
获取更多资讯,赶快关注上面的公众号吧!
文章目录
首先和大家说声抱歉,好长时间没发文了,原因是原计划年后很快就返回工作岗位,为了方便旅途就没带电脑回家,结果又遇上了这个新型冠状病毒肺炎,导致在家无法顺畅地工作,只能看看视频、论文来充充电,希望疫情早点过去,武汉加油!中国加油!过年这几天大家处于休息状态中,粉丝数也没涨,不过近几天又有不少粉丝开始关注了,我想也是时候发文更新了,今天给大家带来一篇关于深度强化学习求解调度问题的论文。
该论文是由清华大学于2020年1月份发表在IJPR,由于和自己的研究方向具有很强的相关性,所以下面对这篇论文进行详细地解读,由于是在手机上操作,所以在排版方面没有进行美化,还请见谅。
摘要

强化学习正用于自动生产线调度以提升自适应性和柔性,然而,现有的方法仅考虑了加工时间确定已知的情况,忽略了生产线布局和运输单元,如机器人。文中采用深度强化学习调度自动生产线,无需手动提取特征,克服了缺失结构化数据的问题。首先提出了一种离散自动生产线的状态建模方法,适用于具有多个加工单元的线性,并行和可重入生产线。第二提出了一种基于深度强化学习的自动生产线智能调度算法,该算法建立了深度强化学习的离散事件仿真环境。最后将智能调度算法用于调度线性、并行和可重入自动生产线,实验结果表明,在加工时间随机情况下,该调度策略相比较于启发式调度方法,可以取得优越性能,并能维持稳定的收敛性和鲁棒性。
