Spark官网补缺之SparkStreaming
版本2.3.4 官网网址:http://spark.apache.org/docs/2.3.4/streaming-programming-guide.html
文章目录
- Spark官网补缺之SparkStreaming
- 1.开篇简介
- 1.1隐式转换
- 1.2创建StreamingContext
- 1.3pow依赖
- 1.4一些注意点
- 1.5DStreams
- 1.6输入和**Receiver**
- 1.7Dstream的转换
- 1.8Dstreams的输出操作
- 1.9DataFrame和SQL操作
- 2.0缓存和序列化
- 2.1checkpoint
- 2.2累加器,广播变量和检查点
- 3.运行部署
- 4.Spark Streaming + Kafka集成指南
1.开篇简介
Spark Streaming是核心Spark API的扩展,可实现实时数据流的可伸缩,高吞吐量,容错流处理。数据可以从像,kafka,flume,hdfs/s3,kinesis,TCP套接字许多来源摄入,并且可以使用与像高级别功能表达复杂的算法来处理`map`,`reduce`,`join`和`window`。最后,可以将处理后的数据推送到文件系统,数据库和实时仪表板。实际上,您可以在数据流上应用Spark的 [机器学习]和 [图形处理]算法。

在内部,它的工作方式如下。Spark Streaming接收实时输入数据流,并将数据分成批处理,然后由Spark引擎进行处理,以分批生成最终结果流。
Spark Streaming提供了称为离散流或DStream的高级抽象,它表示连续的数据流。可以根据来自Kafka,Flume和Kinesis等来源的输入数据流来创建DStream,也可以通过对其他DStream应用高级操作来创建DStream。在内部,DStream表示为RDD序列 。

1.1隐式转换
首先,我们将Spark Streaming类的名称以及从StreamingContext进行的一些隐式转换导入到我们的环境中
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._ //not necessary since Spark 1.3
1.2创建StreamingContext
该appName参数是您的应用程序显示在集群UI上的名称。 master是Spark,Mesos或YARN群集URL或特殊的"local [*]”字符串,以在本地模式下运行。实际上,当在集群上运行时,您将不希望master在程序中进行硬编码,而是在其中启动应用程序spark-submit并在其中接收。但是,对于本地测试和单元测试,您可以传递“ local [*]”以在内部运行Spark Streaming(检测本地系统中的内核数)。请注意,这会在内部创建一个SparkContext(所有Spark功能的起点),可以通过访问ssc.sparkContext。
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))
1.3pow依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.3.4</version>
<scope>provided</scope>
</dependency>
要从Spark Streaming核心API中不存在的,从诸如Kafka,Flume和Kinesis之类的源中获取数据,则必须将相应的工件添加`spark-streaming-xyz_2.11`到依赖项中。例如,一些常见的如下。
| Source | Artifact |
|---|---|
| Kafka | spark-streaming-kafka-0-10_2.11 |
| Flume | spark-streaming-flume_2.11 |
| Kinesis | spark-streaming-kinesis-asl_2.11 [Amazon Software License] |
1.4一些注意点
定义上下文之后,您必须执行以下操作。
通过创建输入DStreams来定义输入源。
通过对DStreams应用转换和输出操作来定义流计算。
开始接收数据并使用streamingContext.start()进行处理。
使用streamingContext.awaitTermination()等待处理停止(手动或由于任何错误)。
可以使用streamingContext.stop()手动停止处理。
指出,记住:
一旦上下文启动,就不能设置或添加新的流计算。
上下文一旦停止,就不能重新启动。
JVM中只能同时激活一个StreamingContext。
StreamingContext上的stop()也会停止SparkContext。
要仅停止StreamingContext,请将名为stopSparkContext的stop()的可选参数设置为false。
只要在创建下一个StreamingContext之前停止前一个StreamingContext(不停止SparkContext),就可以重用SparkContext来创建多个StreamingContext。
1.5DStreams
离散流(DStreams)
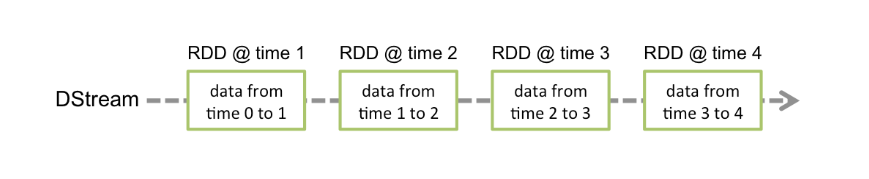
离散流或DStream是Spark Streaming提供的基本抽象。它表示连续的数据流,可以是从源接收的输入数据流,也可以是通过转换输入流生成的已处理数据流。在内部,DStream由一系列连续的RDD表示,这是Spark对不可变的分布式数据集的抽象(有关更多详细信息,请参见Spark编程指南)。DStream中的每个RDD都包含来自特定间隔的数据,如下图所示。
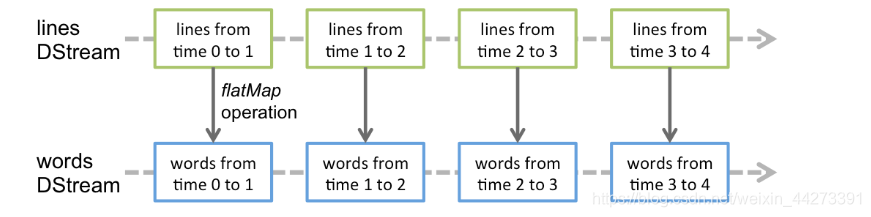
在DStream上执行的任何操作都转换为对基础RDD的操作。例如,在之前的将行流转换为单词的案例中,将`flatMap`操作应用于`lines`DStream中的每个RDD 以生成DStream的 `words`RDD。如下图所示。
这些基础的RDD转换由Spark引擎计算。DStream操作隐藏了大多数这些细节,并为开发人员提供了更高级别的API,以方便使用。这些操作将在后面的部分中详细讨论。
1.6输入和Receiver
输入DStream是表示从流源接收的输入数据流的DStream。在快速示例中,lines输入DStream代表从netcat服务器接收的数据流。每个输入DStream(文件流除外,本节稍后将讨论)都与一个Receiver对象 (Scala doc, Java doc)关联,该对象从源接收数据并将其存储在Spark的内存中以进行处理。
Spark Streaming提供了两类内置的流媒体源。
基本来源:可直接在StreamingContext API中获得的来源。示例: file systems, and socket connections.
