Oracle 分区表和普通表查询效率分析对比
目录
测试环境
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Production
在cmd中使用sqlplus进行测试
--cmd中sqlplus登录
示例:c:\>sqlplus user/pwd@oracleNetServiceName
--sqlplus中开启autotrace
set autotrace on;
--sqlplus中进行trace时只显示统计信息不显示查询结果
set autotrace traceonly;
--sqlplus中显示sql执行时间
set timing on;测试表说明:
t_mass表:无分区、无索引
t_mass_hash:有哈希分区、无索引
t_mass_ind:无分区、有索引(索引在id列上)
t_mass_hash_ind:有哈希分区、并有索引(索引在id列上)
创建普通的表(使用toad的generate data生成一千万条记录)
--创建表 无分区
create table t_mass
(id int,
name varchar2(100)
);关于生成一千万条记录的方式,这里推荐使用sqlplus,估计效率更高。
本人在下午下班前使用toad的generate data功能,让其自己运行来生成一千万条记录,具体耗时未知,但用toad会远大于一小时。
创建表并以哈希方式分区
--创建表哈希分区 不拷贝数据
create table t_mass_hash
(id int,
name varchar2(100)
)
partition by hash(id) partitions 16;这里使用hash分区,指定了16个分区.
创建分区表的同时导入海量数据
--创建表 哈希分区 并且在创建表时拷贝千万级数据,注意create 列不能指定类型
create table t_mass_hash
(id,
name)
partition by hash(id) partitions 16
as (select id,name from t_mass);
--千万级数据耗时 Elapsed: 00:00:36.43注意上述sql的语法,不同与不同的create table,这里的id和name都没有指定类型,都是根据t_mass表的列来创建指定的。
小插曲-表空间扩容
原先创建表空间时指定了datafile最大2048M
原先建立表空间的sql:
--1.创建临时表空间
create Temporary Tablespace MASS_TEMP
TempFile 'D:\oracle\product\10.2.0\oradata\orcl\MASS_TEMP_0.dbf'--不同操作系统上此路径应该按实际情况设置,但文件名可以不变
size 64M --大小
autoextend on --自动扩展磁盘空间
next 16M maxsize 2048M --步进 及 最大容量
extent management local;
--2.创建永久表空间
create Tablespace MASS_DATA
logging
datafile 'D:\oracle\product\10.2.0\oradata\orcl\MASS_DATA_0.dbf'
size 64M
autoextend on
next 16M maxsize 2048M
extent management local;结果在拷贝数据中途爆掉了
sqlplus提示:
ORA-01652: unable to extend temp segment by 1024 in tablespace MASS_DATA查看表空间最大是2048M,果断增加一个datafile并设置新的datafile为无限制(实际有限制,最大单个文件32GB)
alter Tablespace MASS_DATA
add datafile 'D:\oracle\product\10.2.0\oradata\orcl\MASS_DATA_1.dbf'
size 64M
autoextend on
next 16M maxsize unlimited;分区表上先建立表结构并导入数据然后建立索引
--创建表无分区 在创建时拷贝数据 --耗时Elapsed: 00:00:19.57
create table t_mass_ind
(id,
name)
as (select id,name from t_mass);
--创建表后建立索引,--千万条数据耗时Elapsed: 00:00:52.42
create index ind_t_mass_ind on t_mass_ind(id);
--这里注意,当表上无分区时,此sql语句后不能加local
--创建表 哈希分区16个 在创建时拷贝数据 --耗时Elapsed: Elapsed: 00:00:26.76
create table t_mass_hash_ind
(id,name)
partition by hash(id) partitions 16
as (select id,name from t_mass);
--创建表后建立索引,--千万条数据耗时Elapsed: 00:00:36.78
create index ind_t_mass_hash_ind on t_mass_hash_ind(id) local;
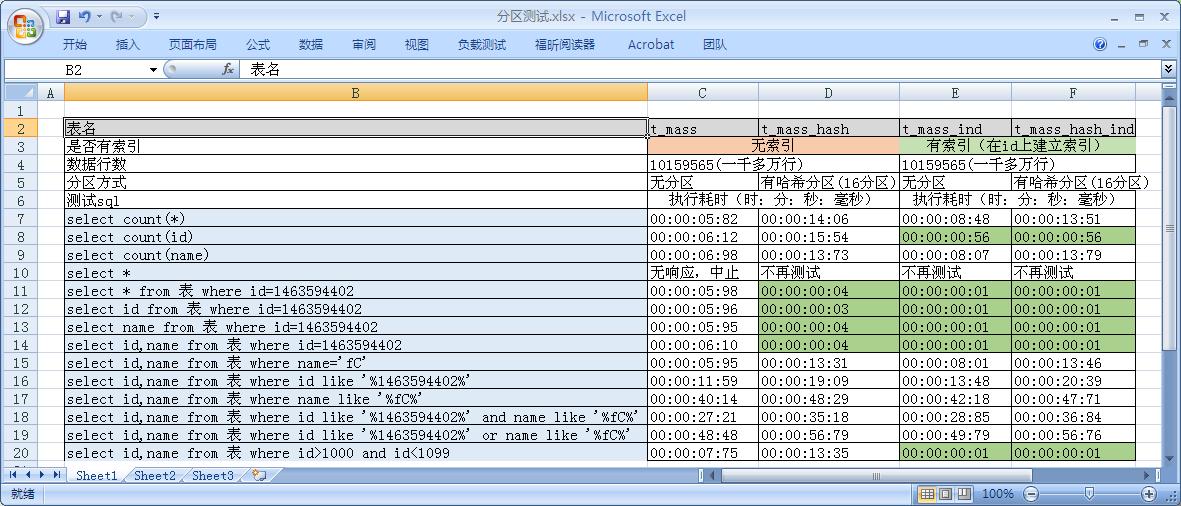
--这里注意,当表上无分区时,此sql语句后不能加local测试结果
扫描二维码关注公众号,回复:
9377007 查看本文章

测试结论
分区有范围分区、哈希分区、列表分区、组合分区等。大数据情况下用分区表是好,但不是绝对的,要结合你具体的应用场景,并且索引也非常关键,有无索引对查询效率影响是天壤之别。
本文章是阅读《让oracle跑的更快2》书籍后的测试文件,这里感谢书籍作者!
