题目
One way that the police finds the head of a gang is to check people’s phone calls. If there is a phone call between A and B, we say that A and B is related. The weight of a relation is defined to be the total time length of all the phone calls made between the two persons. A “Gang” is a cluster of more than 2 persons who are related to each other with total relation weight being greater than a given threshold K. In each gang, the one with maximum total weight is the head. Now given a list of phone calls, you are supposed to find the gangs and the heads.
Input Specification:
Each input file contains one test case. For each case, the first line contains two positive numbers N and K (both less than or equal to 1000), the number of phone calls and the weight threthold, respectively. Then N lines follow, each in the following format:
Name1 Name2 Time
where Name1 and Name2 are the names of people at the two ends of the call, and Time is the length of the call. A name is a string of three capital letters chosen from A-Z. A time length is a positive integer which is no more than 1000 minutes.
Output Specification:
For each test case, first print in a line the total number of gangs. Then for each gang, print in a line the name of the head and the total number of the members. It is guaranteed that the head is unique for each gang. The output must be sorted according to the alphabetical order of the names of the heads.
Sample Input 1:
8 59
AAA BBB 10
BBB AAA 20
AAA CCC 40
DDD EEE 5
EEE DDD 70
FFF GGG 30
GGG HHH 20
HHH FFF 10
Sample Output 1:
2
AAA 3
GGG 3
Sample Input 2:
8 70
AAA BBB 10
BBB AAA 20
AAA CCC 40
DDD EEE 5
EEE DDD 70
FFF GGG 30
GGG HHH 20
HHH FFF 10
Sample Output 2:
0
题目分析
A和B有电话记录即为有关联,A和B的关系权重为所有AB相互通话记录(A->B,B->A)的总时长,多个有关联的人员组成一个组,组的权重为所有人员关系权重和
判断一个组是否是犯罪团伙的标准:人数大于2,权重大于已知阈值k;判断一个犯罪团伙的头目标准:点权最大(点权等于所有关联权重和)
题目翻译:已知一个图,求所有连通分量的边权和awt,总人数anum,最大点权wt。判断边权和>k,并且总人数anum>2的连通分量
解题思路
1 存储节点名称,点权,边权
- 需要将顶点字符串名称转换为整数,方便操作,使用map<string,int> si存储<名称,id>,使用map<int,string> is存储<id,名称>
- 点权存储,使用整型数组int wt[maxn]存储
- 边权存储,使用二维矩阵int g[maxn][maxn]存储
注意点:题目已知通话记录为n,若每个通话记录的A,B都不同,最多有2n个名称(即2n个顶点),所以maxn=2*n
2 寻找连通分量,并统计各个连通分量的总边权,总人数,最大点权
思路 01:深度优先遍历DFS
思路 02:广度优先遍历BFS
思路 03:并查集
问题 01:若连通分量中有环,BFS和DFS过程中累加边权时,可能会重复记录
并查集-解决方案 01:并查集过程中不做任何处理,最后比较判断时,将阈值2,若连通分量的总边权>2阈值即为犯罪团伙
DFS/BFS-解决方案 01:访问完A点累计AC边权后,将AC边权g[A][C]和CA边权g[C][A]都置为0,再次访问到CA时不再累加
DFS/BFS-解决方案 02:使用二维矩阵int evis[maxn][maxn]记录每条边的访问情况,初始为0,访问后置为1
如图1所示,A->B->C,访问A时累加了A与C边权,访问C时累加了A与C边权
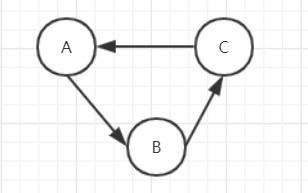
问题 02:各个连通分量的总边权,总人数,最大点权如何记录?
DFS/BFS-解决方案 01:定义三个整型变量,记录每个连通分量总边权,最大点权对应id,连通分量总人数
并查集-解决方案 01:使用三个整型数组,数组的下标对应顶点id,并查集处理时,将总边权和最大点权和集合人数统计到根节点id对应的下标处
并查集-解决方案 02:定义连通分量结构体数组node gang[maxn](下标对应顶点id),结构体中定义总边权,最大点权对应id,连通分量总人数。并查集处理时,将总边权和最大点权和集合人数统计到根节点id对应的下标处
易错点
- 最终打印的多个连通分量,需要按照最大点权对应的顶点名称的字典序排序(测试点2,5)
Code
Code 01(DFS)
#include <iostream>
#include <map>
using namespace std;
const int maxn = 2010;
map<string,int> si;
map<int,string> is;
map<string,int> ans;
int id,k,wt[maxn],g[maxn][maxn],vis[maxn];//wt点权,g边权
int sti(string s) {
if(si[s]==0) {
si[s]=++id; //从1开始
is[id]=s;
}
return si[s];
}
void dfs(int i,int &head,int &num,int &tv) {
num++;
vis[i]=true;
if(wt[i]>wt[head])head=i;
for(int j=1; j<=id; j++) {
if(g[i][j]==0)continue;
tv+=g[i][j];
g[i][j]=g[j][i]=0;
if(vis[j]==false)
dfs(j,head,num,tv);
}
}
void dfs_travel() {
for(int i=1; i<=id; i++) {
if(vis[i]==true)continue;
int head=i,num=0,tv=0;
dfs(i,head,num,tv);
if(num>2&&tv>k)ans[is[head]]=num;
}
}
int main(int argc,char * argv[]) {
int n,w;
string s1,s2;
scanf("%d %d",&n,&k);
for(int i=0; i<n; i++) {
cin>>s1>>s2>>w;
int id1=sti(s1);
int id2=sti(s2);
wt[id1]+=w;
wt[id2]+=w;
g[id1][id2]+=w;
g[id2][id1]+=w;
}
dfs_travel(); //深度优先遍历
printf("%d\n",ans.size());
for(auto it=ans.begin();it!=ans.end();it++){
printf("%s %d\n",it->first.c_str(),it->second);
}
return 0;
}Code 02(BFS)
#include <iostream>
#include <map>
#include <queue>
const int maxn=2010;
using namespace std;
map<string,int> si;
map<int,string> is;
map<string,int> ans;
int id,k,wt[maxn],g[maxn][maxn],vis[maxn],evis[maxn][maxn];//wt点权,g边权
int sti(string s) {
if(si[s]==0) {
si[s]=++id; //从1开始
is[id]=s;
}
return si[s];
}
void bfs(int now, int &head, int &num, int &tv) {
queue<int> q;
q.push(now);
vis[now]=true;
while(!q.empty()) {
int i = q.front();
q.pop();
num++;
if(wt[i]>wt[head])head=i;
for(int j=1; j<=id; j++) {
if(evis[i][j]==1||g[i][j]==0)continue;
tv+=g[i][j];
evis[i][j]=evis[j][i]=1;
if(vis[j]==false) {
q.push(j);
vis[j]=true;
}
}
}
}
void bfs_travel() {
for(int i=1; i<=id; i++) {
if(vis[i]==true)continue;
int head=i,num=0,tv=0;
bfs(i,head,num,tv);
if(num>2&&tv>k)ans[is[head]]=num;
}
}
int main(int argc,char * argv[]) {
int n,w;
string s1,s2;
scanf("%d %d",&n,&k);
for(int i=0; i<n; i++) {
cin>>s1>>s2>>w;
int id1=sti(s1);
int id2=sti(s2);
wt[id1]+=w;
wt[id2]+=w;
g[id1][id2]+=w;
g[id2][id1]+=w;
}
bfs_travel(); //深度优先遍历
printf("%d\n",ans.size());
for(auto it=ans.begin(); it!=ans.end(); it++) {
printf("%s %d\n",it->first.c_str(),it->second);
}
return 0;
}Code 03(并查集 结构体记录连通分量属性)
#include <iostream>
#include <vector>
#include <map>
#include <algorithm>
