mappoint associated with the keyframe's keypoints, and the BOW vector
const vector<GMapPoint*> vpMapPointsKF = pKF->GetMapPointMatches();
const DBoW2::FeatureVector &vFeatVecKF = pKF->mFeatVec;
// initialize the match results
vpMapPointMatches = vector<GMapPoint*>(F.keypoints.size(),static_cast<GMapPoint*>(NULL));
int nmatches=0;
vector<int> rotHist[HISTO_LENGTH];
for(int i=0;i<HISTO_LENGTH;i++)
rotHist[i].reserve(500);
const float factor = 1.0f/HISTO_LENGTH;
// We perform the matching over ORB that belong to the same vocabulary node (at a certain level)
DBoW2::FeatureVector::const_iterator KFit = vFeatVecKF.begin();
DBoW2::FeatureVector::const_iterator Fit = F.mFeatVec.begin();
DBoW2::FeatureVector::const_iterator KFend = vFeatVecKF.end();
DBoW2::FeatureVector::const_iterator Fend = F.mFeatVec.end();
// loop through the feature vectors of the two keyframes
while(KFit != KFend && Fit != Fend){
if(KFit->first == Fit->first){
const vector<unsigned int> vIndicesKF = KFit->second;
const vector<unsigned int> vIndicesF = Fit->second;
// for each vector pair, loop through all their elements
for(size_t iKF=0; iKF<vIndicesKF.size(); iKF++) {
// find the corresponding mappoint and its descriptor
const unsigned int realIdxKF = vIndicesKF[iKF];
GMapPoint* pMP = vpMapPointsKF[realIdxKF];
if(!pMP)
continue;
const cv::Mat &dKF= pKF->descriptors.row(realIdxKF);
int bestDist1 = 256;
int bestIdxF = -1 ;
int bestDist2 = 256;
for(size_t iF=0; iF<vIndicesF.size(); iF++){
const unsigned int realIdxF = vIndicesF[iF];
// if already matched
if(vpMapPointMatches[realIdxF])
continue;
const cv::Mat &dF = F.descriptors.row(realIdxF);
const int dist = DescriptorDistance(dKF,dF);
if(dist < bestDist1){
bestDist2 = bestDist1;
bestDist1 = dist;
bestIdxF = realIdxF;
} else if(dist < bestDist2) {
bestDist2 = dist;
}
}
// check the best match (with the lowest score)
// need to be standout through all the keypoints -> bestdist < w*secondbestdist
if(bestDist1<=TH_LOW){
if(static_cast<float>(bestDist1) < mfNNratio*static_cast<float>(bestDist2)){
vpMapPointMatches[bestIdxF]=pMP;
const cv::KeyPoint &kp = pKF->keypoints[realIdxKF];
if(mbCheckOrientation){
float rot = kp.angle-F.keypoints[bestIdxF].angle;
if(rot < 0.0)
rot += 360.0f;
int bin = round(rot*factor);
if(bin == HISTO_LENGTH)
bin = 0;
assert(bin >= 0 && bin < HISTO_LENGTH);
rotHist[bin].push_back(bestIdxF);
}
nmatches++;
}
}
}
KFit++;
Fit++;
} else if(KFit->first < Fit->first) {
KFit = vFeatVecKF.lower_bound(Fit->first);
} else {
Fit = F.mFeatVec.lower_bound(KFit->first);
}
}
if(mbCheckOrientation){
int ind1=-1;
int ind2=-1;
int ind3=-1;
ComputeThreeMaxima(rotHist,HISTO_LENGTH,ind1,ind2,ind3);
for(int i=0; i<HISTO_LENGTH; i++){
if(i==ind1 || i==ind2 || i==ind3)
continue;
for(size_t j=0, jend=rotHist[i].size(); j<jend; j++){
vpMapPointMatches[rotHist[i][j]]=static_cast<GMapPoint*>(NULL);
nmatches--;
}
}
}
return nmatches;
}
We can easily find the differences between its implentation and mine, I only used the vector score result, however the ORBSLAM2 used its inverse index to offer more possibility to find match.
So I went to check the fbow source code. I found I class called fbow2 within it, which could offer the inverse index (used in the upper function), however when I try to find its usage, I failed. As a result, fbow does not fully support to find corresponding using bow vector(or maybe I have missed some part, if it is the case, please let me kown, thanks).
