一周爬虫集训任务一:学习get与post请求+正则表达式
1 任务
【任务一】(3天)
1.1 学习get与post请求
学习get与post请求,尝试使用requests或者是urllib用get方法向https://www.baidu.com/发出一个请求,并将其返回结果输出。
如果是断开了网络,再发出申请,结果又是什么。了解申请返回的状态码。
了解什么是请求头,如何添加请求头。
1.2 正则表达式
学习什么是正则表达式并尝试一些正则表达式并进行匹配。
然后结合requests、re两者的内容爬取https://movie.douban.com/top250 里的内容
要求抓取名次、影片名称、年份、导演等字段。
参考资料: https://desmonday.github.io/2019/03/02/python爬虫学习-day2正则表达式/
2 get与post请求
2.1 get与post的区别
-
HTTP和HTTPS分别是什么?
HTTP协议(超文本传输协议): 是一种发布和接收HTML页面的方法,其设计目的是保证客户机与服务器之间的通信,HTTP 的工作方式是客户机与服务器之间的请求-应答协议。HTTPS: 简单讲就是HTTP的安全版,在HTTP下加入SSL层。
举例:客户端(浏览器)向服务器提交** HTTP 请求**;服务器向客户端返回响应。响应包含关于请求的状态信息以及可能被请求的内容。
-
两种 HTTP 请求方法:get 和 post
在客户机和服务器之间进行请求-响应时,两种最常被用到的方法是:get 和 post。本质: get和post本质上都是TCP链接,并无差别,只是由于HTTP的规定和浏览器/服务器的限制,导致他们在应用过程中体现出一些不同。
get - 用于从服务器上获取数据;get产生一个TCP数据包;对于get方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);
post - 用于向服务器传送数据;post产生两个TCP数据包;对于post,浏览器先发送header,服务器响应100(continue),然后再发送data,服务器响应200(返回数据)。
2.2 requests库和urllib库的区别
在使用python爬虫时,需要模拟发起网络请求,主要用到的库有requests库和python内置的urllib库,一般建议使用requests,它是对urllib的再次封装,它们使用的主要区别:
requests可以直接构建常用的get和post请求并发起,urllib一般要先构建get或者post请求,然后再发起请求。
然后分别用requests库和urllib库向百度发送一个请求,并将其返回结果输出。
- requests发送请求
## requests发送请求
import requests
url = "https://www.baidu.com"
##发送get请求
r = requests.get(url)
##改变编码方式
r.encoding = 'utf-8'
##获取响应内容
print(r.text)结果如下:
<!DOCTYPE html>
<!--STATUS OK--><html> <head><meta http-equiv=content-type content=text/html;charset=utf-8><meta http-equiv=X-UA-Compatible content=IE=Edge><meta content=always name=referrer><link rel=stylesheet type=text/css href=https://ss1.bdstatic.com/5eN1bjq8AAUYm2zgoY3K/r/www/cache/bdorz/baidu.min.css><title>百度一下,你就知道</title></head> <body link=#0000cc> <div id=wrapper> <div id=head> <div class=head_wrapper> <div class=s_form> <div class=s_form_wrapper> <div id=lg> <img hidefocus=true src=//www.baidu.com/img/bd_logo1.png width=270 height=129> </div> <form id=form name=f action=//www.baidu.com/s class=fm> <input type=hidden name=bdorz_come value=1> <input type=hidden name=ie value=utf-8> <input type=hidden name=f value=8> <input type=hidden name=rsv_bp value=1> <input type=hidden name=rsv_idx value=1> <input type=hidden name=tn value=baidu><span class="bg s_ipt_wr"><input id=kw name=wd class=s_ipt value maxlength=255 autocomplete=off autofocus=autofocus></span><span class="bg s_btn_wr"><input type=submit id=su value=百度一下 class="bg s_btn" autofocus></span> </form> </div> </div> <div id=u1> <a href=http://news.baidu.com name=tj_trnews class=mnav>新闻</a> <a href=https://www.hao123.com name=tj_trhao123 class=mnav>hao123</a> <a href=http://map.baidu.com name=tj_trmap class=mnav>地图</a> <a href=http://v.baidu.com name=tj_trvideo class=mnav>视频</a> <a href=http://tieba.baidu.com name=tj_trtieba class=mnav>贴吧</a> <noscript> <a href=http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2f%3fbdorz_come%3d1 name=tj_login class=lb>登录</a> </noscript> <script>document.write('<a href="http://www.baidu.com/bdorz/login.gif?login&tpl=mn&u='+ encodeURIComponent(window.location.href+ (window.location.search === "" ? "?" : "&")+ "bdorz_come=1")+ '" name="tj_login" class="lb">登录</a>');
