基于家庭安全移动式监护系统的设计与实现(大创)
1 课题研究背景、意义以及项目创新
1.1 课题研究背景
近些年,由于人口老龄化的持续加剧,集辅助和防护功能于一体的智能安防机器人已经成为研究热点。智能安全机器人可以连接各种智能家庭环境中的智能及非智能电子设备,方便老人与病人使用。它使老年人能够达到独立生活并提供相应的安全保证,即使在没有其他人参与或只有少量人参与的情况下。而这就要求智能机器人能在各种设备之间转移,可实现自主移动和智能避障,并且只占用很小的空间等。其中智能避障系统不仅扮演着重要角色,而且更是整个系统运行的基础和前提。
跨入21世纪后,随着电子技术的不断提升,无论是高性能的处理芯片,还是高分辨率的摄像头,在我们的身边随处可见,我们已经习惯了与这些电子产品相处,通过现代技术进一步解放我们的生活。正所谓,科技改变生活。正是这些技术的发展使我们进入了一个新的时代,同时技术的产生和发展都会更好地服务我们的生活,利用高新技术去解决人类社会发展中遇到的种种问题,才是我们这些科技工作者一直努力的方向。
近些年机器人技术一直是许多科技工作者的研究方向,使得机器人更加的智能化和数字化是研究者们一直以来努力的目标。通过一代又一代科技人员的不断研究与创新,智能机器人发展愈发成熟,我们可以看到现在的工厂更愿意选择工业机器人来代替人工劳动力,不仅降低了劳动成本,同时还可以提升生产效率。尤其是在汽车制造领域或者一些大型流水线上机器人的使用已经是很常见的事情。而为我们的生活也提供了多样化的机器人服务,从各种陪孩子学习的智能机器人,再到各种扫地、洗衣、做饭的智能机器人,它们成为了生活中不可分割的一部分。
1.2 课题研究意义
智能机器人之所以可以越来越强大,一方面得益于数字芯片的高速处理能力,另一方面得益于种类繁多的传感器。传感器如同机器人的感官器官,负责获取未知环境信息。而数字芯片就好比机器人的大脑,负责处理各种外界信息。对于智能机器人而言,获取外界信息是一切工作的前提,而这些信息可以来源于视觉、听觉、触觉、味觉等。作为获取外部环境信息的重要手段,视觉有着天然的优势。
但是尽管近些年通过对障碍物检测、识别等算法的不断研究和优化,基于视觉技术设计的避障系统也取得了一定的成绩。然而,想要机器人在周围环境未知的情况下,执行复杂的设定任务,如何实现对动态与静态物体的实时避障是智能避障机器人技术的关键。对于人类来说,视觉系统为人类获取信息提供了重要方式。在智能机器人实际应用中的导航和避障过程中,为了实现实时性,我们不需要像人类视觉一样来区分不同的外界事物,简单的避障只需区分可行的区域和障碍物,获取障碍物的深度信息,因此智能避障系统的设计主要是针对各种道路场景的理解,为机器人提供能够快速识别和检测障碍物以及计算可行区域的能力。
研究智能避障系统有助于推进机器人技术不断发展,促进技术改革升级;与此同时,智能避障系统在工业和军事领域的产业的实际应用也愈加频繁。智能避障系统的不断成熟必然会促进社会生产、生活效率的大大提高。因此,非常有必要对智能避障系统进行深入研究。
目前,仍有一些视觉避障技术难题急需解决,如数据量大,实时性差,易受光线影响等问题;该论文基于室内复杂环境特点,提出通过对室内环境的LAB色彩空间特征进行数据分析,并根据小孔成像原理建立智能小车与空间障碍物之间的几何模型,能够有效减少图像分析的数据量并降低系统的光线敏感度,其能够很大水平上提高了避障系统的实时性能。同时通过视觉技术获取被监控目标人物的实时信息,并利用图像处理算法将目标人物从背景中分离出来,实现对目标人物的跟踪,并通过对目标人物的行为检测,来实现对人摔倒过程的识别并自动报警。