高级资源:可以通过额外的实用程序类获得诸如Kafka,Flume,Kinesis等资源。如链接部分所述,它们需要针对额外的依赖项进行链接。
请注意,如果要在流应用程序中并行接收多个数据流,则可以创建多个输入DStream(在“ 性能调整”部分中进一步讨论)。这将创建多个接收器,这些接收器将同时接收多个数据流。但是请注意,Spark工作者/执行程序是一项长期运行的任务,因此它占用了分配给Spark Streaming应用程序的核心之一。因此,重要的是要记住,需要为Spark Streaming应用程序分配足够的内核(或线程,如果在本地运行),以处理接收到的数据以及运行接收器。
1.6.1 file systems
要从与HDFS API兼容的任何文件系统(即HDFS,S3,NFS等)上的文件中读取数据,可以通过创建DStream StreamingContext.fileStream[KeyClass, ValueClass, InputFormatClass]。
文件流不需要运行Receiver,因此无需分配任何内核来接收文件数据。
对于简单的文本文件,最简单的方法是StreamingContext.textFileStream(dataDirectory)。
如何监控目录:
Spark Streaming将监视目录dataDirectory并处理在该目录中创建的所有文件
1 可以监视一个简单目录,例如"hdfs://namenode:8040/logs/"。发现后,将直接处理该路径下的所有文件。
2 甲POSIX glob模式可以被提供,例如 "hdfs://namenode:8040/logs/2017/*"。在此,DStream将包含与模式匹配的目录中的所有文件。也就是说:这是监控目录的模式,而不是目录中的文件的模式(即文件内容的增加,不会有数据的产生)。
3 所有文件都必须使用相同的数据格式。
4 根据文件的修改时间而非创建时间,将其视为时间段的一部分。处理后,在当前窗口中对文件的更改将不会导致重新读取该文件。也就是说:忽略更新。
5 目录下的文件越多,扫描更改所需的时间就越长-即使未修改任何文件。
6 如果使用通配符来标识目录(例如)"hdfs://namenode:8040/logs/2016-*",则重命名整个目录以匹配路径会将目录添加到受监视目录列表中。流中仅包含目录中修改时间在当前窗口内的文件。
7 调用FileSystem.setTimes() 修复时间戳是一种在以后的窗口中拾取文件的方法,即使其内容没有更改。
1.6.2使用对象存储作为数据源
HDFS之类的“完整”文件系统往往会在创建输出流后立即对其文件设置修改时间。当打开文件时,甚至在完全写入数据之前,该文件也可能包含在`DStream`-之后,将忽略同一窗口中对该文件的更新。也就是说:更改可能会丢失,流中会省略数据。
为了确保在窗口中可以接收到更改,请将文件写入一个不受监视的目录,然后在关闭输出流后立即将其重命名为目标目录。如果重命名的文件在创建窗口期间显示在扫描的目标目录中,则将提取新数据。
相反,由于实际复制了数据,因此诸如Amazon S3和Azure存储之类的对象存储通常具有较慢的重命名操作。此外,重命名的对象可能具有`rename()`操作时间作为其修改时间,因此可能不被视为原始创建时间所暗示的窗口部分。
需要对目标对象存储进行仔细的测试,以验证存储的时间戳行为与Spark Streaming期望的一致。直接写入目标目录可能是通过所选对象存储流传输数据的适当策略。
1.6.3自定义接收器
首先从实现Receiver (Scala doc, Java doc)开始。自定义接收方必须通过实现两个方法来扩展此抽象类
onStart():开始接收数据需要做的事情。
onStop():停止接收数据的操作。
双方onStart()并onStop()不能无限期地阻塞。通常,onStart()将启动负责接收数据的线程,并onStop()确保这些线程停止接收数据。接收线程也可以使用isStopped(),一个Receiver方法,以检查他们是否应该停止接收数据。
接收到数据后,可以通过调用将该数据存储在Spark内部store(data),这是Receiver类提供的方法。有多种类型,store()它们可以一次存储记录的接收数据,也可以存储为对象/序列化字节的完整集合。请注意,store()用于实现接收器的风格 会影响其可靠性和容错语义。稍后将对此进行详细讨论。
接收线程中的任何异常都应被捕获并正确处理,以避免接收器出现静默故障。restart(<exception>)将通过异步调用onStop()然后onStart()延迟后调用来重新启动接收器。 stop(<exception>)将呼叫onStop()并终止接收器。此外,reportError(<error>) 无需停止/重新启动接收器即可向驱动程序报告错误消息(在日志和UI中可见)。
以下是一个自定义接收器,它通过套接字接收文本流。它将文本流中以'\ n'分隔的行视为记录,并将其存储在Spark中。如果接收线程在连接或接收时出现任何错误,则重新启动接收器以进行另一次连接尝试。
class CustomReceiver(host: String, port: Int)
extends Receiver[String](StorageLevel.MEMORY_AND_DISK_2) with Logging {
def onStart() {
// Start the thread that receives data over a connection
new Thread("Socket Receiver") {
override def run() { receive() }
}.start()
}
def onStop() {
// There is nothing much to do as the thread calling receive()
// is designed to stop by itself if isStopped() returns false
}
/** Create a socket connection and receive data until receiver is stopped */
private def receive() {
var socket: Socket = null
var userInput: String = null
try {
// Connect to host:port
socket = new Socket(host, port)
// Until stopped or connection broken continue reading
val reader = new BufferedReader(
new InputStreamReader(socket.getInputStream(), StandardCharsets.UTF_8))
userInput = reader.readLine()
while(!isStopped && userInput != null) {
store(userInput)
userInput = reader.readLine()
}
reader.close()
socket.close()
// Restart in an attempt to connect again when server is active again
restart("Trying to connect again")
} catch {
case e: java.net.ConnectException =>
// restart if could not connect to server
restart("Error connecting to " + host + ":" + port, e)
case t: Throwable =>
// restart if there is any other error
restart("Error receiving data", t)
}
}
}
在Spark Streaming应用程序中使用自定义接收器
可以通过使用自定义接收器在Spark Streaming应用程序中使用 streamingContext.receiverStream(<instance of custom receiver>)。这将使用自定义接收器实例接收的数据创建输入DStream,如下所示:
斯卡拉
爪哇
// Assuming ssc is the StreamingContext
val customReceiverStream = ssc.receiverStream(new CustomReceiver(host, port))
val words = customReceiverStream.flatMap(_.split(" "))
...