结论

基于深度强化学习的智能调度是一种使用深度强化学习调度单一产品离散自动生产线的调度方法,相比较于启发式调度方法,深度强化学习,在线性、并行和可重入离散自动生产线上实现了优越的性能,并对随机加工时间表现的较好的鲁棒性。同时收敛后的振动会约束深度强化学习调度策略的性能,这需要进一步的研究。此外,本文中智能调度主要关注异构加工单元,每个单元仅有一台机床,希望进一步研究使用状态建模c如何进行调度。
1引言
离散自动生产线用于生产复杂的产品,其中,运输单元用于抓取和运送产品,加工单元用于加工产品。原材料和半成品的自动转运带来了调度中同时将任务分配给加工单元和运输单元的问题,大多现有的研究假设加工时间确定,典型的方法有数学规划,甘特图,petri网和分枝定界。
离散自动生产线包含多个加工、装配、检验和多自由度机械手用于转运产品。每个设备具有装配或位置检验的高复杂性,其实际加工时间是随机的,因此,调度系统并不知道每道工序准确的加工时间,离线全局调度从而也是不可行的。
本文提出了一种基于强化学习的在线调度方法,并验证了学习到的策略对随机加工时间是鲁棒的。强化学习无需给定初始标签就可以学习系统策略,但深度强化学习用于处理连续事件,如Atari,Go。然而,离线自动生产线的调度是典型的离散事件任务,因此,为了保证调度系统学习有效策略,为强化学习搭建了准确有效的仿真环境。
2文献综述
通过综述了以前的论文,指出了现有的研究存在两个缺点,(1)当前的离散自动生产线调度方法关注加工单元和产品,而不是运输消耗,因此考虑运输移动是至关重要的。(2)当前的自适应或智能调度,主要关注于机器故障和任务到达,而不是加工时间的随机性,有必要研究加工时间的随机性对调度策略的影响。
3基于DRL的调度
所研究的自动生产线无缓存,具有n个不同的加工单元,一个运输单元。调度就是分配运输单元如何运输产品。
当产品被运至下一加工单元,将会产生一个随机加工时间,然而调度系统并不知道打道工序何时会加工完成,当一道工序完成加工,调度系统就会观察生产线状态的转移,然后进行响应,将产品运输至下一加工单元。
基于深度强化学习的智能调度,包含深度强化学习代理和离散事件仿真环境,如图1所示。
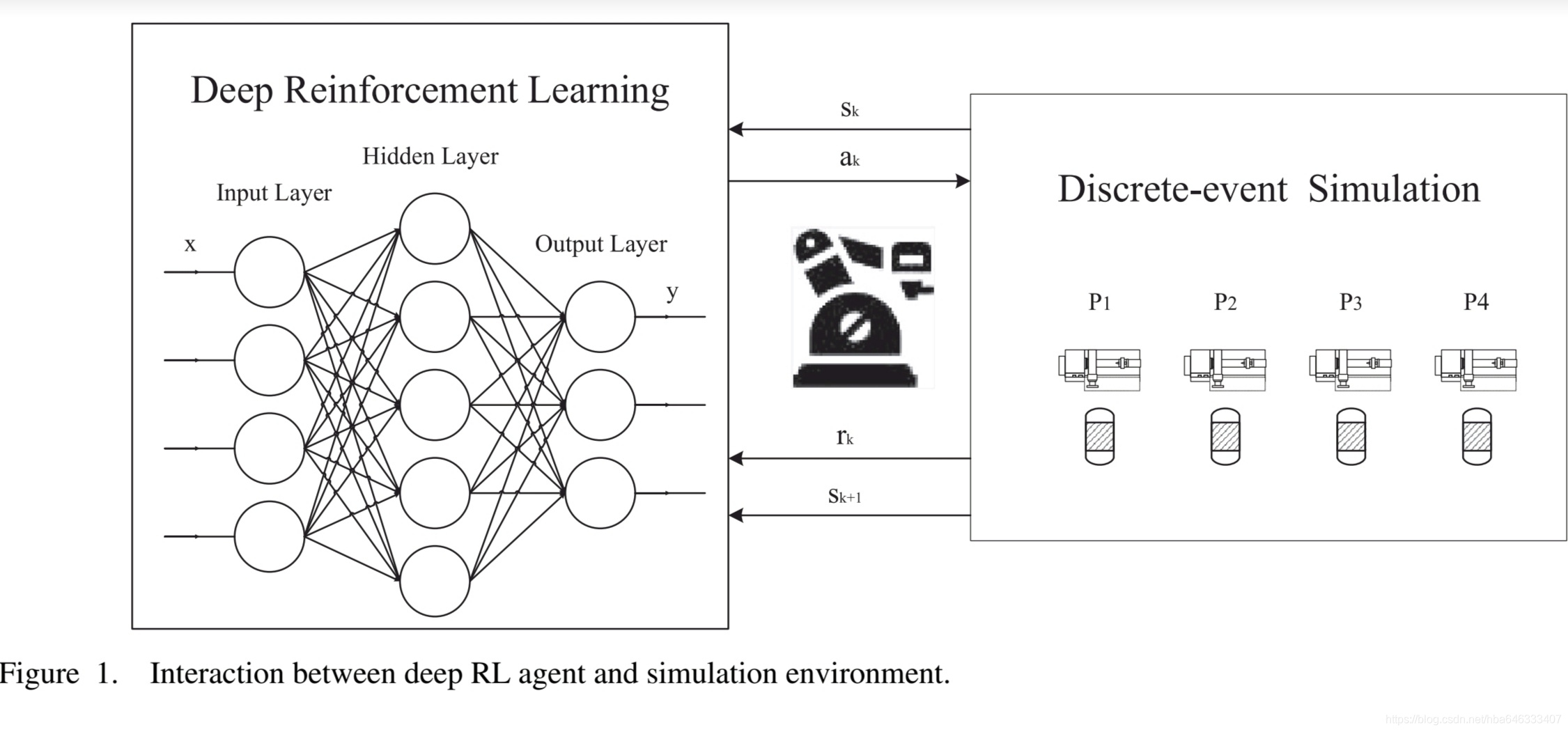
3.1基于深度强化学习的智能调度
3.1.1加工单元的状态建模
调度系统可以观察到整个生产线,所以状态几乎包含了生产线的所有信息,文中给出了三种状态建模。