using namespace std;
const int maxn=2010;
map<string,int> si;
map<int,string> is;
int id=1,k,father[maxn],wt[maxn];//wt点权,g边权
struct node { //定义每个连通块的属性
int anum,awt,head; //总人数,总权重,队首整数编号
} gang[maxn];
int sti(string s) {
if(si[s]==0) {
si[s]=id; //从1开始
is[id]=s;
id++;
}
return si[s];
}
/* 并查集 初始化 */
void init() {
for(int i=0; i<maxn; i++) father[i]=i;
}
/* 并查集 查 */
int find(int x) {
int a = x;
while(x!=father[x])
x=father[x];
while(a!=father[a]) {
int temp=a;
a=father[a];
father[temp]=x;
}
return x;
}
/* 并查集 并 */
void Union(int a, int b) {
int x = find(a);
int y = find(b);
if(x<=y)father[y]=x;
else father[x]=y;
}
bool cmp(node &n1,node &n2){
return is[n1.head]<is[n2.head];
}
int main(int argc,char * argv[]) {
init();
int n,w;
string s1,s2;
scanf("%d %d",&n,&k);
for(int i=0; i<n; i++) {
cin>>s1>>s2>>w;
int id1=sti(s1);
int id2=sti(s2);
Union(id1,id2);
wt[id1]+=w;
wt[id2]+=w;
}
for(int i=1; i<id; i++) {
int r = find(i);
gang[r].anum++; //人数增加1
gang[r].awt += wt[i]; //总权重增加
if(wt[gang[r].head]<wt[i]) {
gang[r].head=i;
}
}
sort(gang+1,gang+id,cmp);
vector<int> v;
for(int i=1; i<=id; i++) {
if(gang[i].awt>2*k&&gang[i].anum>2)v.push_back(i);
}
printf("%d\n",v.size());
for(int i=0; i<v.size(); i++) {
printf("%s %d\n",is[gang[v[i]].head].c_str(),gang[v[i]].anum);
}
return 0;
}Code 04(并查集 整型数组记录连通分量属性)
#include <iostream>
#include <vector>
#include <map>
#include <algorithm>
using namespace std;
const int maxn=2010;
map<string,int> si;
map<int,string> is;
int id=1,k,father[maxn],wt[maxn],awt[maxn],anum[maxn],head[maxn];//wt点权,g边权
int sti(string s) {
if(si[s]==0) {
si[s]=id; //从1开始
is[id]=s;
id++;
}
return si[s];
}
/* 并查集 初始化 */
void init() {
for(int i=0; i<maxn; i++) father[i]=i;
}
/* 并查集 查 */
int find(int x) {
int a = x;
while(x!=father[x])
x=father[x];
while(a!=father[a]) {
int temp=a;
a=father[a];
father[temp]=x;
}
return x;
}
/* 并查集 并 */
int Union(int a, int b) {
int x = find(a);
int y = find(b);
if(x<=y)father[y]=x;
else father[x]=y;
}
bool cmp(int a, int b) {
return is[head[a]]<is[head[b]];
}
int main(int argc,char * argv[]) {
init();
int n,w;
string s1,s2;
scanf("%d %d",&n,&k);
for(int i=0; i<n; i++) {
cin>>s1>>s2>>w;
int id1=sti(s1);
int id2=sti(s2);
Union(id1,id2);
wt[id1]+=w;
wt[id2]+=w;
}
for(int i=1; i<id; i++) {
int r = find(i);
awt[r]+=wt[i]; //累计权重
anum[r]++; //累计人数
if(wt[head[r]]<wt[i]) {
head[r]=i;
}
}
vector<int> v;
for(int i=1; i<id; i++) {
if(awt[i]>2*k&&anum[i]>2)v.push_back(i);
}
sort(v.begin(),v.end(),cmp); //不排序不符合条件,有两个测试点错误
printf("%d\n",v.size());
for(int i=0; i<v.size(); i++) {
printf("%s %d\n",is[head[v[i]]].c_str(),anum[v[i]]);
}
return 0;
}