完整的源代码在示例CustomReceiver.scala中。
如Spark流编程指南中简要讨论的,基于可靠性和容错语义,
有两种接收器。
可靠的接收方——对于允许发送数据被确认的可靠源,可靠的接收方正确地向源确认数据已被接收并可靠地存储在Spark中(即已成功复制)。通常,实现此接收器需要仔细考虑源确认的语义。
不可靠的接收方——不可靠的接收方不向源发送确认。这可以用于不支持确认的源,甚至可以用于不希望或不需要进行复杂确认的可靠源。
要实现可靠的接收器,必须使用store(多记录)来存储数据。这种类型的存储是一个阻塞调用,它只在所有给定的记录都存储在Spark中之后才返回。如果配置的接收器存储级别使用复制(默认启用),则此调用在复制完成后返回。因此,它确保数据被可靠地存储,并且接收者现在可以适当地确认源。这确保了在复制数据的过程中,当接收方发生故障时,不会丢失任何数据。
不可靠的接收方不必实现这些逻辑。它可以简单地从源接收记录,然后使用store(单记录)一次插入一条记录。虽然它没有获得存储(多记录)的可靠性保证,
但它具有以下优点:系统负责将数据分块成适当大小的块(在Spark流编程指南中查找块间隔)。如果指定了速率限制,则系统负责控制接收速率。
由于这两个原因,不可靠的接收器比可靠的接收器更容易实现。下表总结了两种类型的接收器的特点
| 接收器类型 | 特点 |
|---|---|
| 不可靠的接收者 | 易于实现。 系统负责块的生成和速率控制。没有容错保证,会因接收器故障而丢失数据。 |
| 可靠的接收者 | 强大的容错保证,可以确保零数据丢失。 接收器实现要处理的块生成和速率控制。 实现的复杂性取决于源的确认机制。 |
1.6.4RDD排队作为流
为了使用测试数据测试Spark Streaming应用程序,还可以使用,基于RDD队列创建DStream `streamingContext.queueStream(queueOfRDDs)`。推送到队列中的每个RDD将被视为DStream中的一批数据,并像流一样进行处理。
1.7Dstream的转换
| Transformation | Meaning |
|---|---|
| map(func) | 通过将源DStream的每个元素传递给函数func来返回新的DStream 。 |
| flatMap(func) | 与map相似,但是每个输入项可以映射到0个或多个输出项。 |
| filter(func) | 通过仅选择func返回true 的源DStream的记录来返回新的DStream 。 |
| repartition(numPartitions) | 通过创建更多或更少的分区来更改此DStream中的并行度。 |
| union(otherStream) | 返回一个新的DStream,其中包含源DStream和otherDStream中的元素的并 集。 |
| count() | 通过计算源DStream的每个RDD中的元素数,返回一个新的单元素RDD DStream。 |
| reduce(func) | 通过使用函数func(带有两个参数并返回一个)来聚合源DStream的每个RDD中的元素,从而返回一个单元素RDD的新DStream 。该函数应具有关联性和可交换性,以便可以并行计算。 |
| countByValue() | 在类型为K的元素的DStream上调用时,返回一个新的(K,Long)对的DStream,其中每个键的值是其在源DStream的每个RDD中的频率。 |
| reduceByKey(func, [numTasks]) | 在(K,V)对的DStream上调用时,返回一个新的(K,V)对的DStream,其中使用给定的reduce函数聚合每个键的值。**注意:**默认情况下,这使用Spark的默认并行任务数(本地模式为2,而在集群模式下,此数量由config属性确定spark.default.parallelism)进行分组。您可以传递一个可选numTasks参数来设置不同数量的任务。 |
| join(otherStream, [numTasks]) | 当在(K,V)和(K,W)对的两个DStream上调用时,返回一个新的(K,(V,W))对的DStream,其中每个键都有所有元素对。 |
| cogroup(otherStream, [numTasks]) | 在(K,V)和(K,W)对的DStream上调用时,返回一个新的(K,Seq [V],Seq [W])元组的DStream。 |
| transform(func) | 通过对源DStream的每个RDD应用RDD-to-RDD函数来返回新的DStream。这可用于在DStream上执行任意RDD操作。 |
| updateStateByKey(func) | 返回一个新的“状态” DStream,在该DStream中,通过在键的先前状态和键的新值上应用给定函数来更新每个键的状态。这可用于维护每个键的任意状态数据。 |
1.7.1UpdateStageByKey操作
该updateStateByKey操作使您可以保持任意状态,同时不断用新信息更新它。要使用此功能,您将必须执行两个步骤。
定义状态-状态可以是任意数据类型。
定义状态更新功能-使用功能指定如何使用输入流中的先前状态和新值来更新状态。
在每个批次中,Spark都会对所有现有密钥应用状态更新功能,而不管它们是否在批次中具有新数据。如果更新函数返回,None则将删除键值对。
ssc.checkpoint("in\\checkpoint")
//ssc.checkpoint("hdfs://MyDis:9000/spark/checkpoint")
//updateStageBykey算子,从最开始计算,需要checkPoint
operWc.updateStateByKey(
(nowBatch: Seq[Int], history: Option[Int]) => {
Some(nowBatch.sum + history.getOrElse(0))
}).print(100)
1.7.2转换操作