a每个加工单元的繁忙或空闲
该场景下,假设所有的加工单元是异构的,且工艺流程不可重入,当加工单元正在加工时,为繁忙状态,否则为空闲状态,则有
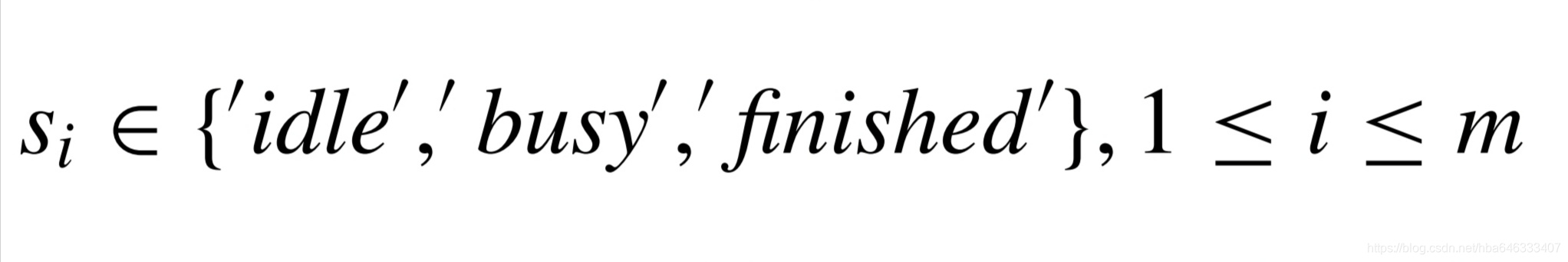
这个m维的向量表示m个加工机床的状态,优点是调度,可以不用考虑产品当前的工序或在制品数量,运输单元服务于加工机床以将产品从已完成的机床转运至下一加工机床。
该状态模型要求工艺是不可重入的,否则将违反马尔科夫属性,在不可重入工艺场景下,调度行为完全取决于当前状态,而不是到达当前状态的过程。例如,对于状态(’finished’,’idle’,’finished’)的可选行为为:运输1上的产品到2,或将3上的产品运出系统,而与上一状态(’busy’,’idle’,’finished’)或(’finished’,’idle’,’busy’)无关。

b工艺中每道工序的繁忙或空闲
该场景下,假设工艺是可以并行或可重入的,工序正在被加工的则为繁忙,否则为空闲,则有
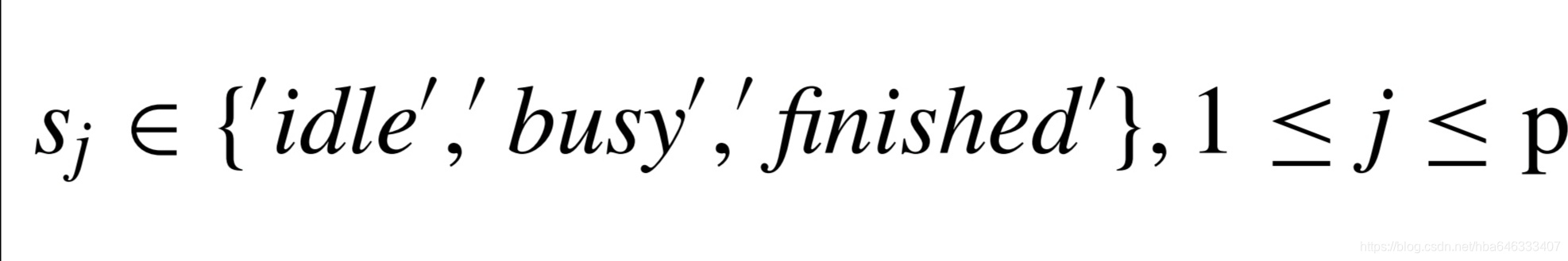
这样的一个p维向量表示具有p道工序的工艺状态。这种表示的优点在于允许生产中存在可重入加工。
c多加工资源状态
