目录
1、jieba.cut()和jieba.cut_for_search()的使用说明
2、jieba.lcut()的使用说明
3、jieba.add_word()的用法:动态修改词典
4、jieba.load_userdict():动态修改词典集)
5、wordcoloud库的使用说明
6、绘制鹿鼎记的词云图(未去掉停用词)
7、绘制鹿鼎记的词云图(去掉停用词)
1、jieba.cut()和jieba.cut_for_search()的使用说明
说明:如果需要本文的数据集,可以留言说明。觉得本文对您有帮助,可以关注一下这个博客,精彩抢先看。
1)导入相关库
import numpy as np
import pandas as pd
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from imageio import imread
import warnings
warnings.filterwarnings("ignore")
2)演示如下
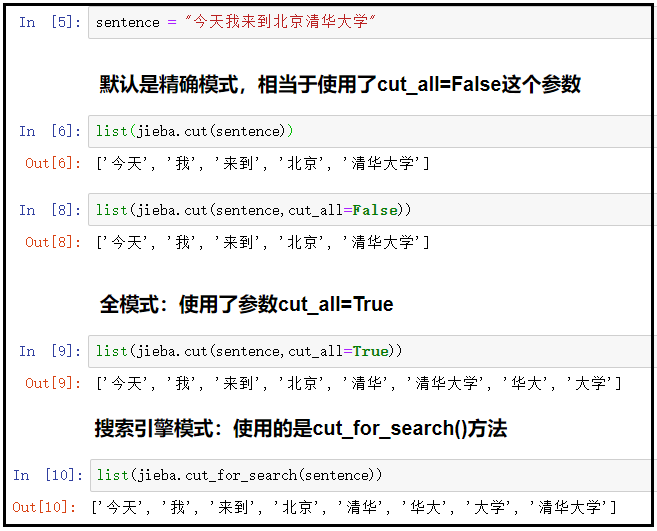
sentence = "今天我来到北京清华大学"
# 默认是精确模式,相当于使用了cut_all=False这个参数
list(jieba.cut(sentence))
list(jieba.cut(sentence,cut_all=False))
# 全模式:使用了参数cut_all=True
list(jieba.cut(sentence,cut_all=True))
# 搜索引擎模式:使用的是cut_for_search()方法
list(jieba.cut_for_search(sentence))
结果如下:
2、jieba.lcut()的使用说明
1)jieba.lcut()与jieba.cut()方法的区别
sentence = "今天我来到北京清华大学"
x = jieba.cut(sentence)
display(type(x))
list(jieba.lcut(sentence))
y = jieba.lcut(sentence)
display(type(y))
结果如下:

根据结果展示cut()方法生成的是一个generator(生成器),但是lcut()方法生成的结果是一个list列表。
当文本过大的时候,返回结果如果是一个生成器,当我们迭代生成器中的元素的时候,整个文本不会一次性加载到内存中的。我们知道,python是基于内存计算的,如果一下子加载到内存中的东西过大,会造成内存溢出的错误。
而lcut()方法就是这样,当我们使用这个方法切分文本的时候,会一次性返回一个列表,这个列表会一次性加载到内存中,当文本很大的时候,电脑会变得很卡。
2)jieba.lcut()的演示说明
sentence = "今天我来到北京清华大学"
jieba.lcut(sentence)
jieba.lcut(sentence,cut_all=True)
结果如下:

3、jieba.add_word()的用法:动态修改词典
sentence = "湖北广水第三条街,有一条狗"
list(jieba.cut(sentence))
结果如下:

针对上述切分结果,如果我们想把“湖北广水”和“第三条街”都当成一个完整词,而不切分开,怎么办呢?
此时,就需要借助add_word()方法,动态修改词典。
sentence = "湖北广水第三条街,有一条狗"
jieba.add_word("湖北广水")
jieba.add_word("有一条狗")
list(jieba.cut(sentence))
结果如下:

4、jieba.load_userdict():动态修改词典集
jieba.add_word()方法,只能一个个动态添加某个词语。假如我们需要动态添加多个词语的时候,就需要使用jieba.load_userdict()方法。也就是说:将所有的自定义词语,放到一个文本中,然后使用该方法,一次性动态修改词典集。
文本词典格式必须一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。文件必须为 UTF-8 编码。
详细使用方法,可以百度。
5、wordcoloud库的使用说明
6、绘制鹿鼎记的词云图(未去掉停用词)
1)什么是词云图?
“词云”就是对网络文本中出现频率较高的“关键词”予以视觉上的突出,形成“关键词云层”或“关键词渲染”,从而过滤掉大量的文本信息,使浏览网页者只要一眼扫过文本就可以领略文本的主旨。某个词的频率越高,那么字体就越大。
2)词云图的绘制步骤(没有去掉停用词)
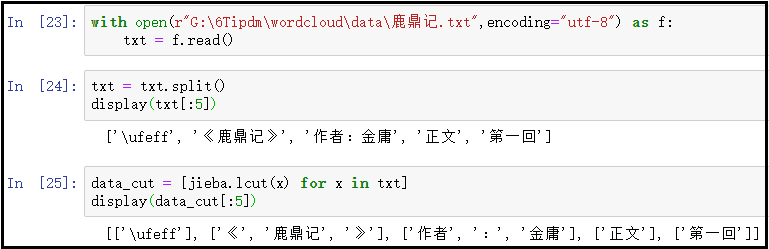
① 读取文件,并使用lcut()方法进行分词
with open(r"G:\6Tipdm\wordcloud\data\鹿鼎记.txt",encoding="utf-8") as f:
txt = f.read()
txt = txt.split()
display(txt[:5])
data_cut = [jieba.lcut(x) for x in txt]
display(data_cut[:5])
结果如下:
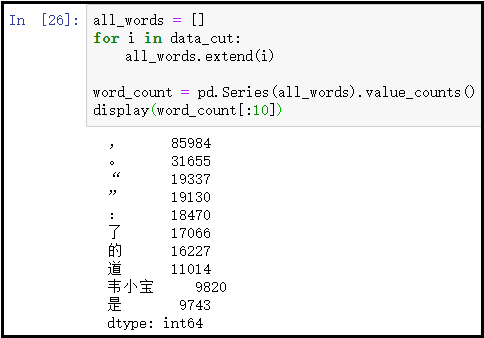
② 词频统计
all_words = []
for i in data_cut:
all_words.extend(i)
word_count = pd.Series(all_words).value_counts()
display(word_count[:10])
结果如下:
③ 绘制词云图
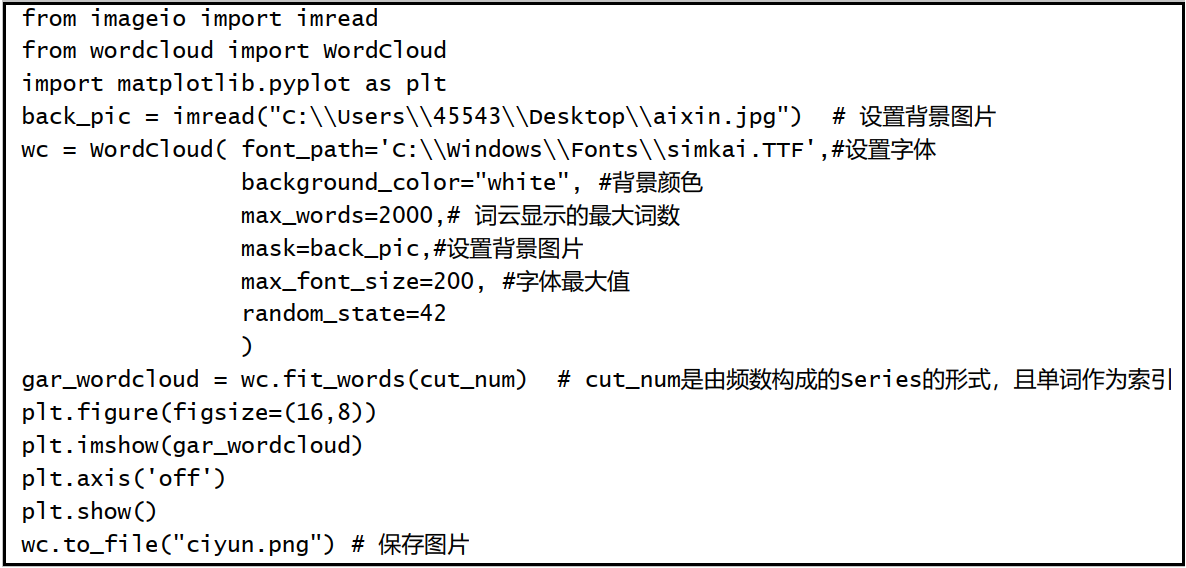
# 1、读取背景图片
back_picture = imread(r"G:\6Tipdm\wordcloud\alice_color.png")
# 2、设置词云参数
wc = WordCloud(font_path="G:\\6Tipdm\\wordcloud\\simhei.ttf",
background_color="white",
max_words=2000,
mask=back_picture,
max_font_size=200,
random_state=42
)
wc2 = wc.fit_words(word_count)
# 3、绘制词云图
plt.figure(figsize=(16,8))
plt.imshow(wc2)
plt.axis("off")
plt.show()
wc.to_file("ciyun.png")
结果展示:

7、去掉停用词后,绘制词云图
1)什么是停用词?
“停用词”指的是文本中出现频率很高,但实际意义又不大的词,像语气助词、副词、介词、连词等,通常自身并无明确意义,只有将其放入一个完整的句子中才有一定作用的词语。如常见的“的”、“在”、“和”、“接着”之类。还有一些符号,像 “,”,“!”等,也都没有实在意义。因此,在进行词频统计的时候,可以将这些词语事先剔除掉,在进行词云图的绘制。
2)详细步骤如下
① 导入相关库
import numpy as np
import pandas as pd
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from imageio import imread
import warnings
warnings.filterwarnings("ignore")
② 读取文本文件,并使用lcut()方法进行分词
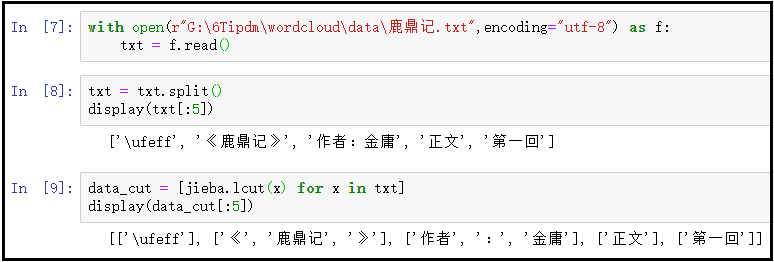
with open(r"G:\6Tipdm\wordcloud\data\鹿鼎记.txt",encoding="utf-8") as f:
txt = f.read()
txt = txt.split()
display(txt[:5])
data_cut = [jieba.lcut(x) for x in txt]
display(data_cut[:5])
结果如下:
③ 读取停用词
with open(r"G:\6Tipdm\wordcloud\data\stoplist.txt",encoding="utf-8") as f:
stop = f.read()
stop = stop.split()
stop = [" ","道","说道","说"] + stop
display(stop[:5])
结果如下:

④ 去掉停用词之后的最终词
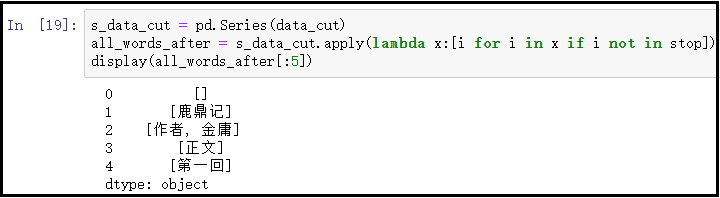
s_data_cut = pd.Series(data_cut)
all_words_after = s_data_cut.apply(lambda x:[i for i in x if i not in stop])
display(all_words_after[:5])
结果如下:
⑤ 词频统计
all_words = []
for i in all_words_after:
all_words.extend(i)
word_count = pd.Series(all_words).value_counts()
display(word_count[:10])
结果如下:

⑥ 绘制词云图
# 1、读取背景图片
back_picture = imread(r"G:\6Tipdm\wordcloud\alice_color.png")
# 2、设置词云参数
wc = WordCloud(font_path="G:\\6Tipdm\\wordcloud\\simhei.ttf",
background_color="white",
max_words=2000,
mask=back_picture,
max_font_size=200,
random_state=42
)
wc2 = wc.fit_words(word_count)
# 3、绘制词云图
plt.figure(figsize=(16,8))
plt.imshow(wc2)
plt.axis("off")
plt.show()
wc.to_file("ciyun.png")
结果展示:

3)更换绘图背景,绘制中国地图词云图
# 1、读取背景图片
back_picture = imread(r"G:\6Tipdm\wordcloud\china.png")
# 2、设置词云参数
wc = WordCloud(font_path="G:\\6Tipdm\\wordcloud\\simhei.ttf",
background_color="white",
max_words=2000,
mask=back_picture,
max_font_size=200,
random_state=42
)
wc2 = wc.fit_words(word_count)
plt.figure(figsize=(16,8))
plt.imshow(wc2)
plt.axis("off")
plt.show()
wc.to_file("ciyun.png")
结果展示:

