本文将会讨论策略优化的数学基础,并且会附上简单的实践代码。三个要点
- 一个简单的等式,将策略梯度跟策略模型参数连接起来
- 一条规则,允许我们将无用的项从等式里去掉
- 另一条规则,允许我们在等式中添加有用的项
推导最简单的策略梯度
在这里,我们考虑随机参数化策略的情况 。我们的目标是使预期收益 最大化。出于此推导的目的,我们将 设为有限无折扣收益(无限折现收益设置的推导几乎相同)。
我们想要通过梯度上升来优化策略,例如:
其中 称为策略梯度,利用策略梯度来优化策略模型这种方法叫做策略梯度算法,例如VPG、TRPO。PPO通常也被称为策略梯度算法,但是这有点不太准确)
要实际使用此算法,我们需要一个可以通过数值计算的策略梯度表达式。这涉及两个步骤:
- 得出策略模型的可解析的梯度,其形式跟期望值相差不大,
- 对期望值进行样本估计,使其可以使用代理与环境交互产生的数据进行计算
在本小节中,我们将找到该表达式的最简单形式。在后面的小节中,我们将展示如何以最简单的形式进行改进,以获取我们在标准策略梯度实现中实际使用的版本。
1.序列的概率。由 产生动作, 的概率为:
2.对数-导数技巧。该技巧基于一个简单运算规则: 相对于 的导数是是 。重新排列并与链式规则结合后,我们得到:
3.序列的对数概率。其对数概率就是
4. 环境函数梯度。 环境跟 无关, 所以 , , 和 等于0。
5.序列的对数梯度。
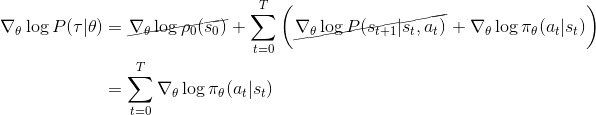
基本策略梯度推导

这是一个期望,这意味着我们可以使用样本均值对其进行估计。如果我们收集一组序列 ,其中,每个序列都是代理代理使用策略 在环境中进行交互来获得,则可以使用以下方法估算策略梯度:
其中 表示在 ( , N).
最后一个表达式是可计算的最简单版本。假设我们已经以某种的方式表示了我们的策略模型,并且该模型允许计算 ,并且如果我们能够在环境中运行该策略以收集序列,那么我们就可以计算策略梯度并对模型进行更新。
下面结合tensorflow2.1给出最简单的策略梯度更新代码实现:
1、建立模型
import matplotlib.pyplot as plt
import gym
import numpy as np
from tensorflow import keras
from tensorflow.keras import models, layers, optimizers
env = gym.make('CartPole-v0')
STATE_DIM, ACTION_DIM = 4, 2
model = models.Sequential([
layers.Dense(100, input_dim=STATE_DIM, activation='relu'),
layers.Dropout(0.1),
layers.Dense(ACTION_DIM, activation="softmax")
])
model.compile(loss='mean_squared_error',
optimizer=optimizers.Adam(0.001))
def choose_action(s):
"""选取动作"""
prob = model.predict(np.array([s]))[0]
return np.random.choice(len(prob), p=prob)
这里我们建立了一个分类策略的神经网络,测试环境使用gym里面的CartPole-v0。需要注意的是,在分类策略中,网络输出的是每个动作的logit,然后利用softmax函数将其转换为概率。也就是说,动作 的logits, 的概率为:
2、损失函数
这里要结合全部代码来看,不过就直觉上而言,损失函数的作用就是要使得奖励最大化,在代码中,对于k维动作,损失函数定义为:
假设某一个动作得分很高,loss值就会变小(注意有个负号),如果得分很低,loss值就会相应地变大。
| 注意 |
|---|
即使我们将其描述为损失函数,但从监督学习的角度来看,它并不是典型的损失函数。与标准损失函数有两个主要区别。
1.数据分布取决于参数。损失函数通常在固定的数据分布上定义,该分布与我们要优化的参数无关。这里不是,必须在最新策略上对数据进行采样。
2.它不衡量性能。损失函数通常会评估我们关注的性能指标。在这里,我们关心预期收益, 但是,即使在预期中,我们的“损失”函数也根本不近似。此“损失”功能仅对我们有用,因为当在当前参数下进行评估时,使用当前参数生成的数据时,其性能会呈现负梯度。
但是,在梯度下降的第一步之后,就不再与性能相关。这意味着,对于给定的一批数据,最小化此“损失”功能无法保证提高预期收益。损失值可以达到 ,而决策变现可能会很差;实际上,这种情况时常发生。有时,资深RL研究人员可能会将此结果描述为对大量数据“过度拟合”的策略。这是描述性的,但不应从字面上理解,因为它没有涉及泛化错误。
之所以提出这一点,是因为ML练习者通常会在训练过程中将损失函数解释为有用的信号-“如果损失减少了,一切都会好起来的。”在策略梯度中,这种直觉是错误的,您应该只关心平均回报率。损失函数没有任何意义。
下面是主函数以及折扣收益
def discount_rewards(rewards, gamma=0.95):
"""计算衰减reward的累加期望,并中心化和标准化处理"""
prior = 0
out = np.zeros_like(rewards)
for i in reversed(range(len(rewards))):
prior = prior * gamma + rewards[i]
out[i] = prior
return out / np.std(out - np.mean(out))
def train(records):
s_batch = np.array([record[0] for record in records])
# action 独热编码处理,方便求动作概率,即 prob_batch
a_batch = np.array([[1 if record[1] == i else 0 for i in range(ACTION_DIM)]
for record in records])
# 假设predict的概率是 [0.3, 0.7],选择的动作是 [0, 1]
# 则动作[0, 1]的概率等于 [0, 0.7] = [0.3, 0.7] * [0, 1]
prob_batch = model.predict(s_batch) * a_batch
r_batch = discount_rewards([record[2] for record in records])
model.fit(s_batch, prob_batch, sample_weight=r_batch, verbose=0)
episodes = 2000 # 至多2000次
score_list = [] # 记录所有分数
for i in range(episodes):
s = env.reset()
score = 0
replay_records = []
while True:
a = choose_action(s)
next_s, r, done, _ = env.step(a)
replay_records.append((s, a, r))
score += r
s = next_s
if done:
train(replay_records)
score_list.append(score)
print('episode:', i, 'score:', score, 'max:', max(score_list))
break
env.close()
