之前写了一些字符串相关的题,但由于对正则表达式了解甚少,很多题写起来显得有些“冗余”,便开始学正则表达式了,因此分享下自己的学习心得吧
正则表达式是什么
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。
通俗的讲就是按照某种规则去匹配符合条件的字符串。
首先,我们来看一个简单的例子吧。
如何判断一个字符串是否为合法的手机号,这里只考虑符合规则的手机号,而不考虑空号情况。
合法的手机号有 11 位 0-9 的数字组成,其中必须以 1 开头,第二位为 3 4 5 7 9 其中一个,后 9 位 (0-9) 数字结尾的 11 位字符串。
先考虑不使用正则表达式来解决这个问题。
我们可以先判断这个字符串是否有11位,在11位的基础上,可以再判断11位的字符串是否为由纯数字组成,在这个基础上,判断第一位是否为1,第二位的情况。
示例如下:
#include <bits/stdc++.h>
using namespace std;
bool isAllNum(string str){
for(int i=0;i<str.length();i++){
if(!('0'<=str[i]&&str[i]<='9')){
return false;
}
}
return true;
}
bool isPhoneNum(string str){
//以1开头,第二位为3 4 5 7 9其中一个,以9位(0-9)数字结尾
bool res=false;
if(str.length()!=11){
res=false;
}else{
//纯数字组成
if(isAllNum(str)){
if(str[0]=='1'&&(str[1]=='3'||str[1]=='4'||str[1]=='5'||str[1]=='7'||str[1]=='9')){
res=true;
}
}
}
return res;
}
int main(){
string str;
cin>>str;
cout<<"The answer is "<<isPhoneNum(str)<<endl;
return 0;
}测试:
1008611
The answer is 013553267951
The answer is 1可以看出一个简单的手机号判断还是有一些些步骤的,那对于复杂一点的问题,可能就需要很多的 if else if 了。
接下来我们一点点地介绍正则表达式,本系列内容参考了微信公众号(前端之巅)的推文。
常用元字符
来自百度百科的定义:
正则表达式语言由两种基本字符类型组成:原义(正常)文本字符和元字符。元字符使正则表达式具有处理能力。所谓元字符就是指那些在正则表达式中具有特殊意义的专用字符,可以用来规定其前导字符(即位于元字符前面的字符)在目标对象中的出现模式。
在正则表达式中,常用的元字符及其作用如下表所示
| 元字符 | 解释 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
| \W | 匹配不是字母、数字、下划线的字符 |
| \d | 匹配数字 |
| \D | 匹配不是数字的字符 |
| \s | 匹配任意不可见字符, 包括空格、制表符、换行符等 |
| \S | 匹配任意可见字符 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始位置 |
| $ | 匹配字符串的结束位置 |
有这些常用的元字符,我们可以写一些简单的正则表达式并匹配字符串。
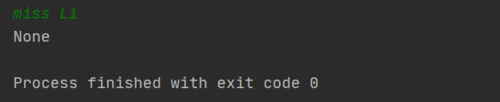
比如,匹配以 Miss 开头的字符串
在 python 中,使用 re 库:
# -*- coding: utf-8 -*-
import re
test_str = input()
# start with "r" means raw string
ptn = r"^Miss"
# ptn = r"Miss"
print(re.search(ptn, test_str))
测试结果:
匹配 10 位的 QQ 账号(也有 8 位的,现在的应该都是 10 位了吧):
^\d\d\d\d\d\d\d\d\d\d$这里稍微注意的地方是,匹配 QQ 账号这里,我们使用了 $ 作为结束,而在之前匹配以 Miss 开头的字符串时没有加 $ ,如果加了,那么只有 Miss 这个字符串才能被正确匹配。
简单匹配手机号(暂时只考虑以 1 开头的 11 位数字):
^1\d\d\d\d\d\d\d\d\d\d$重复限定符
从上面的示例可以看出,元字符很重要,很好用,但重复的情况较多,使用重复限定符就可以更加简介。
| 语法 | 解释 |
|---|---|
| * | 重复零次或多次,即出现任意次 |
| + | 重复一次或更多次,即至少出现一次 |
| ? | 重复零次或一次,不能出现两次以上 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
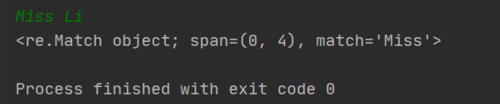
匹配以 Miss 开头的字符串:
^Miss*$和之前的作用一样
匹配 QQ 号:
^\d{10}$d 重复十次
简单匹配手机号(暂时只考虑以 1 开头的 11 位数字):
^1\d{10}$匹配以a开头的,0个或多个b结尾的字符串
^ab*$分组
从重复限定符的例(4)中看到,限定符是作用在与他左边最近的一个字符,那么问题来了,如何限定 ab 呢?
正则表达式中用小括号 () 来做分组,也就是括号中的内容作为一个整体。
因此当我们要匹配多个 ab 时,我们可以这样。
如:匹配字符串中包含 0 到多个 ab 开头:
^(ab)*$转义
有时候在我们查找 . ,或者(,或者一些元字符本身的话,会有一些问题,因为这些元字符已经变成别的意思了,所以我们没有办法指定这些元字符。出现这种情况,我们就得使用 来取消这些字符的特殊意义。
如要匹配以 (ab) 开头:
^(\(ab\))*$条件或
对于一开始的手机号匹配,第二位为3 4 5 7 9 其中一个,这里包含了一些并列的条件,也就是“或”,那么在正则中是如何表示“或”的呢?
正则用符号 | 来表示或,也叫做分支条件,当满足正则里的分支条件的任何一种条件时,都会当成是匹配成功。
那么我们就可以用或条件来处理这个问题:
合法的手机号有 11 位 0-9 的数字组成,其中必须以 1 开头,第二位为 3 4 5 7 9 其中一个,后 9 位 (0-9) 数字结尾的 11 位字符串。
^1(3|4|5|7|9)\d{9}$python 版
# -*- coding: utf-8 -*-
import re
test_str = input()
# start with "r" means raw string
ptn = r"^1(3|4|5|7|9)\d{9}$"
print(re.search(ptn, test_str))效果:


区间
正则提供了一个元字符中括号 [] 来表示区间条件,可以进行简化。
限定 0 到 9 可以写成 [0-9]
限定 a-z 写成 [a-z]
限定 A-Z 写成 [A-Z]
限定某些数字 [135]
手机号问题也可以这样写:
^1[34579]\d{9}$再来看一个例子,判断合法的 ip 地址。
先从简单的入手,考虑由4个三位数组成的话,可以这样写:
^(\d{1,3}\.){3}\d{1,3}$再考虑 ip 地址中每个数字都不能大于255,可以这样写:
^((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)$需要注意的是,IP 地址里的数字可以包含有前导 0 。而这样的地址,上述式子也是可以匹配的。
本节内容就暂告一段落了,之后将继续更新。