1.3 项目实施的创新与特色
目前基于视觉的家庭安全监护的系统很多,但大多都是固定式安装,成本高、灵活性较差,对于一些突发情况无法预知并及时预警,总体智能性不高。
本系统以移动小车平台为载体,在主体硬件方面采用STM32微处理器为核心的开发板,此开发板可为小车移动平台提供三路直流电机驱动,为摄像头OV7725提供5V/3.3V电源接口以及图像传输所需IIC接口,并配备OLED显示屏及JLINK接口,方便人机交互与程序调试。软件方面采用MicroPython系统可以通过Python脚本语言开发单片机程序,同时使用Opencv3.4.3以及其他图像处理库,可以缩短系统开发时间,提高系统开发效率。
以实验平台为基础,“基于移动式家庭安全监护系统”可以分为四个模块,图像视觉模块、图像处理模块、运动分析决策模块、机器控制执行模块。分别负责环境感知、目标提取、行为检测、跟踪报警,从而形成一套完整的监护系统。
与传统安全监护相比其具有低成本、高灵活性等优势,并结合视觉传感器信息丰富的特点,深度解析周围环境信息,能够实现移动小车基于室内环境的自主行进能力。通过机器人对目标的跟踪,即保证了对目标的实时监控,又节约了成本。同时利用对目标的行为检测,实现自动报警,解决了被监护人失去报警能力时,家属不能及时知晓的尴尬问题发生。
2 项目基本情况
2.1 项目进程
2018年7月–8月,查阅文献,搜集相关资料等。
2018年9月–10月,制定设计方案,对方案的可行性进行初步验证,并对方案进行更改确定方案。
2018年11月–2019年4月, 设计调试摄像头以及小车主控的各个模块,完成实体部分并调试系统的可靠性、稳定性以及实用性,发表研究论文。
2019年5月,撰写结题材料,完成论文以及项目研究总结报告,结题。
2.2 项目研究内容
1.在现有研究的基础上,如何在未知环境下更加有效的检测出障碍物并对静态和动态两种障碍物进行准确区分。
2.为了获取障碍物与小车之间的位置分布关系,需要研究如何从图像中提取出障碍物与小车之间距离的深度信息,来实现对障碍物的定位。
3.要实现最后的自主避障,还需要研究如何判断当前环境下机器人的可行区域以及实现较优或最优的路径规划。
4.为了获得监测对象实时状态,需要研究如何检测并跟踪特定目标。
5.在实现特定目标检测后,需要研究如何能够检测出目标是否发生摔倒。
3 项目具体情况
3.1 运动学分析
三轮全向移动机器人是一种可以通过自身的运动机构并借助控制系统的帮助到达指定位置或者沿指定轨迹运动的机器人。因其全方位移动的特性,其在工业、医药等领域都有着广泛的应用。因此,本系统采用三轮全向结构,不仅使系统具有高度的灵活型,而且通过运动学分析能够实现控制智能小车向任意方向运动以及向任意角度旋转。
3.1.1 运动建模
为了实现对智能小车运动方向及速度的精准化控制,此小节将会结合小车硬件结构,通过对移动部分的硬件结构进行基础的运动学分析,利用几何关系导出小车在运动过程中的关键参数,然后利用程序语言,对其实际结论进行验证;为进一步简化数学模型,减少不必要的影响因素,做出以下几条假设:
(1)忽略地面摩擦力对系统的影响;(2)电机轴线中心正是底盘重心;(3)各轮之间是绝对的互成 120°安装。
如图3.1所示,对智能小车的移动方向做出规定。 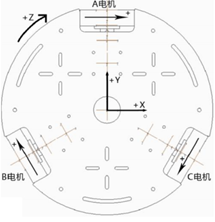
通过简单的速度分解,可以得到以下公式:

ω为智能避障小车的角速度,L为全向轮中心与底盘中心的距离,
分别为 3 个轮子的转速,
为机器人的 X、Y 方向的行进速度。

3.1.2 运动分解算法实现
根据以上的分析,并将数学关系使用语言编程实现,具体代码如下:
#define X_PARMETR (0.5f)
#define Y_PARMETR (sqrt(3)/2.f)
#define L_PARMETR (1.0f)
void Kinematic_Analysi(float Vx, float Vy, float Vz)
{
Target_A = Vx + L_PARMETR*Vz;
Target_B = -X_PARMETR*Vx + Y_PARMETR*Vy + L_PARMETR*Vz;
Target_C = -X_PARMETR*Vx - Y_PARMETR*Vy + L_PARMETR*Vz;
}
通过程序计算分别得到三个电机的目标速度,将各目标速度输入PID控制系统,即可实现智能小车在特定方向上的行进。控制原理图如3.2所示。

3.2 障碍物检测
障碍检测是智能避障小车在自主避障的过程中发挥着重要的作用。通过单目视觉的结构来检测障碍物,同时为了提升数据的有效性,摄像头必须选择合适的仰俯角,但同时必然会产生一定的视觉盲区。因此这就使得智能避障小车运行时起始位置必须没有障碍物以及合适的光照环境成为了实验必备条件之一。
智能避障小车的前进过程中,通过摄像头模块采集图像,并不断检查采集的图像以确定图像中是否出现障碍物。当在获取的图像中检测到障碍物时,进一步处理图像,并且提取障碍物的轮廓以获得相关信息。由于小车处于不断的运动状态中,因此需要快速准确地检测图像,否则,平台可能会因没有足够的时间来判断而和障碍物发生碰撞。 当检测图像中的障碍物时,首先,需要对获得的图像进行空间变换。结果如图3.3(b)所示;在图3.3(b)基础上通过图像平滑处理,消除图像噪点,获得图3.3(c);最后,使用膨胀与腐蚀运算对图像细节进一步处理,得到最终图像3.3(d)。


3.3 障碍物定位
智能避障小车在自主避障中对障碍物定位也是一个重要的技术,它依靠视觉同时利用图像处理技术对障碍物的方位和距离等信息进行分析,提取出每个障碍物的定位数据,并更加精确的定位数据将对后续起到重要的控制决策作用。由于摄像头获取图像数据时会将环境信息从三维空间投影到二维空间,这直接导致了二维空间的图像比三维空间的图像缺少一些必要的深度信息,因此需要在利用机器视觉技术对障碍物深度信息进行提取时需要尽量减小误差的产生,并确保智能避障小车在障碍物测量的过程中具有实时性,这些都是非常必须需要注意的问题。
本文采用单目视觉系统,依据针孔成像原理建立几何模并从中计算出障碍物的距离和角度,以准确定位障碍物,无需事先标定摄像机内部。想要实现对障碍物的定位首先需要提取出其在原始图像上的坐标信息,又因为图像二值化后其中的物体会表现为单独的孤立区域,所以只需搜索图像中每个孤立区域的范围即可确定障碍物的区域与范围。对于每一个障碍物来说,都会得到一个元组坐标信息(x, y, w, h)。最后根据元组坐标信息,标记出每个障碍物即可,实验结果如图3.4所示。



其中
和h都可以由实际测量得到,由式(3.3)、(3.4)、(3.5)可得出:

以上公式中
是图像总行数和
是图像总列数;v 是点Q’(u,v)图像坐标系的纵坐标;u是点Q’(u,v)图像坐标系的横坐标;y是图像纵坐标v在地平面坐标系下的对应坐标值;x是图像横坐标u在地平面坐标系下的对应坐标值;而L是图像平面上任意点Q’(u,v)在实际空间中对应的实际距离。
3.4 智能小车的避障策略
在智能小车独立运行的工作环境中,需要检测并避开障碍物,首先,需要从摄像头获取周围环境数据,再通过图像处理技术从中提取出有价值的信息,最终经过避障策略模块计算完成避障任务。避障策略是以视觉传感器系统感受到的周围环境信息为基础所建立的比较合理的数学模型,在智能小车前进过程中,对环境做出全面判断,及时避免所有障碍,保障智能小车无碰撞安全,能够自主完成空间内设置的作业任务。
3.4.1 智能小车的模糊控制原理
由于智能小车工作环境的未知性,设计系统时很难用一个数学模型来描述多变的未知环境,最终决定采用模糊控制法作为系统的避障策略。模糊控制的不同之处在于其是通过预先设定好的大量条件规则来实现控制的。以往的控制系统在对原有控制系统进行控制时,需要建立一个精确的数学模型,即系统内各变量之间的数学关系表达式,然后再对其进行更深入的研究和分析。然而,在长期实践中,发现一些复杂的控制系统虽然无法建立精确的数学模型,不能通过传统的控制方法实现系统控制,但可以通过人工经验获得不错的结果。
模糊控制通过模拟人的思维,利用已有的语言变量进行经验推理,并整合人的控制经验到集成控制系统中,从而使控制系统完成控制操作。由于模糊控制器的设计是借助于人工经验而实现的,故不需要了解对象的数学模型和内部结构,这将有利于实现将复杂系统简单化。同时其能利用模糊推理和集合论将转化为数学函数形式,便于计算机软件的实现,通过实际测试,具有良好的适应性。
模糊控制器是模糊控制的核心,其结构如图3.6所示。


3.4.2 智能小车的模糊策略设计
模糊控制系统通过获取特定的环境数据,来实现推理过程,并依据规则表最终输出对应的避障动作。如图3.7所示,共有4个输入分别为智能小车正前方的距离、智能小车左前方的距离、智能小车右前方的距离以及智能小车的方位角,它们分别对应于dF,dL,dR和θ。当多个障碍同时出现在图像视野中时,将最接近智能小车的障碍物作为优先选择对象。模糊控制器最终将返回智能小车需要旋转的角度φ,将决定智能小车是否移动或转弯。
通过视觉感知技术测量计算出障碍物的距离,并设定障碍物距离相对应的语言变量定义为:Far=远,Near=近;对于模糊控制器而言,该模糊语言集合将同样被用于描述智能小车前方三个方向上的障碍物距离的输入。同时使用线性函数来降低计算复杂度并相应地提高处理速度,如图3.7所示。
由于系统采用单目摄像头,考虑到其视野角度范围较小,系统中设定其角度的论域范围在{-30°,30°}之间。输入角度θ为智能小车正前方向与障碍物的夹角,以其为输入获得转动角φ的最终输出。设置φ和θ的语言集合为{LB=Left Big,LS=Left Small,Z=Zero,RS=Right Small、RB=Right Big},如图3.8所示,纵坐标方向代表隶属度的大小,横坐标方向代表角度的大小,其中负角度代表方向左,正角度代表方向右。

R1:if (dF=Far && dL=Far && dR=Far && θ=Z) then Z
根据图3.9(b)所示,可以设置如下规则:
R2:if (dF=Far && dL=Near && dR=Far && θ=LB) then RS
R3:if (dF=Far && dL=Near && dR=Far && θ=LS) then RB
R4:if (dF=Far && dL=Far && dR=Far && θ=LB) then RS
R5:if (dF=Far && dL=Far && dR=Far && θ=LS) then RB
根据图3.9 ©所示,可以设置确定如下规则:
R6:if (dF=Near && dL=Far && dR=Far && θ=Z) then RB
R7:if (dF=Far && dL=Far && dR=Far && θ=LS) then RS
根据图3.9 (d)所示,可以设置确定如下规则:
R8:if (dF=Far && dL=Far && dR=Near && θ=RB) then LS
R9:if (dF=Far && dL=Far && dR=Near && θ=RS) then LB
R10:if (dF=Far && dL=Far && dR=Far && θ=RB) then LS
R11:if (dF=Far && dL=Far && dR=Far && θ=RS) then LB
在实际的操作过程中,当某一方向上没有障碍物时,障碍物在该方向上的距离可视为无穷远。通过以上建立的规则,其推理过程就是if-then语句逻辑执行过程。
3.5 YOLO特定目标识别
Yolo是一个端到端的目标检测算法,不需要预先提取region proposal(RCNN目标检测系列),通过一个网络就可以输出:类别,置信度,坐标位置,具有很快的目标检测速度。Yolo算法的基本思想是:首先通过特征提取网络对输入特征提取特征,得到特定大小的特征图输出。输入图像分成S×S的grid cell,接着如果真实框中某个object的中心坐标落在某个grid cell中,那么就由该grid cell来预测该object。
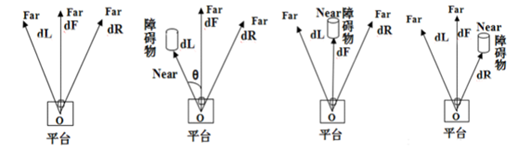
3.5.1 YOLO v3 算法结构
Yolo v3整个算法结构,如图3.10所示。该结构中不包括池化层和全连接层。Yolo主干结构是Darknet-53网络,还有Yolo预测支路采用的都是全卷积的结构。