该transform操作(以及类似的变体transformWith)允许将任意RDD-to-RDD功能应用于DStream。它可用于应用DStream API中未公开的任何RDD操作。例如,将数据流中的每个批次与另一个数据集连接在一起的功能未直接在DStream API中公开。但是,您可以轻松地使用transform它。这实现了非常强大的可能性。例如,可以通过将输入数据流与预先计算的垃圾邮件信息(也可能由Spark生成)结合在一起,然后基于该信息进行过滤来进行实时数据清除。
val spamInfoRDD = ssc.sparkContext.newAPIHadoopRDD(...) // RDD containing spam information
val cleanedDStream = wordCounts.transform { rdd =>
rdd.join(spamInfoRDD).filter(...) // join data stream with spam information to do data cleaning
...
}
}
请注意,在每个批处理间隔中都会调用提供的函数。这使您可以执行随时间变化的RDD操作,即可以在批之间更改RDD操作,分区数,广播变量等。
1.7.3window操作
Spark Streaming还提供了窗口计算,可让您在数据的滑动窗口上应用转换。下图说明了此滑动窗口。
火花流
如该图所示,每当窗口滑动在源DSTREAM,落入窗口内的源RDDS被组合及操作以产生RDDS的窗DSTREAM。在这种特定情况下,该操作将应用于数据的最后3个时间单位,并以2个时间单位滑动。这表明任何窗口操作都需要指定两个参数。
窗口长度 - 窗口的持续时间(图中3)。
滑动间隔 -进行窗口操作的间隔(图中为2)。
这两个参数必须是源DStream的批处理间隔的倍数(图中为1)。
让我们用一个例子来说明窗口操作。假设您要扩展 前面的示例,方法是每10秒在数据的最后30秒生成一次字数统计。为此,我们必须在最后30秒的数据reduceByKey上对pairsDStream (word, 1)对应用该操作。这是通过操作完成的reduceByKeyAndWindow。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p3YCVFpI-1577268000222)(D:\新机\千峰笔记\md_png\image-20191213114041812.png)]
// Reduce last 30 seconds of data, every 10 seconds
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
| window(windowLength,slideInterval) | 返回基于源DStream的窗口批处理计算的新DStream。 |
|---|---|
| countByWindow(windowLength,slideInterval) | 返回流中元素的滑动窗口计数。 |
| reduceByWindow(func,windowLength,slideInterval) | 返回一个新的单元素流,该流是通过使用func在滑动间隔内聚合流中的元素而创建的。该函数应该是关联的和可交换的,以便可以并行正确地计算它。 |
| reduceByKeyAndWindow(func,windowLength,slideInterval,[ numTasks ]) | 在(K,V)对的DStream上调用时,返回新的(K,V)对的DStream,其中使用给定的reduce函数func 在滑动窗口中的批处理上聚合每个键的值。**注意:**默认情况下,这使用Spark的默认并行任务数(本地模式为2,而在集群模式下,此数量由config属性确定spark.default.parallelism)进行分组。您可以传递一个可选 numTasks参数来设置不同数量的任务。 |
| reduceByKeyAndWindow(func,invFunc,windowLength, slideInterval,[ numTasks ]) | 上述方法的一种更有效的版本,reduceByKeyAndWindow()其中,使用前一个窗口的减少值递增地计算每个窗口的减少值。这是通过减少进入滑动窗口的新数据并“逆向减少”离开窗口的旧数据来完成的。一个示例是在窗口滑动时“增加”和“减少”键的计数。但是,它仅适用于“可逆归约函数”,即具有对应的“逆归约”函数(作为参数invFunc)的归约函数。像in中一样reduceByKeyAndWindow,reduce任务的数量可以通过可选参数配置。请注意,必须启用检查点才能使用此操作。 |
| countByValueAndWindow(windowLength, slideInterval,[ numTasks ]) | 在(K,V)对的DStream上调用时,返回新的(K,Long)对的DStream,其中每个键的值是其在滑动窗口内的频率。像in中一样 reduceByKeyAndWindow,reduce任务的数量可以通过可选参数配置。 |
1.7.4join操作
最后,值得一提的是,您可以轻松地在Spark Streaming中执行各种类型的join。
1.7.4.1Dstream Dstream join
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)
在此,在每个批处理间隔中,由生成的RDD stream1将与生成的RDD合并在一起stream2。你也可以做leftOuterJoin,rightOuterJoin,fullOuterJoin。此外,在流的窗口上进行连接通常非常有用。这也很容易。
val windowedStream1 = stream1.window(Seconds(20))
val windowedStream2 = stream2.window(Minutes(1))
val joinedStream = windowedStream1.join(windowedStream2)
1.7.4.2流RDD联接
val dataset: RDD[String, String] = ...
