学习C语言是了解内存布局的最简单、最直接、最有效的途径, 它比任何一门高级编程语言都贴近内存。以前学习C语言内存也有一段时间,却也是零零散散,于是打算写一篇博客,整理一下关于内存的内容。
内存优化小结:
计算机内存是以字节(Byte)为单位划分的,理论上CPU可以访问任意编号的字节,但是由于内存对齐(编译器的优化),情况就有所不同;
CPU 通过地址总线来访问内存,一次能处理几个字节的数据,就命令地址总线读取几个字节的数据。32 位的 CPU 一次可以处理4个字节的数据,那么每次就从内存读取4个字节的数据,这就是意味着CPU读取的内存单元的标号一定是4的倍数;对于程序来说,一个变量最好位于一个寻址步长的范围内,这样一次就可以读取到变量的值;如果跨步长存储,就需要读取两次,然后再拼接数据,效率显然降低了。
例如一个 int 类型的数据,如果地址为 8,那么很好办,对编号为 8 的内存寻址一次就可以。如果编号为 10,就比较麻烦,CPU需要先对编号为 8 的内存寻址,读取4个字节,得到该数据的前半部分,然后再对编号为 12 的内存寻址,读取4个字节,得到该数据的后半部分,再将这两部分拼接起来,才能取得数据的值。
64位的处理器也是这个道理,同样的分析。
虚拟地址小结:
虚拟地址在寄存器层面是段地址+偏移地址,这两个地址通过内部总线传输到CPU的内部结构——地址加法器转换才能对应到物理地址,而且每次程序运行时,操作系统都会重新安排虚拟地址和物理地址的对应关系,哪一段物理内存空闲就使用哪一段。
把程序给出的地址看做是一种虚拟地址 ,然后通过某些映射的方法,将这个虚拟地址转换成实际的物理地址。这样,只要我们能够妥善地控制这个虚拟地址到物理地址的映射过程,就可以保证程序每次运行时都可以使用相同的地址。
优点:
1.不同程序的地址空间相互隔离:如果所有程序都直接使用物理内存,那么程序所使用的地址空间不是相互隔离的。恶意程序可以很容易改写其他程序的内存数据,以达到破坏的目的;有些非恶意、但是有 Bug 的程序也可能会不小心修改其他程序的数据,导致其他程序崩溃。使用了虚拟地址后,程序A和程序B虽然都可以访问同一个地址,但它们对应的物理地址是不同的,无论如何操作,都不会修改对方的内存。
2.提高内存使用效率:使用虚拟地址后,操作系统会更多地介入到内存管理工作中,这使得控制内存权限成为可能。例如,我们希望保存数据的内存没有执行权限,保存代码的内存没有修改权限,操作系统占用的内存普通程序没有读取权限等。
CPU数据总线、地址总线和主频小结:
数据总线决定了CPU单次的数据处理能力,主频决定了CPU单位时间内的数据处理次数,它们的乘积就是CPU单位时间内的数据处理量。
数据总线代表CPU可以一次性的传递的数据的位数;
而地址总线代表了CPU的寻址能力,什么是寻址能力呢,通俗的理解即为CPU寻找到的内存单元编号的最大值,有n根地址总线,就能寻到2^n个地址单元,由于八个地址单元为一个字节单位(B),故寻址能力为上述地址的单元数目除八,单位为B;
我们常常听说,CPU主频在计算机的发展过程中飞速提升,从最初的几十 KHz,到后来的几百 MHz,再到现在的 4GHz,终于因为硅晶体的物理特性很难再提升,只能向多核方向发展。在这个过程中,CPU的数据总线宽度也在成倍增长,从早期的8位、16位,到后来的32位,现在我们计算机大部分都在使用64位CPU。
需要注意的是,数据总线和地址总线不是一回事,数据总线用于在CPU和内存之间传输数据,地址总线用于在内存上定位数据,它们之间没有必然的联系,宽度并不一定相等。实际情况是,地址总线的宽度往往随着数据总线的宽度而增长,以访问更大的内存。
- 16位CPU代表数据总线有16根,地址总线有20根
学过汇编的同学应该知道,典型的16位处理器是 Intel 8086,它的数据总线有16根,地址总线有20根,寻址能力为 2^20 = 1MB。 - 32位CPU
随着计算机产业的进步,出现了32位的CPU,一次能处理 32Bit的数据,寻址能力为4GB。这个时候就提出了虚拟地址的概念,并被应用到CPU和操作系统中,这使得程序编写更加容易,运行更加安全。 - 64位CPU
现代计算机都使用64位的CPU,它们一次能处理64Bit 的数据。典型的64位处理器是 Intel 的 Core i3、i5、i7 等,它们的地址总线宽度为 40~50 位左右。64位CPU的出现使个人电脑再次发生了质的飞跃。
编译模式小结(共分为两种编译模式):
32位编译模式
在32位模式下,一个指针或地址占用4个字节的内存,共有32位,理论上能够访问的虚拟内存空间大小为 2^32B,即4GB,有效虚拟地址范围是 0 ~ 0XFFFFFFFF。
也就是说,**对于32位的编译模式,不管实际物理内存有多大,程序能够访问的有效虚拟地址空间的范围就是0 ~ 0XFFFFFFFF,也即虚拟地址空间的大小是 4GB。换句话说,程序能够使用的最大内存为 4GB,只和指针所占位数有关,跟物理内存没有关系。**看到这你也应该很清C语言是了解内存布局的最简单、最直接、最有效的途径, 它比任何一门编程语言都贴近内存的意思了趴。
如果程序需要的内存大于物理内存,或者内存中剩余的空间不足以容纳当前程序,那么操作系统会将内存中暂时用不到的一部分数据写入到磁盘,等需要的时候再读取回来。而我们的程序只管使用 4GB 的内存,不用关心硬件资源够不够,因为这是操作系统的烂摊子,不关咱的事。
当然你可能会想到那物理内存过大了呢?实际上如果物理内存大于 4GB,例如目前很多PC机都配备了8GB的内存,那么程序也无能为力,它只能够使用其中的 4GB。
这是多么的让人憋屈!