for i, c in reversed(list(enumerate(out_classes))):
predicted_class = self.class_names[c]
box = out_boxes[i]
score = out_scores[i]
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
其中字符串变量predicted_class表示目标类型,故只需在程序标记目标前判断predicted_class是否等于’person’即可实现只检测人物目标,修改后的代码如下。
for i, c in reversed(list(enumerate(out_classes))):
predicted_class = self.class_names[c]
box = out_boxes[i]
score = out_scores[i]
label = '{} {:.2f}'.format(predicted_class, score)
if predicted_class=='person':
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
3.5.3 人物识别与跟踪
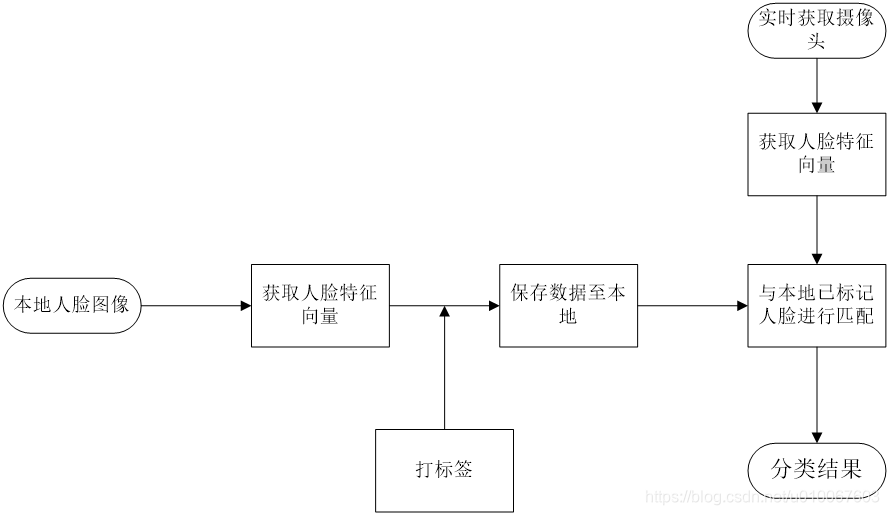
本文使用dlib中提供的人脸检测方法(使用HOG特征或卷积神经网方法),并使用提供的深度残差网络(ResNet)实现实时基于人脸的人物识别,不过本文的目的不是构建深度残差网络,而是利用已经训练好的模型进行实时人脸识别,实时性要求一秒钟达到10帧以上的速率,并且保证不错的精度。
人脸识别分为人脸检测和识别两个阶段,人脸检测会找到人脸区域的矩形窗口,识别则通过ResNet返回人脸特征向量,并进行匹配。
(1)人脸检测阶段。人脸检测算法需要用大小位置不同的窗口在图像中进行滑动,然后判断窗口中是否存在人脸。在深度学习之前的主流方法是特征提取+集成学习分类器,比如以前火热的haar特征+adaboost级联分类器,opencv中实现的人脸检测方法就采用了这种,不过实验结果来看,这种检测方法效果很不好,经常误检测人脸,或者检测不到真实的人脸;dlib中使用的是HOG(histogram of oriented gradient)+ 回归树的方法,使用dlib训练好的模型进行检测效果要好很多。dlib也使用了卷积神经网络来进行人脸检测,效果好于HOG的集成学习方法,不过需要使用GPU加速,提高图像处理速度。
(2)识别阶段。识别也就是我们常说的“分类”,摄像头采集到人脸后,让机器判断是目标是否存在数据库中。分类分为两个部分:
① 特征向量抽取。本文用到的是dlib中已经训练好的ResNet模型的接口,此接口会返回一个128维的人脸特征向量。
② 距离匹配。在获取特征向量之后可以使用欧式距离和本地的人脸特征向量进行匹配,使用最近邻分类器返回样本的标签。
根据以上,人脸识别的大致过程如下:
3.6 人物摔倒检测
人体跌倒识别步骤一般包含为:
(1)人体特征检测:此阶段需要把人从背景中提取出来,并处理得到需要的人体特征;
(2)动作识别:将提取的特征作为跌倒行为的判断依据,对特征进行分析和处理。
我们都知道人体在跌倒过程中,人体的重心点从较高的位置快速下降到了地面或者接近地面的高度。在此过程中人体的高度和重心的位置等都会快速的发生改变。要进行人体跌倒检测,首先需要在图像中人体的确切位置,然后用红色矩形框标记出来,计算出矩形框的高H和宽L,然后再根据高宽的比例来判断人体的姿态。这种方法存在缺点,会有判断失误的情况发生,因为人的活动丰富多彩决定了其自由度非常大,可能出现很多干扰严重的情况,给判断造成误导。
其实对于大部分真正跌倒的情况,仅用人体的高宽比例是可以检测出来的,但会出现很多误检的情况(不是跌倒的动作也被认为成是跌倒),为了提高算法的精确性,我们需要降低误检率。
而在实际测试中我们发现,人在真正的跌倒时速度较快,且有重心下降的趋势,根据这样人体这样特性,可以排除很多伪跌倒。所以第二个检测特征即检测速度。通过连续的视频帧,来计算身体重心的速度,如果该速度超过给定阈值,再认定为跌倒事件发生。
4 智能小车系统的实现与结果分析
本章以运动控制模块、图像处理模块、障碍物定位、距离测量模块以及避障策略模块为软件基础,主控板、摄像头和电机驱动器等作为硬件核心,实现了该系统的样机模型设计。实际测试结果表明,该避障小车系统能够依赖视觉系统,并依赖算法程序实现自主避障,这证明该方案是可行的。
4.1 智能小车硬件实现
智能小车采用全向轮底盘作为移动平台,安装并连接了三路自带编码器的直流电机到主控版的接口上来驱动智能小车移动;架设了OpenMV摄像头模块作为图像处理的主要传感器;使用了MPU-6050陀螺仪传感器来检测小车的旋转角度;然后,通过OLED模块显示相关调试参数,SWD接口在线调试程序,蓝牙模块串口传输调试信息。同时配备了12.5V的电池模块,为系统运行提供能量。最后通过STM32F7微控制器控制各个系统模块,使整个系统能够正常、协调、统一地高效率运行。

