CSV随机参数化
一. 在Jmeter上引入随机CSV数据集配置插件
1、在jmeter中打开 Jmetr插件管理器
2、选择可用插件
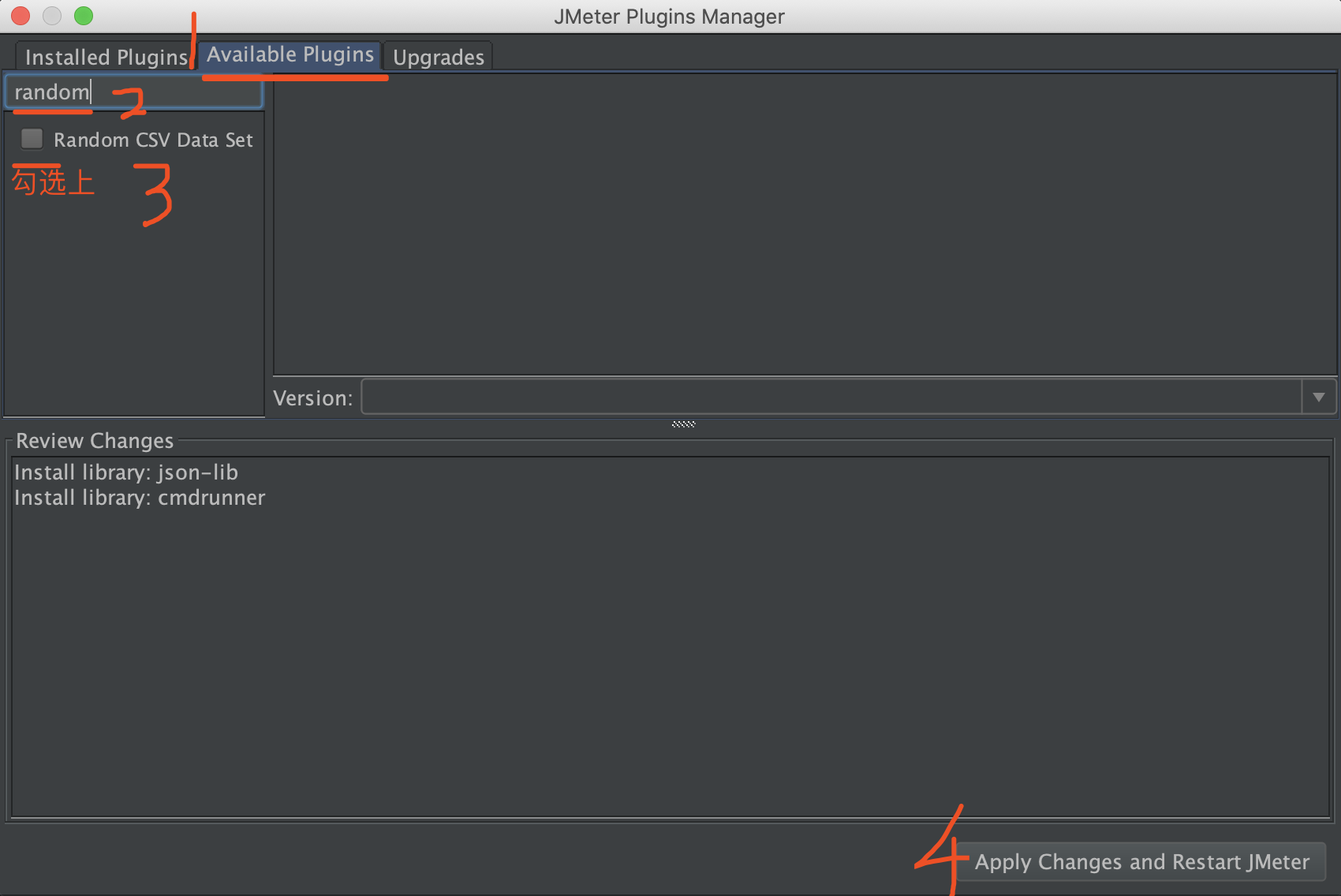
3、搜索Random
4、找到Random CSV Data Set Config 并下载重新启动jmeter
Random CSV Data Set
Config item that allows reading CSV files in random order
Documentation: https://github.com/Blazemeter/jmeter-bzm-plugins/blob/master/random-csv-data-set/RandomCSVDataSetConfig.md
What's new in version 0.6: fix leak with open files
Maven groupId: com .blazemeter, artifactId: jmeter-plugins- random-csv- data- set, version: 0.6L ibraries : [jmeter-plugins-cmn-jmeter]
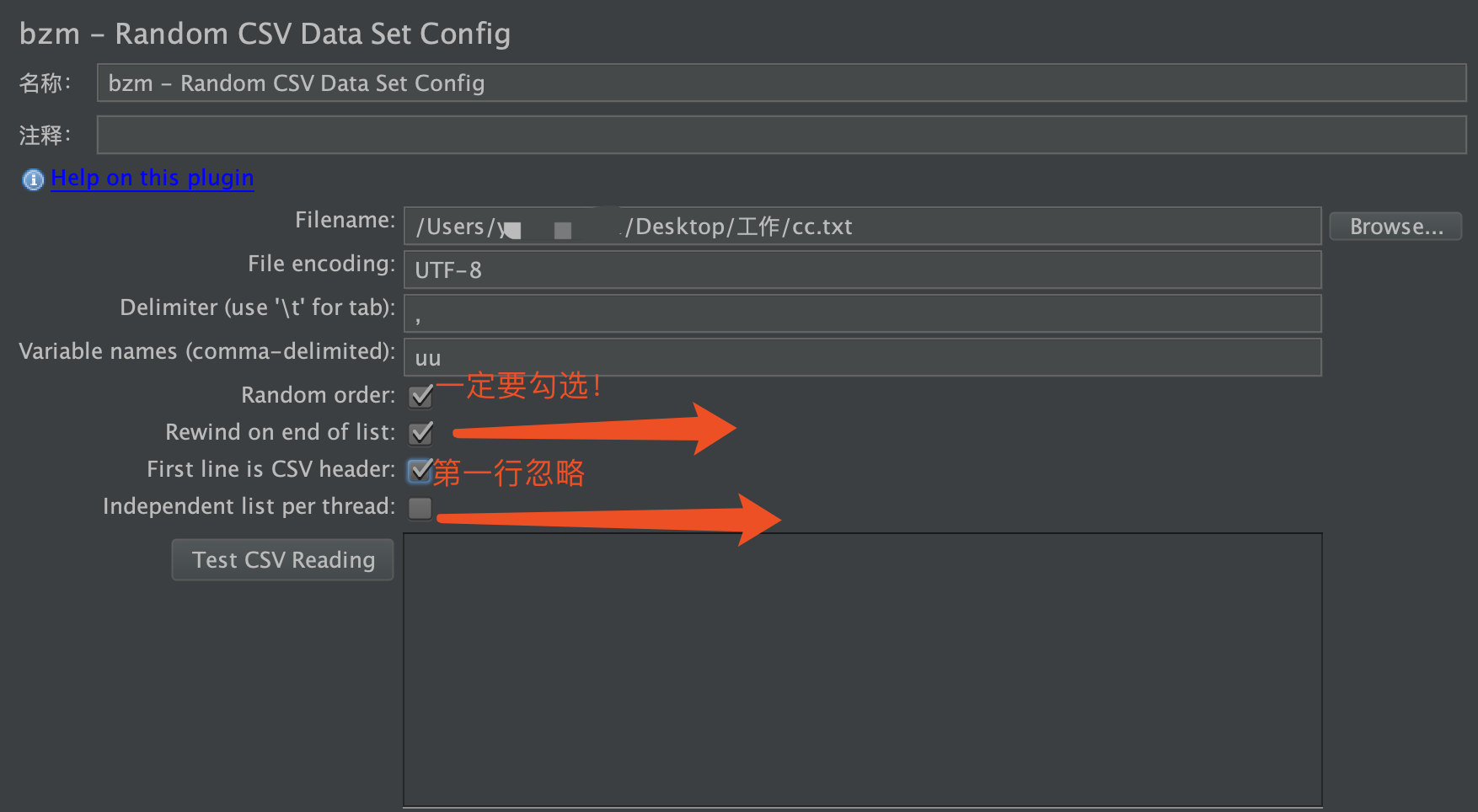
参数说明: .
1文件名: csv文件的路径,最好选择绝对路径;对于分布式测试,必须将CSV文件存储在服务器主机系统上与JMeter服务器启动所在的正确相对目录中
2.文件编码: 此CSV文件的编码,用于读取此文件的编码
3.分隔符:默认逗号
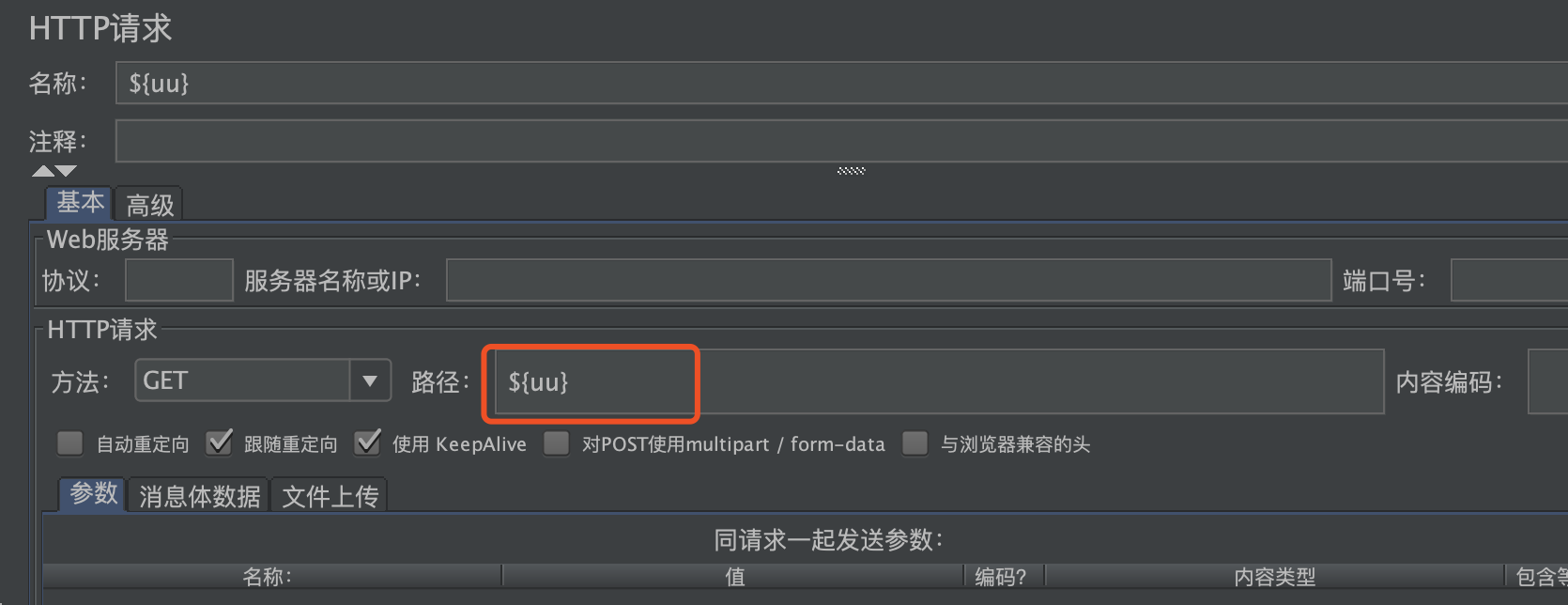
4.变量名称: 引用csv配置文件中的数据时,要指定变量名;指定一个变量以便后续引用,uu 引用就是${uu}
5.随机顺序: 注意!一定要勾选!!选中则会随机顺序从文件中读取数据,如果不选择,则和常规的CSV数据集配置-样工作。
6. Rewind on end of list 遇到文件结束符再次循环:
在一个测试循环完成后, Jmeter再运行一个,这对于检查一段时间内的性能非常有用,
当选择随机顺序时(第5项) ,第二次和后续的每一次重新循环都会以不同顺序读取CSV数据集中的数据。
如果选择了该标志并且迭代循环已经结束,则将开始新的循环。
7.First line is CSV head 第一行是CsV标题: 如果指定了“变量名称” , 并且想要跳过文件中的第一行,请选中此复选框;如果第一行是定义了变量名称,那么此项勾选!
选择此标志以跳过标题(仅在Variable Names不为空时使用)
8.Independent list per thread 每个线程的独立列表: 每个线程都将通过他们自己去读取配置文件,当使用随机顺字(第5项),每个线程都运行自己的随机序列,而不是所有线程都经过相同的变量顺序。
----官方理解:使用"随机顺序"进行检查时,每个线程均以随机顺序运行自己的CSV值副本。如果未选中,则所有线程将遍历相同的随机值列表。
9.测试/test读取CV文件: 在真正使用之前,可以先测试下读取数据的规则,以供后续正确使用。
在测试开始时,配置读取文件。大文件存在延迟和大量内存消耗。
在预览区域中,仅显示CSV文件中的20条记录。