使用HTMLTestRunner生成测试报告
HTMLTestRunner是Python标准库的unittest单元测试框架的一个扩展,它生成易于使用的HTML测试报告,HTMLTestRunner是在BSD许可证下发布。
需要下载HTMLTestRunner.py文件:http://tungwaiyip.info/software/HTMLTestRunner.html
将在下载好的HTMLTestRunner.py放到Python的lib目录下
在python2 中,可以将文件直接放到lib下面,直接用cmd中将包引入到python2中
python3的话,引包的时候会报错,因为这个文件是适配python2的,不是完全的适配python3,可以对文件内容进行一些修改,能让它正常运行。
需要更改:
第94行:
import SstringIO 改为 import io
第540行:
self.outputBuffer = StringIO.StringIO() 改为 self.outputBuffer = io.StringIO()
第633行:
print >>sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime) 改为 print (sys.stderr, '\nTime Elapsed: %s' % (self.stopTime-self.startTime))
第646行:
if not rmap.has_key(cls): 改为 if not cls in rmap:
第771行:
uo = o.decode('latin-1') 改为 uo=e
第778行:
ue = e.decode('latin-1') 改为 ue=e
引入成功会什么都不显示。如下图:
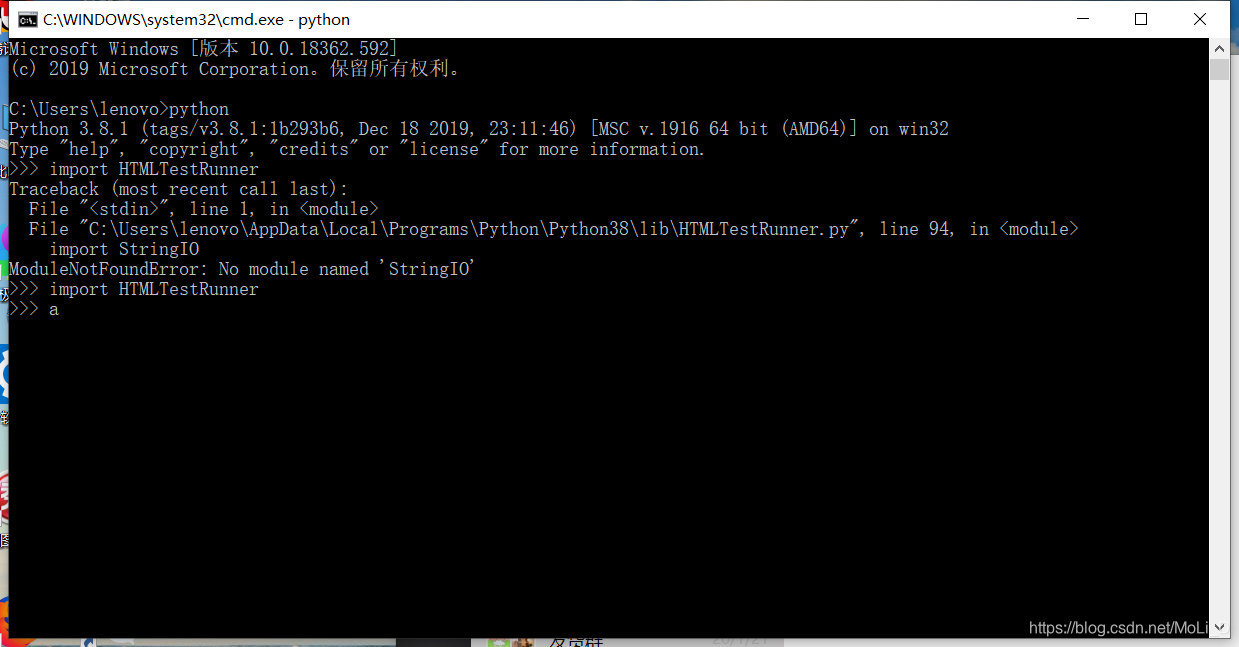
使用方法
写一个测试百度的test:
#测试加法功能测试用例
from selenium import webdriver
import unittest,time,re
from HTMLTestRunner import HTMLTestRunner
class BaiduIde(unittest.TestCase):
def setUp(self):
self.driver= webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url="https://www.baidu.com"
self.verificationErrors = []
def tearDown(self):
self.driver.quit()
self.assertEqual([],self.verificationErrors)
def test_baidu_ide(self):
driver = self.driver
driver.get(self.base_url+'/')
driver.find_element_by_id("kw").send_keys("selenium ide")
driver.find_element_by_id("su").click()
time.sleep(3)
try:
self.assertEqual("selenium ide_百度搜索",driver.title)
except AssertionError as e:
self.verificationErrors.append(str(e))
if __name__ == '__main__':
# 构造测试集
suite = unittest.TestSuite()
suite.addTest(BaiduIde("test_baidu_ide"))
fp =open("./report.html","wb")
runner = HTMLTestRunner(stream=fp,title='百度搜索测试报告',description='用例执行情况:')
runner.run(suite)
如果发现运行,没有什么错误,但是没有生成HTML文件,解决方法如下:
从昨天到今天一直写的都是unittest测试脚本,所以在pycharm中运行测试用例的时候,默认在unittest框架下运行,所以就没有生成HTML文件,也不支持新建一个HTML文件出来。
所已在运行的时候,选择pycharm工具栏的右上角单机下拉按钮,记住不要在工作区域单机右键运行,因为这样还是按unittest框架运行的,如图所示:

单击编辑后,如图所示:

将第一个unittest文件删除,就是你自己运行的unittest文件删除,然后重新添加你想要运行的python文件,如图所示:

选择需要运行的python脚本:

然后再单击运行按钮,HTML的文件就生成了:

打开后显示:

生成的这个表其实不易于阅读,这里显示的都是类名或者用例名,但是我们一般定义类名或者用例名都是以英文开头,自己写的能看懂,但是别人看的话,就完全看不懂了,所以这里就牵扯python内部类和方法的注释。
在类或者方法下面以三个双引号/单引号开头,以三个双引号/单引号结尾的注释是内部注释,可以通过help方法能看到内部注释:

python代码:
#测试加法功能测试用例
from selenium import webdriver
import unittest,time,re
from HTMLTestRunner import HTMLTestRunner
class BaiduIde(unittest.TestCase):
'''百度测试类'''
def setUp(self):
self.driver= webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url="https://www.baidu.com"
self.verificationErrors = []
def tearDown(self):
self.driver.quit()
self.assertEqual([],self.verificationErrors)
def test_baidu_ide(self):
'''搜索关键字,selenium ide'''
driver = self.driver
driver.get(self.base_url+'/')
driver.find_element_by_id("kw").send_keys("selenium ide")
driver.find_element_by_id("su").click()
time.sleep(3)
try:
self.assertEqual("selenium ide_百度搜索",driver.title)
except AssertionError as e:
self.verificationErrors.append(str(e))
if __name__ == '__main__':
# 构造测试集
suite = unittest.TestSuite()
suite.addTest(BaiduIde("test_baidu_ide"))
fp =open("./report.html","wb")
runner = HTMLTestRunner(stream=fp,title='百度搜索测试报告',description='用例执行情况:')
runner.run(suite)
运行结果后,HTML文件显示:

这样就更方便于阅读
测试用例的名称
以上例子中,HTML文件的名称是固定死的,如果测试用例好几次执行,每次都要重新修改文件名,不改的话,就会被覆盖掉。如果想做一个定时任务,一次性运行好几次,生成的报告肯定也是不同的。想要不同的话,可以给报告一个时间,按时间生成报告,这时就用到了python中的time中的time()方法

以上这种取的时间不规范,也不容易看懂,所以可以取time中的其他方法
time.time() 获取当前时间戳
time.ctime() 当前时间的字符形式
time.localtime() 当前时间的struct_time形式
time.strftime() 这个方法需要入参:time.strftime("%Y_%m_%d_%H_%M_%s")
年月日时分秒
经过测试写法应该是:
同样是年份
%y 18
%Y 2018
同样是月份
%m 08
%M 47 会返回现在是本世纪第多少个月
同样是天数
%d 07
%D 08/07/18 会返回斜杠划开的年月日
时分秒:
%H:%M:%S 23:48:56 可以正常显示
%h:%m:%s 会直接报错,应该是小写m会和前边表示月份的m相冲突
应该改为("%Y-%m-%d %H:%M:%S")
但是,取时间为文件名时,不能这么写,必须用下划线:
#测试加法功能测试用例
from selenium import webdriver
import unittest,time,re
from HTMLTestRunner import HTMLTestRunner
class BaiduIde(unittest.TestCase):
'''百度测试类'''
def setUp(self):
self.driver= webdriver.Firefox()
self.driver.implicitly_wait(30)
self.base_url="https://www.baidu.com"
self.verificationErrors = []
def tearDown(self):
self.driver.quit()
self.assertEqual([],self.verificationErrors)
def test_baidu_ide(self):
'''搜索关键字,selenium ide'''
driver = self.driver
driver.get(self.base_url+'/')
driver.find_element_by_id("kw").send_keys("selenium ide")
driver.find_element_by_id("su").click()
time.sleep(3)
try:
self.assertEqual("selenium ide_百度搜索",driver.title)
except AssertionError as e:
self.verificationErrors.append(str(e))
if __name__ == '__main__':
# 构造测试集
suite = unittest.TestSuite()
suite.addTest(BaiduIde("test_baidu_ide"))
now_time=time.strftime("%Y-%m-%d_%H_%M_%S")
filename = './report'+now_time+'.html '
fp =open(filename,"wb")
runner = HTMLTestRunner(stream=fp,title='百度搜索测试报告',description='用例执行情况:')
runner.run(suite)
fp.close()