4.2 智能小车软件调试
完成系统的搭建后,需要对整个智能小车平台进行硬件测试和软件调试。对于硬件方面来说,只需检查底层驱动有无异常即可。比如编码器捕获脉冲是否正确或者陀螺仪输出角度是否稳定等。
在软件方面,通过串口线把主控板与PC机相互连接,主控中的Micropython系统启动时会自动挂载文件系统,在调试过程中只需将程序代码保存在文件系统根目录下系统即可自动运行。对于障碍物检测算法,需要验证其在实际应用中的效果,测试是否存在漏检、错检问题,同时对有问题的地方进行调试优化;对于障碍物定位算法,需要先确定摄像头的相关外部参数,然后选取一些像素点进行距离的转换测试,最后再对测试结果进行误差分析。对于避障策略算法,通过设置模拟多种障碍物的分布情况,以验证模糊控制集合的有效性,同时对测试过程中出现的问题及时修正,改进现有规则条件的不足。
最后,对整体智能小车平台进行测试。如图4.2所示,整个系统运行时的相关调试信息可以通过串行端口在软件下方显示出来。
4.3 实验结果及分析
通过对智能小车样机模型的实际测试,来验证各个算法模块在实际应用中的效果,并针对现有问题来进一步优化、改进系统各个模块的内部算法以提高整体系统的软件实时性、合理性、协调性及统一性。
4.3.1 障碍物检测算法调试
在障碍物检测调试过程中,经过反复实验,发现光的不均匀分布将会一定程度上影响对图像分割的准确性。如图4.3(a) 所示,从图中可以看到,地面局部区域的光线的是非常不均匀分布。使用传统的固定阈值法,这将会使得部分图像分割错误,如图4.3(b)所示。而使用该论文提出的自适应阈值法对该地面场景提前采用,则会得到改善后的实验结果,如图4.3©所示。


