HIT_SZ计算理论project
所有实验均在Ubuntu下编写和测试,亲测在Windows下结果不正确。
一、project 1
实验一
实验内容:编写程序实现利用正则表达式匹配IP地址。要求能够正确匹配合法的IP地址格式。
很简单,没什么好说的。但听说有很多同学用“调包”的方法,但我至今也没弄清楚调的是什么包。(手动笑哭emoj)
直接放上实验报告里的Design部分。
A. Design
In this experiment, I construct a program to read a regular a ipv4 address and check it if it is a correct one. Specially, we regard those ipv4 address which consist of four number between and 255 and separated by three dots as correct addresses.
So I just read characters into a buffer until meeting a dot, then transform them to corresponding integers and check it if in the range of 0 to 255. If so, go and check the next integer. Otherwise, it’s not a correct ipv4 address. When reading the ‘\0’ means it has been the end of this string, if now exactly 4 integers and 3 dots have been checked, then we say this string is a correct ipv4 address. Otherwise, it’s not.
实验二
实验内容:编写程序实现从正则表达式到非确定性有穷自动机(NFA)的转换。输入数据从文件读取。正则表达式的形式化定义可参考中文课本(第二版)P38相关内容。NFA的形式化定义可参考中文课本(第二版)P32相关内容,并设计数据结构以在计算机中表示。
NFA的数据结构:
// The item of Transition Function List.
typedef struct func{
int this_q;
int next_q;
struct func *next_func;
} func;
// NFA container.
struct {
int Q; // States.
char *Alphabet; // Accepted characters.
int q0; // Start state.
func **Func; // Transition functions.
int *F; // End states.
int Alphabet_size;
int F_size;
} n;思路也跟ip差不多,一个字符一个字符读进来,根据字符进行下一步具体的操作。同样放上实验报告里的部分内容:
A. Design
In this experiment, I construct a program to read a regular expression from file and then use it to construct a NFA. Specially, I was programming with C for higher performance.
In this program, I use a C structure to store the NFA. The NFA structure consists of five main parts which represent “states set”, “alphabet”, “start state”, “transition functions” and “end states”. In which transition functions are also be designed as a special data structure. What’s more, I also declare a structure to store the context of this program, it contains some information about where the ‘(‘ or ‘|’ starts, and about back to which position when meeting ‘’ and ‘)’. For more details, you can check it in my code and annotations.
Mainly using above two structures, I use a function named as “go” to read one character every time and determine the next step:
1) If it’s a letter in alphabet, then add a transition edge to the NFA.
2) If it’s a left bracket or ‘|’, then store this position and recursively call the “go” function.
3) If it’s a ‘’ then add an edge to its start position stored in context structure.
4) If it’s a right bracket then return back to the function that calling it.
After constructing a NFA, I also write a function which can use this NFA to recognize a language that accepted by this NFA. It just follows the states transition regulations of this NFA. And it is also a recursive function.

一个不严谨的workflow。总之,遇到字符就直接加一个状态图节点;遇到左括号就递归调用这个函数,把括号里的当成另一个正则表达式处理;遇到右括号就跳出递归,返回上一次被调用时的现场;遇到星号就要加一条边指向前面某个位置;遇到或符号则需要从或符号左侧表达式的开端开始,并把右侧的当成一个新的表达式递归处理,最后返回现场时还要把左右两侧的后继也连在一起。至于前面反复提到的“现场”,则是用一个专用的数据结构context(上下文)来保存的:每读入一个字符都要相应地更新现场。
// Context of NFA.
typedef struct {
int bracket_depth; // The number of pairs of brackets.
int *end_now; // The end states by now.
int or_start; // Back to here when meeting operation "or(|)".
int star_start; // ...... operation "star(*)".
int end_num; // The number of end states by now.
} context_;二、project 2
实验内容:设计一个图灵机M,用于判定接收符合如下条件的字符串:
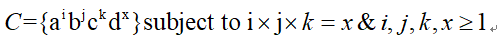
并要求画出图灵机的状态图。
因为只需要识别一个特定的语言,这个实验也就很简单了。直接画出状态转移图,然后照着图写程序就可以了。
typedef struct function {
char now;
char new;
int move;
int q;
} function;
typedef struct {
int Q;
int q1;
int reject;
int accept;
char *inputAlphabet;
char *tapeAlphabet;
function **transition;
int i_num;
int t_num;
int *func_num;
} TM;
三、源代码
https://github.com/DDDCai/projects-of-TOC/