64位编译模式
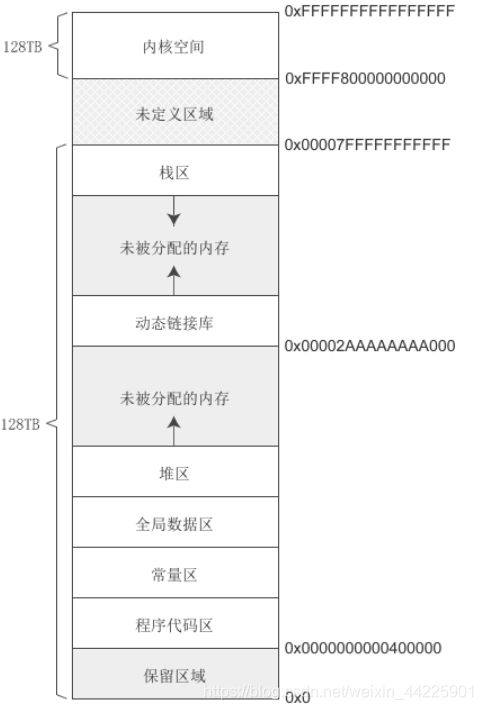
在64位编译模式下,一个指针或地址占用8个字节的内存,共有64位,理论上能够访问的虚拟内存空间大小为 2^64。这是一个很大的值,几乎是无限的,就目前的技术来讲,不但物理内存不可能达到这么大,CPU的寻址能力也没有这么大,实现64位长的虚拟地址只会增加系统的复杂度和地址转换的成本,带不来任何好处,所以 Windows 和 Linux 都对虚拟地址进行了限制,仅使用虚拟地址的低48位(6个字节),总的虚拟地址空间大小为 2^48 = 256TB。
C语言在Linux和Windows环境下的内存模型小结:
程序内存在地址空间中的分布情况称为内存模型。内存模型由操作系统构建,在Linux和Windows下有所差异,并且会受到编译模式的影响。
对于32位环境,理论上程序可以拥有 4GB 的虚拟地址空间,我们在C语言中使用到的变量、函数、字符串等都会对应内存中的一块区域。
但是,在这 4GB 的地址空间中,要拿出一部分给操作系统内核使用,应用程序无法直接访问这一段内存,这一部分内存地址被称为内核空间(Kernel Space)。
Windows 在默认情况下会将高地址的 2GB 空间分配给内核(也可以配置为1GB),而 Linux 默认情况下会将高地址的 1GB 空间分配给内核。也就是说,应用程序只能使用剩下的 2GB 或 3GB 的地址空间,称为用户空间(User Space)。
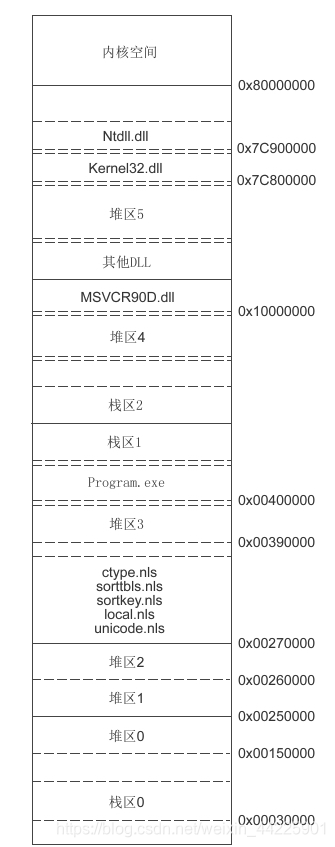
下面附上用户空间C程序的内存布局,以供参考:
32位Linux:

64位Linux:
32位Windows: