目录
FCN-fully convolutional network
一、人脑视觉机理
1981 年的诺贝尔医学奖,颁发给了David Hubel(出生于加拿大的美国神经生物学家)和 TorstenWiesel。这两位的主要贡献是“发现了视觉系统的信息处理”:可视皮层是分级的,如下图所示:
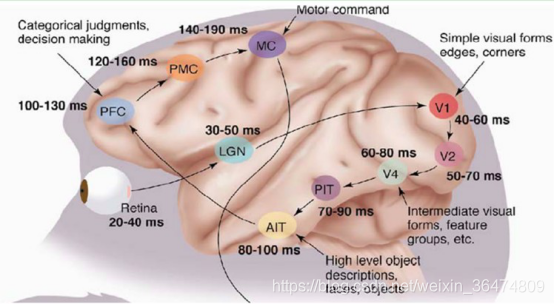
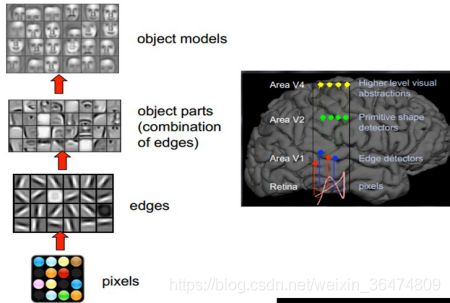
这个生理学的发现,促进了计算机人工智能,在四十年后的突破性发展。总的来说,人的视觉系统的信息处理是分级的。从低级的V1区提取边缘特征,再到V2区的形状或者目标的部分等,再到更高层,整个目标、目标的行为等。高层的特征是低层特征的组合,从低层到高层的特征表示越来越抽象,越来越能表现语义或者意图,深度学习正是借鉴了人脑视觉机理的这一过程,通过逐层的抽象来学习对输入数据的抽象的、高层次的、层级结构的表征。
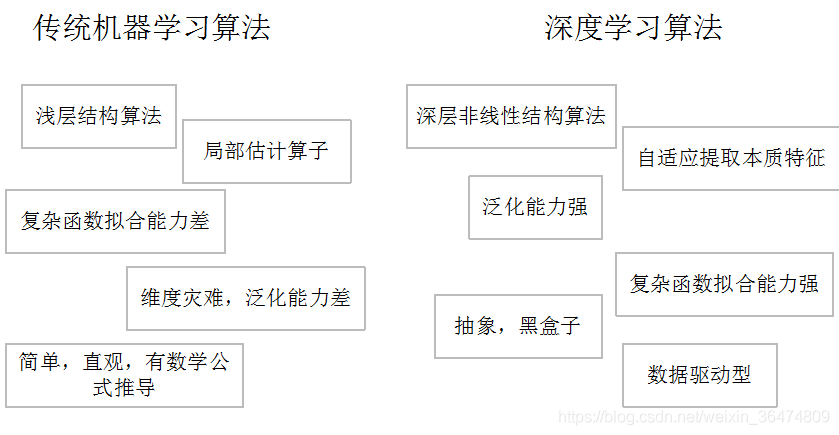
二、深度学习的训练过程
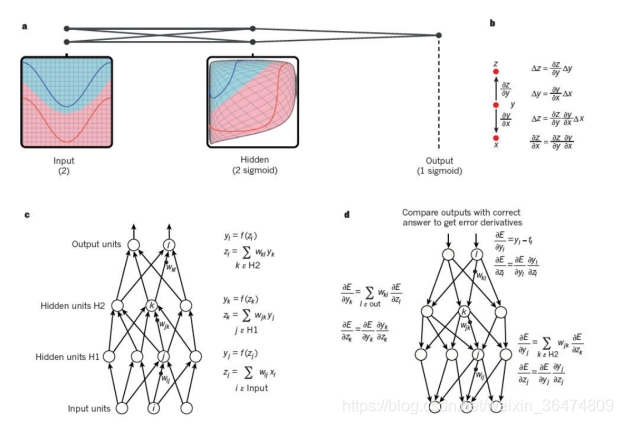
深度学习算法主要采用反向传播算法与梯度下降算法,其训练示意图如下所示
三、卷积神经网络
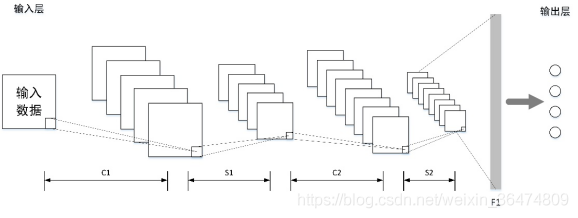
卷积神经网络(convolutional neural network, CNN)是目前深度学习方法中得到普遍运用的一种网络结构,其主要模拟大脑神经元分层处理人眼摄入图片流程。
一个基本的卷积神经网络结构如下图所示,基本的卷积网络主要由卷积层(C标识)和池化层(S标识)交替组合,信息由输入层输入网络后经多层卷积层池化层交替处理,最后使用全连接层(F1标识)提取的特征量作为输出层进行结果计算。
四、主流模型及演进
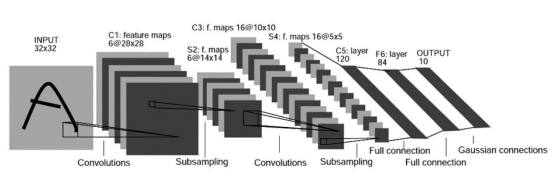
LeNet-5
1998年提出,神经网络的鼻祖,详细解析:
https://cuijiahua.com/blog/2018/01/dl_3.html
见论文: Gradient-Based Learning Applied to Document Recognition,Published in: Proceedings of the IEEE ( Volume: 86 , Issue: 11 , Nov 1998 )