</script> <a href=//www.baidu.com/more/ name=tj_briicon class=bri style="display: block;">更多产品</a> </div> </div> </div> <div id=ftCon> <div id=ftConw> <p id=lh> <a href=http://home.baidu.com>关于百度</a> <a hr- urllib发送请求
## urllib发送请求
import urllib.request
url = "https://www.baidu.com"
html = urllib.request.urlopen(url).read()
data = html.decode("utf-8")
print(data)结果如下:
<html>
<head>
<script>
location.replace(location.href.replace("https://","http://"));
</script>
</head>
<body>
<noscript><meta http-equiv="refresh" content="0;url=http://www.baidu.com/"></noscript>
</body>
</html>2.3 断网后发出申请的结果
- requests发送请求
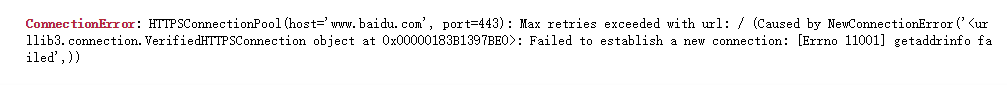
- urllib发送请求

2.4 申请返回的状态码
- Python中获取网页状态码的两个方法
- requests中可以用.status_code函数获取状态码。
import requests
code=requests.get("https://www.baidu.com").status_code
print(code)结果为:200
- urllib中可以用.code函数获取状态码。
import urllib.request
status=urllib.request.urlopen("https://www.baidu.com").code
print(status)结果为:200
-
状态码介绍
HTTP状态码的英文为HTTP Status Code。状态代码由三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。
1xx:指示信息–表示请求已接收,继续处理。
2xx:成功–表示请求已被成功接收、理解、接受。
3xx:重定向–要完成请求必须进行更进一步的操作。
4xx:客户端错误–请求有语法错误或请求无法实现。
5xx:服务器端错误–服务器未能实现合法的请求。常见状态代码、状态描述的说明如下。
200 OK:客户端请求成功。
400 Bad Request:客户端请求有语法错误,不能被服务器所理解。
401 Unauthorized:请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用。
403 Forbidden:服务器收到请求,但是拒绝提供服务。
404 Not Found:请求资源不存在,举个例子:输入了错误的URL。
500 Internal Server Error:服务器发生不可预期的错误。
503 Server Unavailable:服务器当前不能处理客户端的请求,一段时间后可能恢复正常。
状态码详细列表可见参考4状态码列表
2.5 什么是请求头,如何添加请求头
一个HTTP请求报文由请求行(request line)、请求头(header)、空行和请求数据4个部分组成。
-
请求头定义: 通俗来讲,就是能够告诉被请求的服务器需要传送什么样的格式的信息。
HTTP客户程序(例如浏览器),向服务器发送请求的时候必须指明请求类型(一般是GET或者POST)。如有必要,客户程序还可以选择发送其他的请求头。大多数请求头并不是必需的,但Content-Length除外。对于POST请求来说Content-Length必须出现。
常用请求头可见:参考5常用的HTTP请求头与响应头
-
添加请求头
请求头部由关键字/值对组成,每行一对,关键字和值用英文冒号“:”分隔。请求头部通知服务器有关于客户端请求的信息。
(1)在requests中添加请求头:
##1.在requests中添加请求头:
import requests
url = "http://baidu.com"
## 请求头信息
header = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*,q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive' }
r = requests.post(url, headers=header)
head = r.headers #响应头
print(head)
print('-'*80)
print(r.request.headers) #请求头结果为:
{'Date': 'Sat, 06 Apr 2019 14:18:06 GMT', 'Server': 'Apache', 'Last-Modified': 'Tue, 12 Jan 2010 13:48:00 GMT', 'ETag': '"51-47cf7e6ee8400"', 'Accept-Ranges': 'bytes', 'Content-Length': '81', 'Cache-Control': 'max-age=86400', 'Expires': 'Sun, 07 Apr 2019 14:18:06 GMT', 'Connection': 'Keep-Alive', 'Content-Type': 'text/html'}
--------------------------------------------------------------------------------