val windowedStream = stream.window(Seconds(20))...
val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }
1.8Dstreams的输出操作
输出操作允许将DStream的数据推出到外部系统,例如数据库或文件系统。由于输出操作实际上允许外部系统使用转换后的数据,因此它们会触发所有DStream转换的实际执行(类似于RDD的操作)。当前,定义了以下输出操作:
| 输出操作 | 含义 |
|---|---|
| print() | 在运行流应用程序的驱动程序节点上,打印DStream中每批数据的前十个元素。这对于开发和调试很有用。 Python API在Python API中称为 pprint()。 |
| saveAsTextFiles(prefix, [suffix]) | 将此DStream的内容另存为文本文件。基于产生在每批间隔的文件名的前缀和后缀:“前缀TIME_IN_MS [.suffix]”。 |
| saveAsObjectFiles(prefix, [suffix]) | 将此DStream的内容保存为SequenceFiles序列化Java对象的内容。基于产生在每批间隔的文件名的前缀和 后缀:“前缀TIME_IN_MS [.suffix]”。 Python API这在Python API中不可用。 |
| saveAsHadoopFiles(prefix, [suffix]) | 将此DStream的内容另存为Hadoop文件。基于产生在每批间隔的文件名的前缀和后缀:“前缀TIME_IN_MS [.suffix]”。 Python API这在Python API中不可用。 |
| foreachRDD(func) | 最通用的输出运算符,将函数func应用于从流生成的每个RDD。此功能应将每个RDD中的数据推送到外部系统,例如将RDD保存到文件或通过网络将其写入数据库。请注意,函数func在运行流应用程序的驱动程序进程中执行,并且通常在其中具有RDD操作,这将强制计算流RDD。 |
1.8.1使用foreachRDD的设计模式
dstream.foreachRDD`是一个强大的原语,可以将数据发送到外部系统。但是,重要的是要了解如何正确有效地使用此原语。应避免的一些常见错误如下。
通常,将数据写入外部系统需要创建一个连接对象(例如,到远程服务器的TCP连接),并使用该对象将数据发送到远程系统。为此,开发人员可能会无意间尝试在Spark驱动程序中创建连接对象,然后尝试在Spark worker中使用该对象以将记录保存在RDD中。例如(在Scala中),
dstream.foreachRDD { rdd =>
val connection = createNewConnection() // executed at the driver
rdd.foreach { record =>
connection.send(record) // executed at the worker
}
}
这是不正确的,因为这要求将连接对象序列化并从驱动程序发送给工作程序。这样的连接对象很少能在机器之间转移。此错误可能表现为序列化错误(连接对象不可序列化),初始化错误(连接对象需要在工作程序中初始化)等。正确的解决方案是在工作程序中创建连接对象。
但是,这可能会导致另一个常见错误-为每个记录创建一个新的连接。例如,
dstream.foreachRDD { rdd =>
rdd.foreach { record =>
val connection = createNewConnection()
connection.send(record)
connection.close()
}
}
通常,创建连接对象会浪费时间和资源。因此,为每个记录创建和销毁连接对象会导致不必要的高开销,并且会大大降低系统的整体吞吐量。更好的解决方案是使用 rdd.foreachPartition-创建单个连接对象,并使用该连接在RDD分区中发送所有记录。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
val connection = createNewConnection()
partitionOfRecords.foreach(record => connection.send(record))
connection.close()
}
}
这将分摊许多记录上的连接创建开销。
最后,可以通过在多个RDD /批次之间重用连接对象来进一步优化。与将多个批次的RDD推送到外部系统时可以重用的连接对象相比,它可以维护一个静态的连接对象池,从而进一步减少了开销。
dstream.foreachRDD { rdd =>
rdd.foreachPartition { partitionOfRecords =>
// ConnectionPool is a static, lazily initialized pool of connections
val connection = ConnectionPool.getConnection()
partitionOfRecords.foreach(record => connection.send(record))
ConnectionPool.returnConnection(connection) // return to the pool for future reuse
}
}
请注意,应按需延迟创建池中的连接,如果一段时间不使用,则超时。这样可以保证最有效地将数据发送到外部系统。
其他要记住的要点:
DStream由输出操作延迟执行,就像RDD由RDD操作延迟执行一样。具体来说,DStream输出操作内部的RDD动作会强制处理接收到的数据。因此,如果您的应用程序没有任何输出操作,或者dstream.foreachRDD()内部没有任何RDD操作,就不会执行任何输出操作。系统将仅接收数据并将其丢弃。
默认情况下,输出操作一次执行一次。它们按照在应用程序中定义的顺序执行。
1.9DataFrame和SQL操作
您可以轻松地对流数据使用[DataFrames和SQL]操作。您必须使用StreamingContext使用的SparkContext创建一个SparkSession。此外,还可以在驱动程序失败时重新启动。这是通过创建SparkSession的延迟实例化单例实例来完成的。在下面的示例中显示。它修改了前面的[单词计数示例,]以使用DataFrames和SQL生成单词计数。每个RDD都转换为一个DataFrame,注册为临时表,然后使用SQL查询。
/** DataFrame operations inside your streaming program */
val words: DStream[String] = ...
words.foreachRDD { rdd =>
// Get the singleton instance of SparkSession
val spark = SparkSession.builder.config(rdd.sparkContext.getConf).getOrCreate()
import spark.implicits._
// Convert RDD[String] to DataFrame
val wordsDataFrame = rdd.toDF("word")
// Create a temporary view
wordsDataFrame.createOrReplaceTempView("words")
// Do word count on DataFrame using SQL and print it
val wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word")
wordCountsDataFrame.show()
}
您还可以在来自不同线程的流数据定义的表上运行SQL查询(即与正在运行的StreamingContext异步)。只要确保将StreamingContext设置为记住足够的流数据即可运行查询。否则,不知道任何异步SQL查询的StreamingContext将在查询完成之前删除旧的流数据。例如,如果您要查询最后一批,但是查询可能需要5分钟才能运行,然后调用streamingContext.remember(Minutes(5))(使用Scala或其他语言的等效语言)。
2.0缓存和序列化
与RDD相似,DStreams还允许开发人员将流的数据持久存储在内存中。
也就是说,persist()在DStream上使用该方法将自动将该DStream的每个RDD持久存储在内存中。如果DStream中的数据将被多次计算(例如,对同一数据进行多次操作),这将很有用。
对于和的基于窗口的操作reduceByWindow和 reduceByKeyAndWindow和的基于状态的操作updateStateByKey,这都是隐含的。因此,由基于窗口的操作生成的DStream会自动保存在内存中,而无需开发人员调用persist()。
对于通过网络接收数据的输入流(例如,Kafka,Flume,套接字等),默认的持久性级别设置为将数据复制到两个节点以实现容错。
2.1checkpoint
流式应用程序必须24/7全天候运行,因此必须对与应用程序逻辑无关的故障(例如系统故障,JVM崩溃等)具有弹性。为此,Spark Streaming需要将足够的信息检查点指向容错存储系统,以便可以从故障中恢复。检查点有两种类型的数据。
元数据检查点 -将定义流计算的信息保存到HDFS等容错存储中。这用于从运行流应用程序的驱动程序的节点的故障中恢复(稍后详细讨论)。
元数据包括:
配置——用于创建流应用程序的配置。
DStream操作——定义流应用程序的一组DStream操作。
未完成的批——其作业在队列中但尚未完成的批。
数据检查点:
将生成的RDD保存到可靠的存储中。在某些状态转换中,这是必须的,这些转换将跨多
个批次的数据进行合并。在此类转换中,生成的RDD依赖于先前批次的RDD,这导致依赖项链的长度随时间不断增加。为了避免恢复时间的这种无限制的增加(与依存关系链成比例),有状态转换的中间RDD定期 检查点到可靠的存储(例如HDFS)以切断依存关系链。
总而言之,从驱动程序故障中恢复时,主要需要元数据检查点,而如果使用有状态转换,则即使是基本功能,也需要数据或RDD检查点。
2.1.1何时启用检查点
必须为具有以下任何要求的应用程序启用检查点:
- *有状态转换的用法* -如果在应用程序中使用`updateStateByKey`或`reduceByKeyAndWindow`(带有反函数),则必须提供检查点目录以允许定期进行RDD检查点。
- 从运行应用程序的驱动程序故障中恢复* -元数据检查点用于恢复进度信息。
请注意,没有前述状态转换的简单流应用程序可以在不启用检查点的情况下运行。在这种情况下,从驱动程序故障中恢复也将是部分的(某些丢失但未处理的数据可能会丢失)。这通常是可以接受的,并且许多都以这种方式运行Spark Streaming应用程序。预计将来会改善对非Hadoop环境的支持。
2.1.2如何配置检查点
可以通过在容错,可靠的文件系统(例如,HDFS,S3等)中设置目录来启用检查点,将检查点信息保存到该目录中。这是通过使用完成的streamingContext.checkpoint(checkpointDirectory)。这将允许您使用前面提到的有状态转换。此外,如果要使应用程序从驱动程序故障中恢复,则应重写流应用程序以具有以下行为。
程序首次启动时,它将创建一个新的StreamingContext,设置所有流,然后调用start()。
失败后重新启动程序时,它将根据检查点目录中的检查点数据重新创建StreamingContext。
// Function to create and setup a new StreamingContext
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...) // new context
val lines = ssc.socketTextStream(...) // create DStreams
...
ssc.checkpoint(checkpointDirectory) // set checkpoint directory
ssc
}
// Get StreamingContext from checkpoint data or create a new one
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
// Do additional setup on context that needs to be done,
// irrespective of whether it is being started or restarted
context. ...
// Start the context
context.start()
context.awaitTermination()
如果checkpointDirectory存在,则将根据检查点数据重新创建上下文。如果该目录不存在(即首次运行),则将functionToCreateContext调用该函数以创建新上下文并设置DStreams。请参阅Scala示例 RecoverableNetworkWordCount。本示例将网络数据的字数附加到文件中。
除了使用getOrCreate驱动程序外,还需要确保驱动程序进程在发生故障时自动重新启动。这只能通过用于运行应用程序的部署基础结构来完成。这将在“ 部署”部分中进一步讨论 。
请注意,RDD的检查点会导致保存到可靠存储的成本。这可能会导致RDD被检查点的那些批次的处理时间增加。因此,需要仔细设置检查点的间隔。在小批量(例如1秒)时,每批检查点可能会大大降低操作吞吐量。相反,检查点太少会导致沿袭和任务规模增加,这可能会产生不利影响。对于需要RDD检查点的有状态转换,默认间隔为批处理间隔的倍数,至少应为10秒。可以使用设置 dstream.checkpoint(checkpointInterval)。通常,DStream的5-10个滑动间隔的检查点间隔是一个很好的尝试设置。
recDsteam.checkpoint(Seconds(10))
2.2累加器,广播变量和检查点
无法从Spark Streaming中的检查点恢复累加器和广播变量。如果启用检查点并同时使用“累加器”或“ 广播”变量 ,则必须为“ 累加器”和“ 广播”变量创建延迟实例化的单例实例, 以便在驱动程序发生故障重新启动后可以重新实例化它们。在下面的示例中显示。
object WordBlacklist {
@volatile private var instance: Broadcast[Seq[String]] = null
def getInstance(sc: SparkContext): Broadcast[Seq[String]] = {
if (instance == null) {
synchronized {
if (instance == null) {
val wordBlacklist = Seq("a", "b", "c")
instance = sc.broadcast(wordBlacklist)
}
}
}
instance
}
}
object DroppedWordsCounter {
@volatile private var instance: LongAccumulator = null
def getInstance(sc: SparkContext): LongAccumulator = {
if (instance == null) {
synchronized {
if (instance == null) {
instance = sc.longAccumulator("WordsInBlacklistCounter")
}
}
}
instance
}
}
wordCounts.foreachRDD { (rdd: RDD[(String, Int)], time: Time) =>
// Get or register the blacklist Broadcast
val blacklist = WordBlacklist.getInstance(rdd.sparkContext)
// Get or register the droppedWordsCounter Accumulator
val droppedWordsCounter = DroppedWordsCounter.getInstance(rdd.sparkContext)
// Use blacklist to drop words and use droppedWordsCounter to count them
val counts = rdd.filter { case (word, count) =>
if (blacklist.value.contains(word)) {
droppedWordsCounter.add(count)
false
} else {
true
}
}.collect().mkString("[", ", ", "]")
val output = "Counts at time " + time + " " + counts
})
3.运行部署
3.1jar提交
将应用程序JAR打包 -您必须将流式应用程序编译为JAR。如果spark-submit用于启动应用程序,则无需在JAR中提供Spark和Spark Streaming。但是,如果您的应用程序使用高级资源(例如Kafka,Flume),则必须将它们链接到的额外工件及其依赖项打包在用于部署应用程序的JAR中。例如,使用的应用程序KafkaUtils 必须spark-streaming-kafka-0-10_2.11在其应用程序JAR中包含及其所有传递依赖项。
3.2应用程序驱动程序的自动重新启动
配置应用程序驱动程序的自动重新启动 -若要从驱动程序故障中自动恢复,用于运行流式应用程序的部署基础结构必须监视驱动程序进程,并在驱动程序失败时重新启动。不同的集群管理器 具有不同的工具来实现这一目标。
Spark Standalone-可以提交Spark应用程序驱动程序以在Spark Standalone集群内运行(请参阅 集群部署模式),即,应用程序驱动程序本身在工作程序节点之一上运行。此外,可以指示独立群集管理器监督驱动程序,并在驱动程序由于非零退出代码或由于运行该驱动程序的节点故障而失败时重新启动它。有关更多详细信息,请参见Spark Standalone指南中的集群模式和监督。
YARN -Yarn支持自动重启应用程序的类似机制。
Mesos -已经使用Mesos来实现这一目标。
3.3预写日志
配置预写日志-自Spark 1.2起,我们引入了预*写日志*以实现强大的容错保证。如果启用,则将从接收器接收的所有数据写入配置检查点目录中的预写日志。这样可以防止驱动程序恢复时丢失数据,从而确保零数据丢失(在容错语义部分中进行了详细讨论 )。这可以通过设置来启用
配置参数spark.streaming.receiver.writeAheadLog.enable为true。
但是,这些更强的语义可能会以单个接收器的接收吞吐量为代价。可以通过[并行]运行[更多接收器]来纠正此问题 增加总吞吐量。
此外,由于启用了预写日志,因此建议禁用Spark中接收到的数据的复制,因为该日志已存储在复制的存储系统中。可以通过将输入流的存储级别设置为来完成此操作
StorageLevel.MEMORY_AND_DISK_SER
有关更多详细信息,请参见请注意,启用I/O加密后,Spark不会加密写入预写日志的数据。如果需要对预写日志数据进行加密,则应将其存储在本地支持加密的文件系统中。
3.4最大速率设置
设置最大接收速率 -如果群集资源不足以使流应用程序能够以最快的速度处理数据,则可以通过设置记录/秒的最大速率限制来限制接收器的速率。
spark.streaming.receiver.maxRate
spark.streaming.kafka.maxRatePerPartition
请参阅接收器和 Direct Kafka方法的配置参数 。在Spark 1.5中,我们引入了一个称为背压的功能,该功能消除了设置此速率限制的需要,因为Spark Streaming会自动计算出速率限制,并在处理条件发生变化时动态调整它们。这个背压可以通过设置来启用配置参数来。
spark.streaming.backpressure.enabled true
3.5监控应用
除了Spark的监视功能外,Spark Streaming还具有其他特定功能。使用StreamingContext时, Spark Web UI会显示一个附加Streaming选项卡,其中显示有关正在运行的接收器(接收器是否处于活动状态,接收到的记录数,接收器错误等)和已完成的批处理(批处理时间,排队延迟等)的统计信息。 )。这可用于监视流应用程序的进度。
Web UI中的以下两个指标特别重要:
处理时间 -处理每批数据的时间。
调度延迟 -批处理在队列中等待先前批处理完成的时间。
如果批处理时间始终大于批处理时间间隔和/或排队延迟不断增加,则表明系统无法像生成批处理一样快地处理批处理,并且落后于此。在这种情况下,请考虑 减少批处理时间。
