一、主题
本次只是简单的爬取广东轻工职业技术学院的校园新闻并将爬取信息生成词云进行分析
二、实现过程
1.在广东轻工职业技术学院官网中进入校园新闻模块,首先点击其中一条新闻,通过开发者工具(F12)分析获取新闻的标题,发布时间以及链接以字典news{}存放起来,并将新闻内容写到content.txt中
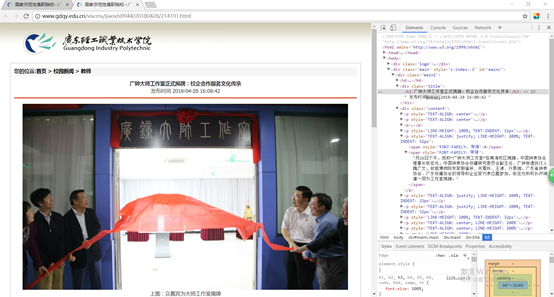
# 获取一条新闻的信息
def getNewDetails(newsUrl):
resd = requests.get(newsUrl)
resd.encoding = 'utf-8'
soup = BeautifulSoup(resd.text, 'html.parser')
news = {}
news['标题'] = soup.select('div > h3')[0].text
a = news['标题']
news['发布时间'] = (soup.select('.title')[0].text).lstrip( '{}发布时间 '.format(a))
news['链接'] = newsUrl
content = soup.find_all('div',class_='content')[0].text
writeNewsDetail(content)
return news
# 将获取到的新闻内容写到content.txt中
def writeNewsDetail(content):
f = open('content.txt','a',encoding='utf-8')
f.write(content)
f.close()

2.既然能将一条新闻的信息获取到了,就可以将一个新闻页面的所有新闻也获取到。如何获取到页面中所有新闻的网址呢?老办法,摁F12打开开发者工具,找到新闻网址所在标签就行啦

# 获取一个新闻页面的所有新闻的网址
def getListPage(newsurl):
res = requests.get(newsurl)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
soup = soup.find('div', class_='mainl')
newslist = []
for new in soup.select('ul > li > a'):
newsUrl = new.attrs['href']
newslist.append(getNewDetails(newsUrl))
return newslist
3.搞定一个页面也就可以把其他页面也解决了,由于广轻工的校园新闻只有54页,所以我就都爬下来了
# 由于第一个新闻页面的网址跟其他新闻页面不同
# 所以先将第一个页面的所有新闻的信息写入到newsTotal里面
newsurl = 'http://www.gdqy.edu.cn/viscms/xiaoyuanxinwen2538/index.html'
newsTotal = []
newsTotal.extend(getListPage(newsurl))
# 再将剩下的页面的新闻信息以循环写入
for i in range(2,55):
listPageUrl = 'http://www.gdqy.edu.cn/viscms/xiaoyuanxinwen2538/index_{}.html'.format(i)
newsTotal.extend(getListPage(listPageUrl))
4.将之前获取到的新闻信息(标题,发布时间以及链接)存放到Excel表里面
# 将获取到新闻信息存放到Excel表news.xlsx里面
df = pandas.DataFrame(newsTotal)
df.to_excel('news.xlsx',encoding='utf-8')
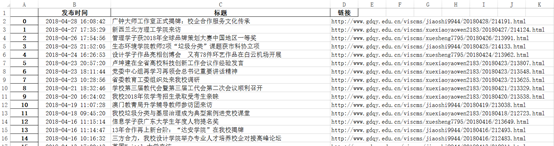
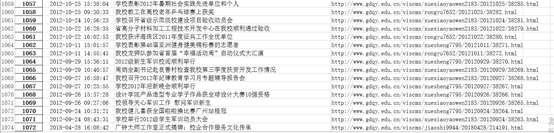
5.到了这里就已经将所有信息爬取完了,接下来就可以对信息进行结巴分词并生成词云了
file = codecs.open('content.txt', 'r','utf-8')
# 以所给图片为背景生成词云图片
image=np.array(Image.open('tree.jpg'))
# 词云字体设置
font=r'C:\Windows\Fonts\simhei.ttf'
word=file.read()
#去掉英文,保留中文
resultword=re.sub("[A-Za-z0-9\[\`\~\!\@\#\$\^\&\*\(\)\=\|\{\}\'\:\;\'\,\[\]\.\<\>\/\?\~\!\@\#\\\&\*\%]", "",word)
wordlist_after_jieba = jieba.cut(resultword, cut_all = True)
wl_space_split = " ".join(wordlist_after_jieba)
print(wl_space_split)
my_wordcloud = WordCloud(font_path=font,mask=image,background_color='white',max_words = 100,max_font_size = 100,random_state=50).generate(wl_space_split)
#根据图片生成词云
iamge_colors = ImageColorGenerator(image)
#my_wordcloud.recolor(color_func = iamge_colors)
#显示生成的词云
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
#保存生成的图片,当关闭图片时才会生效,中断程序不会保存
my_wordcloud.to_file('result.jpg')
生成词云的图片(大家可根据自己喜欢的图片进行词云形状的生成)


三、遇到的问题及解决办法
问题:安装词云的时候出错(当时出错的时候没有截图)
解决方法:通过上网了解,发现是由于本人电脑的Python版本是32位的,而之前安装的词云是64位的,所以出现了错误,在网上重新下载并安装了32位的词云之后就解决了
步骤:1.选择wordcloud-1.4.1-cp36-cp36m-win32.whl进行下载
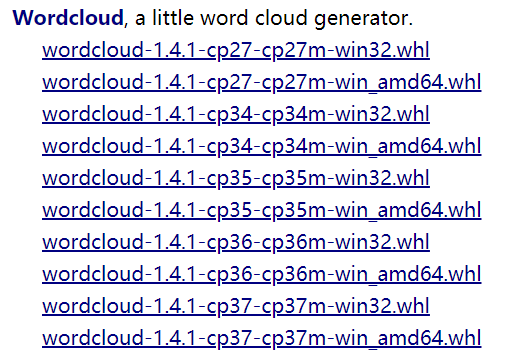
2.打开命令行输入 pip install wordcloud-1.4.1-cp36-cp36m-win32.whl以及 pip install wordcloud 进行安装
3.安装成功后到pycharm添加依赖就行了
四、数据分析及结论
通过数据我们看到校园新闻主要是对校园各院的情况(其中设计学院为甚)、党委工作以及职业技术等信息的报道
五、完整代码
import requests
from bs4 import BeautifulSoup
import pandas
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
import codecs
import numpy as np
from PIL import Image
import re
# 将获取到的新闻内容写到content.txt中
def writeNewsDetail(content):
f = open('content.txt','a',encoding='utf-8')
f.write(content)
f.close()
# 获取一条新闻的信息
def getNewDetails(newsUrl):
resd = requests.get(newsUrl)
resd.encoding = 'utf-8'
soup = BeautifulSoup(resd.text, 'html.parser')
news = {}
news['标题'] = soup.select('div > h3')[0].text
a = news['标题']
news['发布时间'] = (soup.select('.title')[0].text).lstrip( '{}发布时间 '.format(a))
news['链接'] = newsUrl
content = soup.find_all('div',class_='content')[0].text
writeNewsDetail(content)
return news
# 获取一个新闻页面的所有新闻的网址
def getListPage(newsurl):
res = requests.get(newsurl)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text, 'html.parser')
soup = soup.find('div', class_='mainl')
newslist = []
for new in soup.select('ul > li > a'):
newsUrl = new.attrs['href']
newslist.append(getNewDetails(newsUrl))
return newslist
# 由于第一个新闻页面的网址跟其他新闻页面不同
# 所以先将第一个页面的所有新闻的信息写入到newsTotal里面
newsurl = 'http://www.gdqy.edu.cn/viscms/xiaoyuanxinwen2538/index.html'
newsTotal = []
newsTotal.extend(getListPage(newsurl))
# 再将剩下的页面的新闻信息以循环写入
for i in range(2,55):
listPageUrl = 'http://www.gdqy.edu.cn/viscms/xiaoyuanxinwen2538/index_{}.html'.format(i)
newsTotal.extend(getListPage(listPageUrl))
for news in newsTotal:
print(news)
# 将获取到新闻信息存放到Excel表news.xlsx里面
df = pandas.DataFrame(newsTotal)
df.to_excel('news.xlsx',encoding='utf-8')
file = codecs.open('content.txt', 'r','utf-8')
# 以所给图片为背景生成词云图片
image=np.array(Image.open('tree.jpg'))
# 词云字体设置
font=r'C:\Windows\Fonts\simhei.ttf'
word=file.read()
#去掉英文,保留中文
resultword=re.sub("[A-Za-z0-9\[\`\~\!\@\#\$\^\&\*\(\)\=\|\{\}\'\:\;\'\,\[\]\.\<\>\/\?\~\!\@\#\\\&\*\%]", "",word)
wordlist_after_jieba = jieba.cut(resultword, cut_all = True)
wl_space_split = " ".join(wordlist_after_jieba)
print(wl_space_split)
my_wordcloud = WordCloud(font_path=font,mask=image,background_color='white',max_words = 100,max_font_size = 100,random_state=50).generate(wl_space_split)
#根据图片生成词云
iamge_colors = ImageColorGenerator(image)
#my_wordcloud.recolor(color_func = iamge_colors)
#显示生成的词云
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
#保存生成的图片,当关闭图片时才会生效,中断程序不会保存
my_wordcloud.to_file('result.jpg')
六、个人感受与体会
其实本来我是想爬英雄联盟官网的的赛事新闻模块的,可是在爬的过程遇到很多,比如某条新闻的网址跟新闻页标签的网址是不一样的,而且就算网址解决了,在获取新闻信息的时候,明明标签等打对了,获取到的信息根本不是目标信息或者根本找不到,最后不得不放弃选择广轻工的新闻模块进行爬取。虽然两次爬虫经历遇到的问题很多,但看到爬取的信息一条条显示出来的时候心里还是有点成就感的,在过程中也学到了不少新知识,比如词云的生成。总得来说,有尝试就有收获,还需多练习努力。