{'User-Agent': 'python-requests/2.19.1', 'Accept-Encoding': 'gzip, deflate, br', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*,q=0.8', 'Connection': 'keep-alive', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Cont(2)在urllib中添加请求头:
##2.在urllib中添加请求头:
import urllib.request
url = "https://www.baidu.com"
header = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*,q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive' }
request = urllib.request.Request(url=url,headers=header)
resp =urllib.request.urlopen(request)
print(resp.headers)结果为:
Accept-Ranges: bytes
Cache-Control: no-cache
Content-Length: 227
Content-Type: text/html
Date: Sat, 06 Apr 2019 14:28:00 GMT
Etag: "5c9c7bd5-e3"
Last-Modified: Thu, 28 Mar 2019 07:46:29 GMT
P3p: CP=" OTI DSP COR IVA OUR IND COM "
Pragma: no-cache
Server: BWS/1.1
Set-Cookie: BD_NOT_HTTPS=1; path=/; Max-Age=300
Set-Cookie: BIDUPSID=03DAF39DA0960819ADF4D9075702C9C0; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: PSTM=1554560880; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Strict-Transport-Security: max-age=0
X-Ua-Compatible: IE=Edge,chrome=1
Connection: close3 正则表达式
3.1 什么是正则表达式
-
正则表达式定义: 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
python正则表达式: re模块使python语言拥有全部的正则表达式功能。 -
为什么使用正则表达式?
通过使用正则表达式,可以:
(1)测试字符串内的模式。例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称为数据验证。
(2)替换文本。可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它。
(3)基于模式匹配从字符串中提取子字符串。可以查找文档内或输入域内特定的文本。 -
使用步骤:
(1)使用compile()函数将正则表达式的字符串编译成一个pattern对象
(2)通过pattern对象的一些方法对文本进行匹配,匹配结果是一个match对象
(3)用match对象的方法,对结果进行操作 -
常用方法:
(1)re.match: 从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
函数语法:re.match(pattern, string, flags=0)
函数参数说明:pattern:匹配的正则表达;string:要匹配的字符串;flags:标志位,用于控制正则表达式的匹配方式我们可以使用
group(num)或groups()匹配对象函数来获取匹配表达式。匹配对象方法 描述 group(num=0) 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 groups() 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 实例代码:
##正则化 import re print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配 print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配结果为:
(0, 3) None(2)re.search:从任何位置开始查找,返回第一个成功的匹配。匹配成功re.search方法返回一个匹配的对象,否则返回None。
函数语法:re.search(pattern, string, flags=0)
函数参数说明:pattern:匹配的正则表达;string:要匹配的字符串;flags:标志位,用于控制正则表达式的匹配方式实例代码:
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配 print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配结果为:
(0, 3) (11, 14)re.match与re.search的区别: re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配 整个字符串 ,直到找到一个匹配。
(3)re.sub: Python 的 re 模块提供了re.sub用于替换字符串中的匹配项
函数语法:re.sub(pattern, repl, string, count=0, flags=0)
函数参数说明:pattern:正则中的模式字符串;repl:替换的字符串,也可为一个函数;string:要被查找替换的原始字符串;count:模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。实例代码:
##re.sub用于替换字符串中的匹配项。 import re phone = "2004-959-559 # 这是一个国外电话号码" # 删除字符串中的 Python注释 num = re.sub(r'#.*$', "", phone) print("电话号码是: ", num) # 删除非数字(-)的字符串 num = re.sub(r'\D', "", phone) print("电话号码是 : ", num)结果为:
电话号码是: 2004-959-559 电话号码是 : 2004959559(4)re.compile 函数: compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
函数语法:re.compile(pattern[, flags])
函数参数说明:pattern:一个字符串形式的正则表达式;flags:可选,表示匹配模式,比如忽略大小写,多行模式等。(5)re.findall函数: 在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次, findall 匹配所有。
函数语法:findall(string[, pos[, endpos]])
函数参数说明:string:待匹配的字符串;pos:可选参数,指定字符串的起始位置,默认为 0;endpos:可选参数,指定字符串的结束位置,默认为字符串的长度。实例代码:
## findall 匹配所有 pattern = re.compile(r'\d+') # 查找数字 result1 = pattern.findall('runoob 123 google 456') result2 = pattern.findall('run88oob123google456', 0, 10) print(result1) print(result2)结果为:
['123', '456'] ['88', '12'](6)re.finditer函数: 和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
函数语法:re.finditer(pattern, string, flags=0)
函数参数说明:pattern:匹配的正则表达式;string:要匹配的字符串;flags:标志位,用于控制正则表达式的匹配方式。实例代码:
import re it = re.finditer(r"\d+","12a32bc43jf3") for match in it: print (match.group() )输出结果:
12 32 43 3(7)re.split函数: split 方法按照能够匹配的子串将字符串分割后返回列表
函数语法:re.split(pattern, string[, maxsplit=0, flags=0])
函数参数说明:pattern:匹配的正则表达式;string:要匹配的字符串;maxsplit:分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数;flags:标志位,用于控制正则表达式的匹配方式。代码实例:
##split分割 a = re.split('\W+', 'runoob, runoob, runoob.')##\W 匹配非字母数字及下划线 print(a)输出结果:
['runoob', 'runoob', 'runoob', ''] -
正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式:
(1)字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
(2)多数字母和数字前加一个反斜杠时会拥有不同的含义。
(3)标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
(4)反斜杠本身需要使用反斜杠转义。
(5)由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r’\t’,等价于 ‘\t’)匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。模式 描述 ^ 匹配字符串的开头 $ 匹配字符串的末尾 . 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符 […] 用来表示一组字符,单独列出:[amk] 匹配 ‘a’,‘m’或’k’ [^…] 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符 re* 匹配0个或多个的表达式 re+ 匹配1个或多个的表达式 re? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 re{ n} 精确匹配 n 个前面表达式。例如, o{2} 不能匹配 “Bob” 中的 “o”,但是能匹配 “food” 中的两个 o。 re{ n,} 匹配 n 个前面表达式。例如, o{2,} 不能匹配"Bob"中的"o",但能匹配 "foooood"中的所有 o。“o{1,}” 等价于 “o+”。“o{0,}” 则等价于 “o*”。 re{ n, m} 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式 (re) 匹配括号内的表达式,也表示一个组 (?imx) 正则表达式包含三种可选标志:i, m, 或 x 。只影响括号中的区域 (?-imx) 正则表达式关闭 i, m, 或 x 可选标志。只影响括号中的区域 (?: re) 类似 (…), 但是不表示一个组 (?imx: re) 在括号中使用i, m, 或 x 可选标志 (?-imx: re) 在括号中不使用i, m, 或 x 可选标志 (?#…) 注释. (?= re) 前向肯定界定符 (?! re) 前向否定界定符 (?> re) 匹配的独立模式,省去回溯 \w 匹配字母数字及下划线 \W 匹配非字母数字及下划线 \s 匹配任意空白字符,等价于 [\t\n\r\f] \S 匹配任意非空字符 \d 匹配任意数字,等价于 [0-9] \D 匹配任意非数字 \A 匹配字符串开始 \Z 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串 \z 匹配字符串结束 \G 匹配最后匹配完成的位置 \b 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 \B 匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 \n, \t, 等. 匹配一个换行符。匹配一个制表符。等 \1…\9 匹配第n个分组的内容 \10 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式 -
贪婪与非贪婪模式
(1)贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配
(2)非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配(多加个?)
(3)python里面数量词默认是贪婪模式代码实例:
##贪婪模式 import re s = "abbbbbbc" pattern1 = re.compile("ab+")#贪婪 pattern2 = re.compile("ab*?")#非贪婪 m1 = pattern1.match(s) m2 = pattern2.match(s) s1 = m1.group() s2 = m2.group() print(s1) #贪婪模式,abbbbbb print(s2) #非贪婪模式,a,尽可能少匹配b所以没有b结果为:
abbbbbb a -
匹配中文
(1)中文是Unicode编码(utf-8也是Unicode编码),范围:主要在[u4e00-u9fa5]
(2)中文全角逗号一类的不在[u4e00-u9fa5]范围内
3.2 爬虫实战
实战要求:
- 结合requests、re两者的内容爬取豆瓣电影Top 250里的内容
- 要求抓取名次、影片名称、国家、导演等字段。
思路分析:
- 由于豆瓣电影网页每一页默认只有25部电影信息,所以每翻一页,网页的URL就会变化。首页的URL为:
https://movie.douban.com/top250?start=0&filter=,第二页的URL为:https://movie.douban.com/top250?start=25&filter=,第三页的URL为:https://movie.douban.com/top250?start=50&filter=,以此类推,所以可以使用一个while循环来遍历网页:
while page <= 225:
url = "https://movie.douban.com/top250?start=%s&filter=" % page-
分析网页信息,鼠标右键点击网页选择查看网页源代码即可查看页面信息。
-
首先找到我们需要爬取的字段:名次,影片名称,国家,导演。
名次:

影片名称:

国家和导演在一个栏目下:

相应的正则表达式为:名次:
'<em class="">(.*?)</em>
名称:'<span class="title">(.*?)</span>
导演:'.*?<p class="">.*?导演:(.*?) '
国家:'<br>.*?/ (.*?) /.*?</p>' -
最后在代码中加上请求头防止爬虫被阻止
完整代码如下:
import re, requests
##获取网站响应内容
for i in range(10):# 一共有10页数据
#请求头
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36"
}
url = "https://movie.douban.com/top250?start=" + str(i * 25) + "&filter="
movie_Num = movie_name = movie_count = movie_director = [] # 初始化数据,保证名称循环都是空的
req = requests.get(url, headers=headers)
html_reponse = req.content.decode("utf-8") # 网页信息
## 从响应内容里正则化提取所需内容
movie_Num = re.findall('<em class="">(.*?)</em>', html_reponse) # 提取名次
#print(movie_Num)
movie_name = re.findall('<span class="title">([\u4e00-\u9fa5]+)</span>', html_reponse) # 提取影片名称
#print(movie_title)
movie_director = re.findall('导演: (.*?)[ |<br>]', html_reponse) # 提取导演
#print(movie_directors)
movie_count = re.findall(' / (.*?) / ', html_reponse) # 提取国家名
#print(movie_countries)
#每一页有25个电影
for j in range(25):
#电影信息拼接
try: #处理异常
movie_info = "排名:" + movie_Num[j] + " 电影名:" + movie_name[j] + "导演:" + movie_director[j] + "国家:" + movie_count[j]
print(movie_info)
except:
print('越界')
continue结果为:

过程中遇到的问题:
- 过程中需要用到中文匹配的知识,使用[\u4e00-\u9fa5]代表中文字符
- 在抓取个别电影信息时会导致抓取错误,进而导致列表索引越界,需要加个异常处理,没有抓到的数据就将其释放。
- 还是需要优化正则条件,保证所有的信息能够匹配。
