缓存机制和redis基础
什么是缓存,为什么要使用缓存
- 缓存关系数据库(常见的有Mysql)并发访问的压力:热点数据
- 减少响应时间:内存IO速度比磁盘快
- 提升吞吐量:Redis等内存数据库单机就可以支撑很大的并发
Redis和Memcached区别
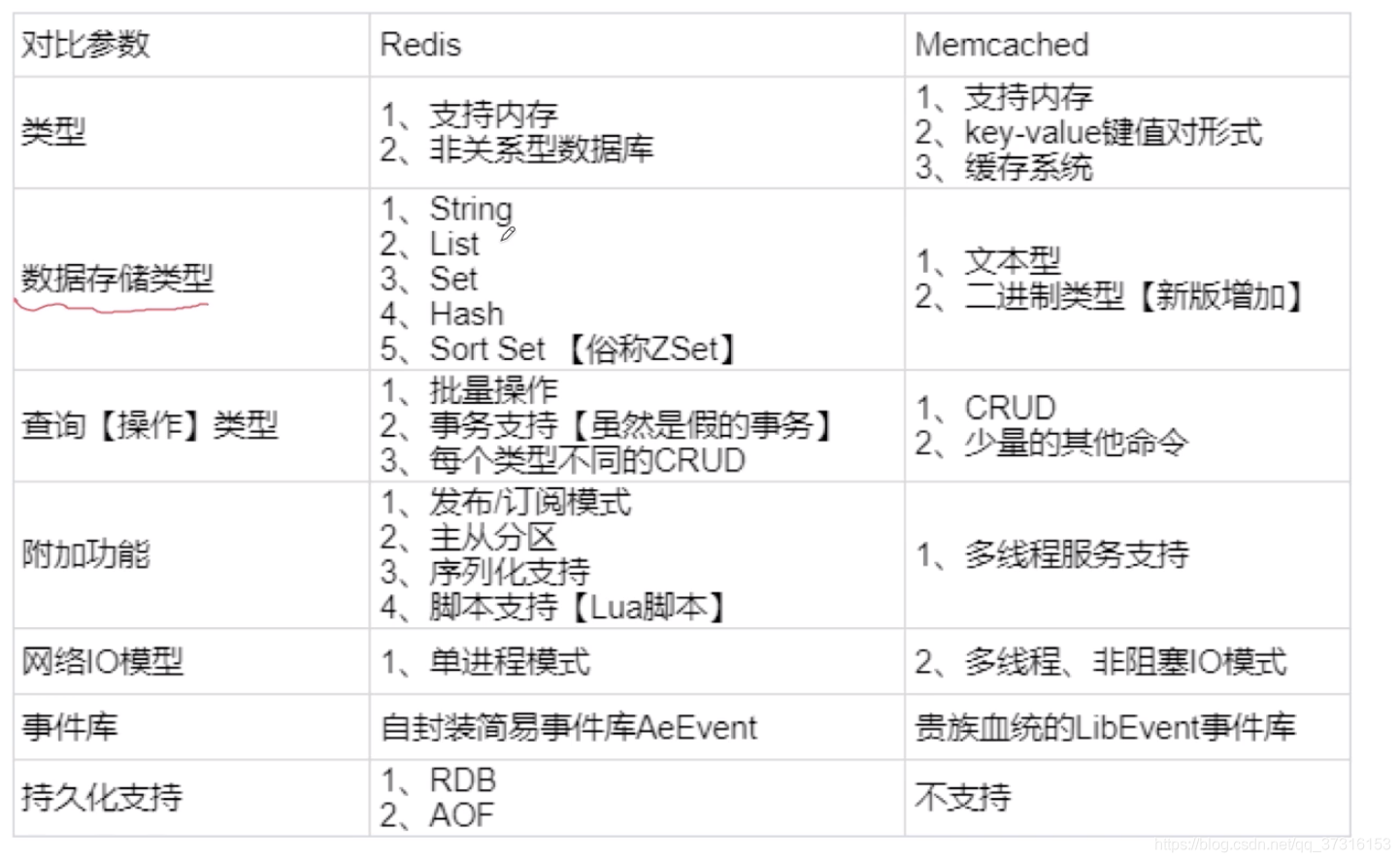
Redis常用的数据类型
- String(字符串):用来实现简单的KV键值对存储、比如计数器
- List(链表):实现双向链表,比如用户的关注,粉丝列表
- Hash(哈希表):用来存储彼此相关的信息的键值对
- Set(集合):存储不重复元素、比如用户的关注者
- Sorted Set(有序集合):实施信息排行榜
Redis内置实现
注:可观看书籍《Redis设计与实现》
- String:整数或者sds
- List:ziplist或者double linked list(ziplist:通过一个连续的内存块实现list结构,其中的每个entry节点头部都保存前后节点长度信息,实现双向链表功能)
- Hash:ziplist或者hashtable
- Set:intest或者hashtable
- SortedSet:skiplist链表
Redis两种持久化方式
- 快照方式:把数据快照放在磁盘二进制文件中,dump.rdb。缺点:会缺失时间段内的数据
- AOF:每写一个命令追加到appendonly.aof文件中。优点:不会缺失。缺点:数据文件大,恢复速度慢
- 通过修改redis配置文件
Redis事务
- 将多个请求打包,一次性,按序执行多个命令的机制
- Redis通过MULTI、EXEC、WATCH等命令实习事务功能
Redis如何实现分布式锁
- 使用setnx实现加锁,可以同时通过expire添加超时时间
- 锁的value值可以使用一个随机的uuid或者特定的命名
- 释放锁的时候,通过uuid判断是否是该锁,是则执行delete释放锁
缓存的使用模式
- Cache Aside:同时更新缓存和数据库
- Read/Write Through:先更新缓存,缓存负责同步更新数据库
- Write Behind Caching:先更新缓存,缓存定期异步更新数据库
如何解决缓存穿透的问题
原因:大量查询不到的数据请求落到后端数据库,数据库压力增大
- 由于大量缓存查不到就去数据库取,数据库也没有要查的数据
- 解决:对于没有查到返回None的数据也缓存
- 插入数据的时候删除相对于的缓存数据,或设置比较短的过期时间
如何解决缓存击穿的问题
原因:某些非常热点的数据key过期,大量请求打到后端数据库
- 分布式锁:获取锁的线程从数据库拉取数据更新缓存,其他的线程等待
- 异步后台更新:后台任务针对过期的key自动刷新
如何解决缓存雪崩的问题
缓存不可用或者大量的缓存key同时失效,大量的请求直接打到数据库
- 多级缓存:不同级别的key设置不同的超时时间
- 随机超时:key的超时时间随机设置,防止同时超时
- 架构层:提示系统的可用性。监控,报警完善
