要求:
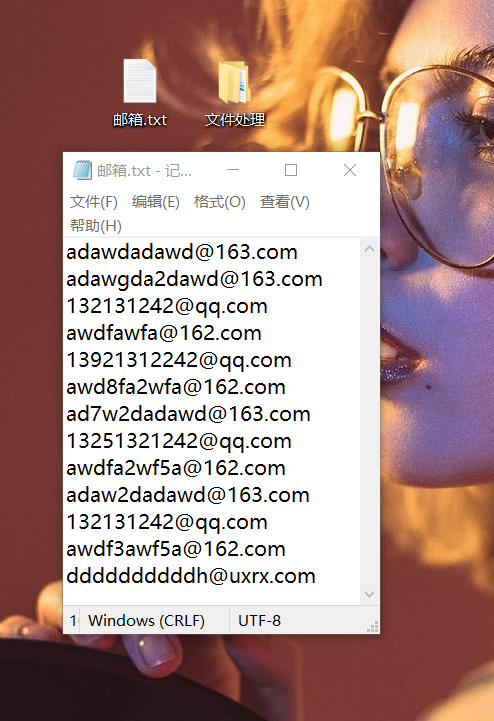
把邮箱.txt中的数据按照邮箱格式进行分类处理 处理结果保存到 文件处理文件夹中
思路:
循环 按行读取 邮箱.txt 中的内容 每行数据用截断分理处邮箱类型 判断创建文件夹
话不多说,操练起来ヽ(* ̄▽ ̄*)ノ
import os txtpath = r"C:\Users\23678\Desktop\邮箱.txt"#文本路径 maildir = r"C:\Users\23678\Desktop\文件处理\\"#存储目录 a = open(txtpath)#打开文本 num = 0 hangshu = len(open(txtpath).readlines()) #处理数据 while num < hangshu: mailtype = a.readline().split("@")[1].split(".")[0]#截断出邮箱类型 # 存储目录中 以邮箱类型创建邮箱文件夹 createMd = os.path.join(maildir, mailtype)#拼接路径 if not os.path.exists(createMd):#目录判断 如果不存在则创建 os.mkdir(createMd) path2 = createMd + '\邮箱.txt' f = open(path2, "a") # 创建txt文件 else: pass num += 1 print(num)
运行结果