还可以使用StreamingListener界面监视Spark Streaming程序的进度,该界面可让您获取接收器状态和处理时间。请注意,这是一个开发人员API,将来可能会得到改进(即,报告了更多信息)。
3.6性能监控
要在集群上的Spark Streaming应用程序中获得最佳性能,需要进行一些调整。本节说明了可以调整以提高应用程序性能的许多参数和配置。在较高级别上,您需要考虑两件事:
通过有效使用群集资源减少每批数据的处理时间。
设置正确的批处理大小,以便可以在接收到批处理数据后尽快对其进行处理(也就是说,数据处理与数据摄取保持同步)
3.6.1减少批处理时间
3.6.2数据接收中的并行度
通过网络(例如Kafka,Flume,套接字等)接收数据需要对数据进行反序列化并将其存储在Spark中。如果数据接收成为系统的瓶颈,请考虑并行化数据接收。请注意,每个输入DStream都会创建一个接收器(在工作计算机上运行),该接收器接收单个数据流。因此,可以通过创建多个输入DStream并将其配置为从源接收数据流的不同分区来实现接收多个数据流。例如,可以将接收两个主题数据的单个Kafka输入DStream拆分为两个Kafka输入流,每个输入流仅接收一个主题。这将运行两个接收器,从而允许并行接收数据,从而提高了总体吞吐量。这些多个DStream可以结合在一起以创建单个DStream。然后,可以将应用于单个输入DStream的转换应用于统一流。这样做如下。
val numStreams = 5
val kafkaStreams = (1 to numStreams).map { i => KafkaUtils.createStream(...) }
val unifiedStream = streamingContext.union(kafkaStreams)
unifiedStream.print()
创建一个统一的DStream从多个DStreams的相同类型和相同的滑动持续时间。
def union[T: ClassTag](streams: Seq[DStream[T]]): DStream[T] = withScope {
new UnionDStream[T](streams.toArray)
}
应该考虑的另一个参数是接收机的块间隔,该间隔由配置参数确定 spark.streaming.blockInterval。对于大多数接收器,接收到的数据在存储在Spark内存中之前会合并为数据块。每批中的块数确定了将在类似map的转换中用于处理接收到的数据的任务数。每批接收器中每个接收器的任务数大约为(批处理间隔/块间隔)。例如,200 ms的块间隔将每2秒批处理创建10个任务。如果任务数太少(即少于每台计算机的核心数),那么它将效率低下,因为将不使用所有可用的核心来处理数据。要增加给定批处理间隔的任务数,请减小阻止间隔。但是,建议的块间隔最小值约为50毫秒,在此之下,任务启动开销可能是个问题。
使用多个输入流/接收器接收数据的一种替代方法是显式地对输入数据流进行分区(使用inputStream.repartition(<number of partitions>))。在进一步处理之前,这会将接收到的数据批分布在群集中指定数量的计算机上。
3.6.3数据处理中的并行度
如果在计算的任何阶段使用的并行任务数量不够高,则群集资源可能无法得到充分利用。例如,对于像reduceByKey 和这样的分布式归约操作reduceByKeyAndWindow,并行任务的默认数量由spark.default.parallelism configuration属性控制。您可以将并行性级别作为参数传递(请参阅 PairDStreamFunctions 文档),或将spark.default.parallelism 配置属性设置为更改默认值。
4.Spark Streaming + Kafka集成指南
在这只是列出一部分,关于与kafka集成详细信息
Apache Kafka是一种发布-订阅消息传递,被重新认为是一种分布式的,分区的,复制的提交日志服务。在使用Spark开始集成之前,请仔细阅读Kafka文档。
Kafka项目在版本0.8和0.10之间引入了新的使用者API,因此有2个单独的相应Spark Streaming包可用。请为您的经纪人和所需功能选择正确的软件包;请注意,0.8集成与以后的0.9和0.10代理兼容,但0.10集成与早期的代理不兼容。
注意:自Spark 2.3.0起已不再支持Kafka 0.8。
| spark-streaming-kafka-0-8 | spark-streaming-kafka-0-10 | |
|---|---|---|
| 经纪人版本 | 0.8.2.1或更高 | 0.10.0或更高 |
| API成熟度 | 不推荐使用 | 稳定 |
| 语言支援 | Scala,Java,Python | Java Scala |
| 接收器DStream | 是 | 没有 |
| 直接DStream | 是 | 是 |
| SSL / TLS支持 | 没有 | 是 |
| 抵销提交API | 没有 | 是 |
| 动态主题订阅 | 没有 | 是 |
spark整合es写入:
object Save2EsLocalTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("save2eslocal").setMaster("local[*]")
conf.set("spark.streaming.stopGracefullyOnShutdown","true")
conf.set("es.index.auto.create", "false")
conf.set("es.nodes", "127.0.0.1")
conf.set("es.port", "9200")
val sc = new SparkContext(conf)
/*
* es的参数
*
* es.resource.write : index/type
* es.write.operation :
* index 加入新数据
* upsert 数据不存在插入,数据存在更新
*
* es.mapping.id : 将document field 映射为 document id
*
* */
val config = scala.collection.mutable.Map("es.resource.write" -> "test/students","es.mapping.id"->"sid","es.write.operation"->"upsert")
//必须引入
import org.elasticsearch.spark._
val students = sc.makeRDD(Seq(Map("sid"->"7","sname"->"hhy","sage"->100)))
students.saveToEs(config)
sc.stop()
}
}
rue")
conf.set(“es.index.auto.create”, “false”)
conf.set(“es.nodes”, “127.0.0.1”)
conf.set(“es.port”, “9200”)
val sc = new SparkContext(conf)
/*
* es的参数
*
* es.resource.write : index/type
* es.write.operation :
* index 加入新数据
* upsert 数据不存在插入,数据存在更新
*
* es.mapping.id : 将document field 映射为 document id
*
* */
val config = scala.collection.mutable.Map("es.resource.write" -> "test/students","es.mapping.id"->"sid","es.write.operation"->"upsert")
//必须引入
import org.elasticsearch.spark._
val students = sc.makeRDD(Seq(Map("sid"->"7","sname"->"hhy","sage"->100)))
students.saveToEs(config)
sc.stop()
}
}