LeNet5 这个网络虽然很小,但是它包含了深度学习的基本模块:卷积层,池化层,全链接层。LeNet-5共有7层,不包含输入,每层都包含可训练参数;每个层有多个Feature Map,每个FeatureMap通过一种卷积滤波器提取输入的一种特征,然后每个FeatureMap有多个神经元。
- LeNet-5是一种用于手写体字符识别的非常高效的卷积神经网络。
- 卷积神经网络能够很好的利用图像的结构信息。
- 卷积层的参数较少,这也是由卷积层的主要特性即局部连接和共享权重所决定。
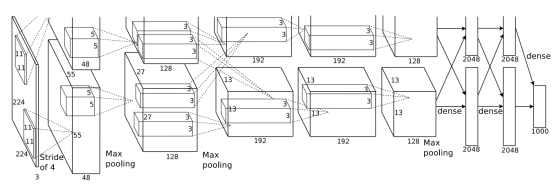
AlexNet
AlexNet是2012年ImageNet竞赛冠军获得者Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,更多的更深的神经网络被提出。自此之后就有了更深的模型。
AlexNet将LeNet的思想发扬光大,把CNN的基本原理应用到了很深很宽的网络中。AlexNet主要使用到的新技术点如下:
(1)成功使用ReLU作为CNN的激活函数,并验证其效果在较深的网络超过了Sigmoid,成功解决了Sigmoid在网络较深时的梯度弥散问题。虽然ReLU激活函数在很久之前就被提出了,但是直到AlexNet的出现才将其发扬光大。
(2)训练时使用Dropout随机忽略一部分神经元,以避免模型过拟合。Dropout虽有单独的论文论述,但是AlexNet将其实用化,通过实践证实了它的效果。在AlexNet中主要是最后几个全连接层使用了Dropout。
(3)在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
(4)提出了LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
(5)使用CUDA加速深度卷积网络的训练,利用GPU强大的并行计算能力,处理神经网络训练时大量的矩阵运算。
(6)数据增强,随机地从256*256的原始图像中截取224*224大小的区域(以及水平翻转的镜像),相当于增加了2*(256-224)^2=2048倍的数据量。
注意,此时还没有batch Norm
GoogLeNet
GoogLeNet是2014年Christian Szegedy提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。
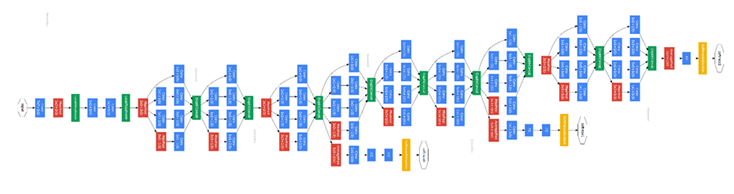
GoogLeNet中的inception
从v1-v4
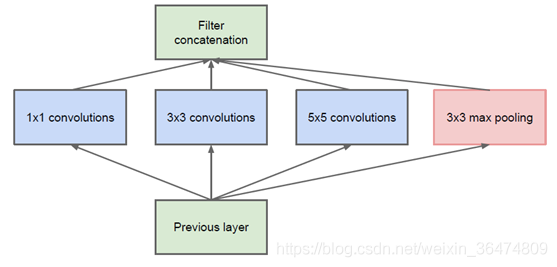
该结构将CNN中常用的卷积(1x1,3x3,5x5)、池化操作(3x3)堆叠在一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。
通过设计一个稀疏网络结构,但是能够产生稠密的数据,既能增加神经网络表现,又能保证计算资源的使用效率。
VGG-Net
VGG模型是2014年ILSVRC竞赛的第二名,第一名是GoogLeNet。
但是VGG模型在多个迁移学习任务中的表现要优于googLeNet。而且,从图像中提取CNN特征,VGG模型是首选算法。它的缺点在于,参数量有140M之多,需要更大的存储空间。但是这个模型很有研究价值。
-
小卷积核。作者将卷积核全部替换为3x3(极少用了1x1);
-
小池化核。相比AlexNet的3x3的池化核,VGG全部为2x2的池化核;
-
层数更深特征图更宽。基于前两点外,由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,计算量的增加放缓;
-
全连接转卷积。网络测试阶段将训练阶段的三个全连接替换为三个卷积,测试重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入。

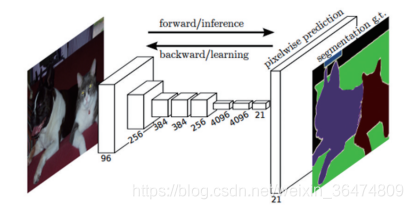
FCN-fully convolutional network
2015Best cvpr
1、之前的分类网络采用全连接的连接,但是全连接会忽视很多位置信息,因此FCN采用了卷积和池化替代全连接,更好的解决稠密问题。
2、FCN连接了不同全局步长的层,增加了一些细节信息。
VGG之后,BatchNorm才被提出。
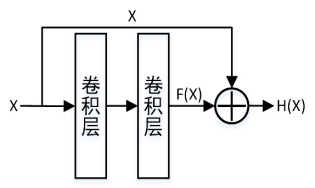
Resnet
https://www.jianshu.com/p/93990a641066
加入残差单元,解决了梯度传导不畅的问题,即Y=f(x)+x
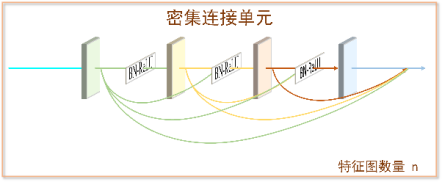
Densenet
相关问题及汇总:
1. BN与alexNet的先后问题
BN的论文中,对比的结构是GoogleNet与Inception,因此BN的出现晚于Alexnet
并且AlexNet是最早的深层网络,而BN正是为了解决深层网络的feature分布问题,因此,BN必然晚于AlexNet。
Alexnet出现于2012年左右,BN出现于2015年。