4.3.2 障碍物定位算法调试
在确定障碍物定位算法的原理后实现其并不困难,由于此模型的缺点是定位精度会随着摄像头仰俯角的不同而变化,这里的主要的工作是在于确定最为合适摄像头的外部参数,以减少计算误差。实验中经过不断测试最终确定摄像头的各外部参数如下:h=16.5 cm,
。由公式(4.3)、(4.4)、(4.5) 可得,α=60.14°,β=13.40°,γ=50.33°。将以上参数代入公式(4.6)、(4.7)、(4.8),随机选取图像坐标进行定位测试,结果如表4.1所示。
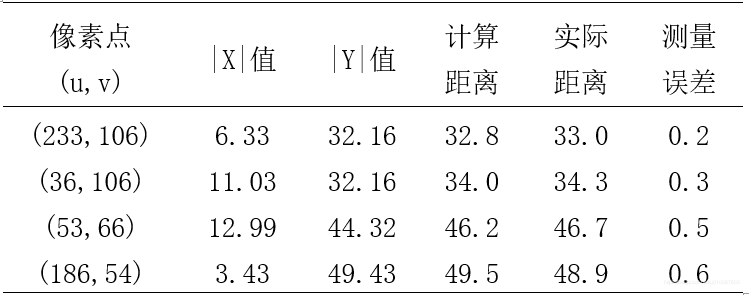
表4.1说明了摄像头在此外部参数下最大误差是小于1 cm的。对于障碍物避障系统来说,这样的定位误差是允许的,验证了该定位算法的有效性。
4.3.3 避障策略算法调试
通过使用模糊控制建立的规则,整个系统的自主避障效果如图4.5(a)、4.5(b)、4.5(c)、4.5(d)所示。




从实际的测试结果来看,该系统在外界环境较为良好的情况下,能够实现对复杂障碍物的实时性避障,证明该系统具有实际的可行性。
4.4.4 特定人物目标识别
通过Yolo网络检测出一帧图像中的人物目标,再针对人物区域进行人脸检测,以提高算法执行效率。为了实现系统对特定人物的检测,需要提前将需要检测目标的人脸特征进行提取和保存。然后再通过此128维人脸特征和检测到的人脸进行匹配,从而实现对特定人物的检测与识别,实验测试图如图4.6所示。

4.4.5 人物摔倒检测
通过对识别到的特定目标进行检测,判断其所在区域的高宽比例并结合人物的重心位置的变化,实现对人物的摔倒检测。如图4.7所示。


5 项目完成工作及成果
(1)完成了智能家庭安全移动式监护机器人系统的组装调试和软件算法设计。
(2)根据静态障碍物与动态障碍物的不同特征,实现了基于室内静态与动态障碍物的检测与区分。
(3)在识别出静态障碍物的基础上,依据针孔成像原理建立几何模型,实现了静态障碍物到小车前端的实际距离测量,并融合障碍物当前位置计算小车的可行性区域范围。
(4)实现了基于人脸识别检测特定人物目标。
(4)在检测到特定人物目标的基础上,根据人摔倒时的形态以及重心变化,实现了对特定人物的摔倒检测。
(5) 2018年12月向目前国内最具权威性、发行量最大的电子技术月刊“电子技术”投稿被录用,论文题名“智能小车单目视觉障碍检测及避障系统设计”。(刊号:ISSN1000-0755 CN31-1323/TN 2018-12)。
6 项目总结
通过一年的奋斗努力,在本次项目设计过程中,经过指导老师以及成员的努力,克服种种困难,最终实现了预期目标。学习并掌握了基于视觉与图像技术的智能家庭安全移动式监护机器人系统的软硬件平台工作原理和控制技术。能够利用传感器来获取未知环境信息,并实现自主行进与人体摔倒检测。在此项目中,我们学会了许多图像处理算法原理和软件实现,以及硬件资源的整合搭建,增强了对新技术新知识的理解吸收能力,提高了自身的知识储备和实践动手能力。在这次项目中我们不仅把学到的知识良好的运用到这次的项目研究中,而且从中又获得了一些知识,同时为以后的项目制作积累了一点经验。
7 补证书