如果存在多台相同的加工机床,那么扩展的状态表示处于busy、idle、finished的加工机床数量,则有
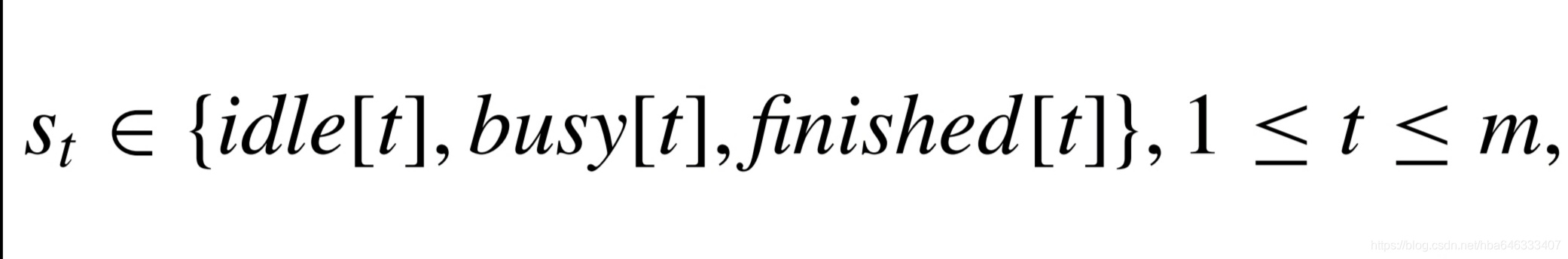
其中idle[t]+busy[t]+finished[t]=num[t],t表示第t类加工单元,一共m类。idle[t]表示第t类空闲加工单元的数量,那么(st)或(sj,st)就可以表达场景a或b下多加工单元调度的状态。
3.1.2运输单元的行为建模
可选行为集合包含了所有将完成的产品运至后处理的行为,特别地,将原材料运至生产线或将完成的产品运出生产线都是逻辑行为,然而并不是所有的逻辑行为都是合理的,合理行为应该保证前道已完成,且后道工序是空闲的。
3.1.3奖励建模
针对不同的行为给出不同的奖励。

3.1.4调度策略建模
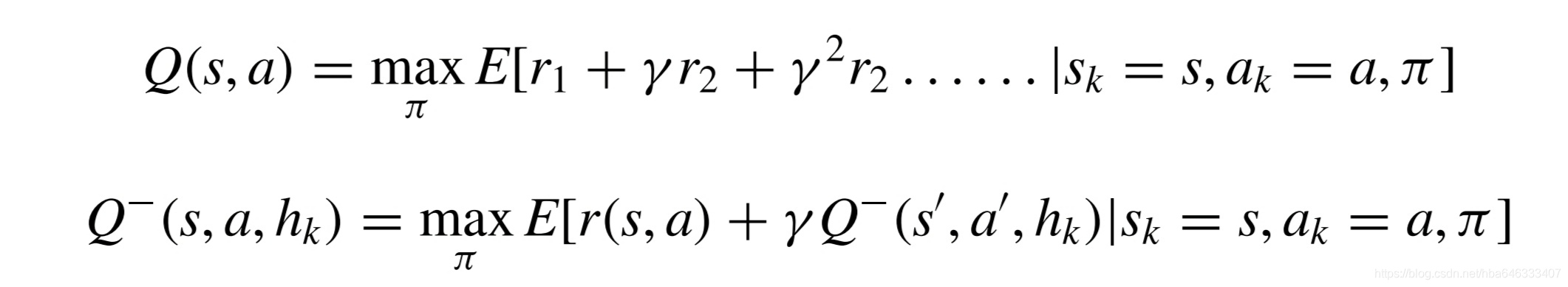
3.1.5调度算法学习迭代
优化的目标函数如下:
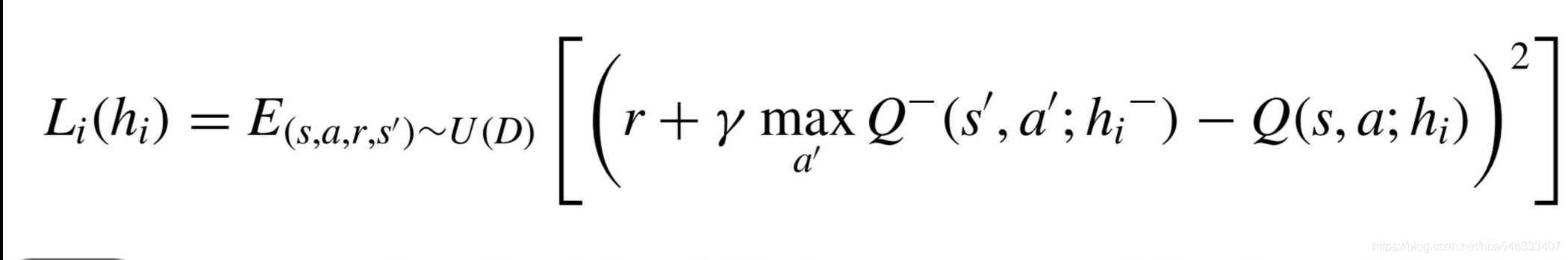
3.2离散事件仿真环境和基于深度强化学习的调度仿真算法

4调度实验
4.1线性生产线:加工单元状态
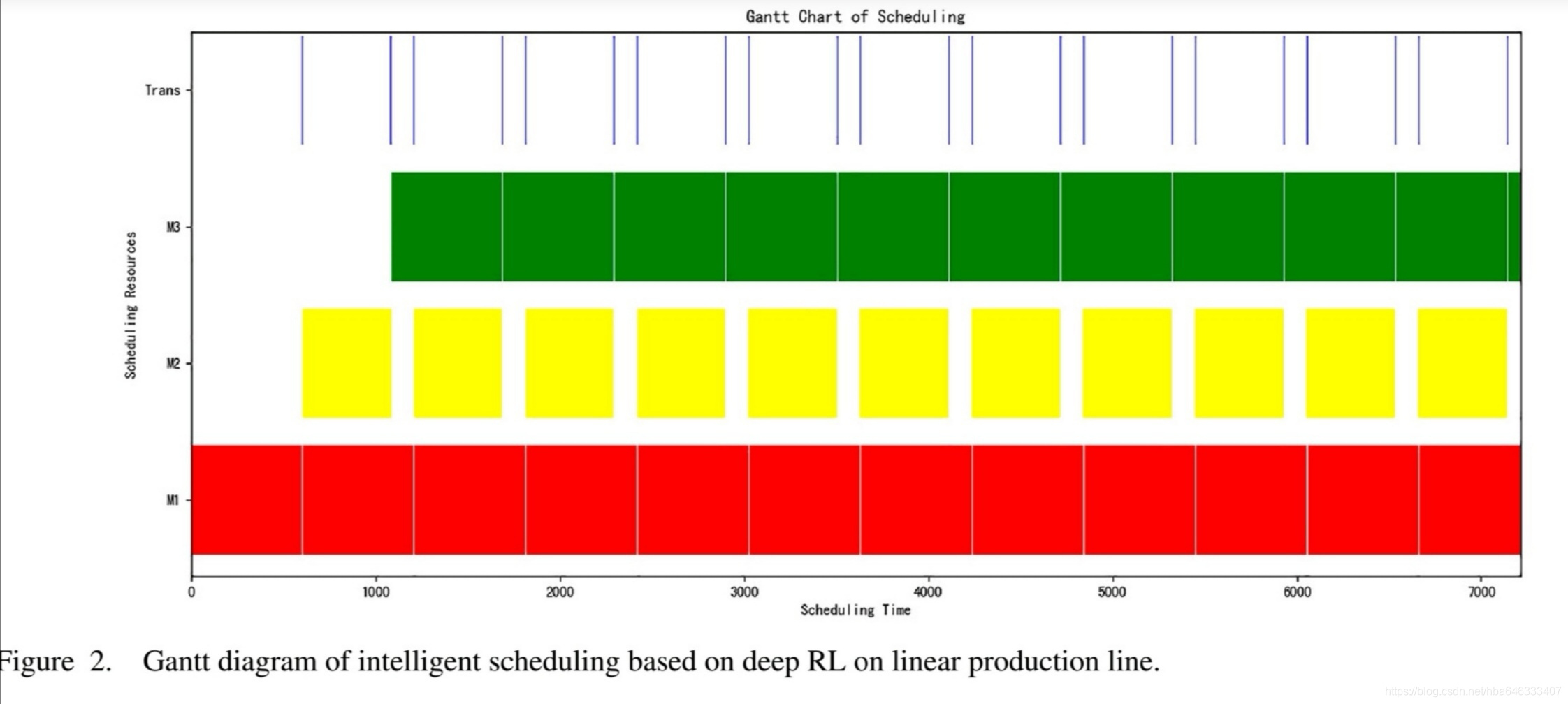
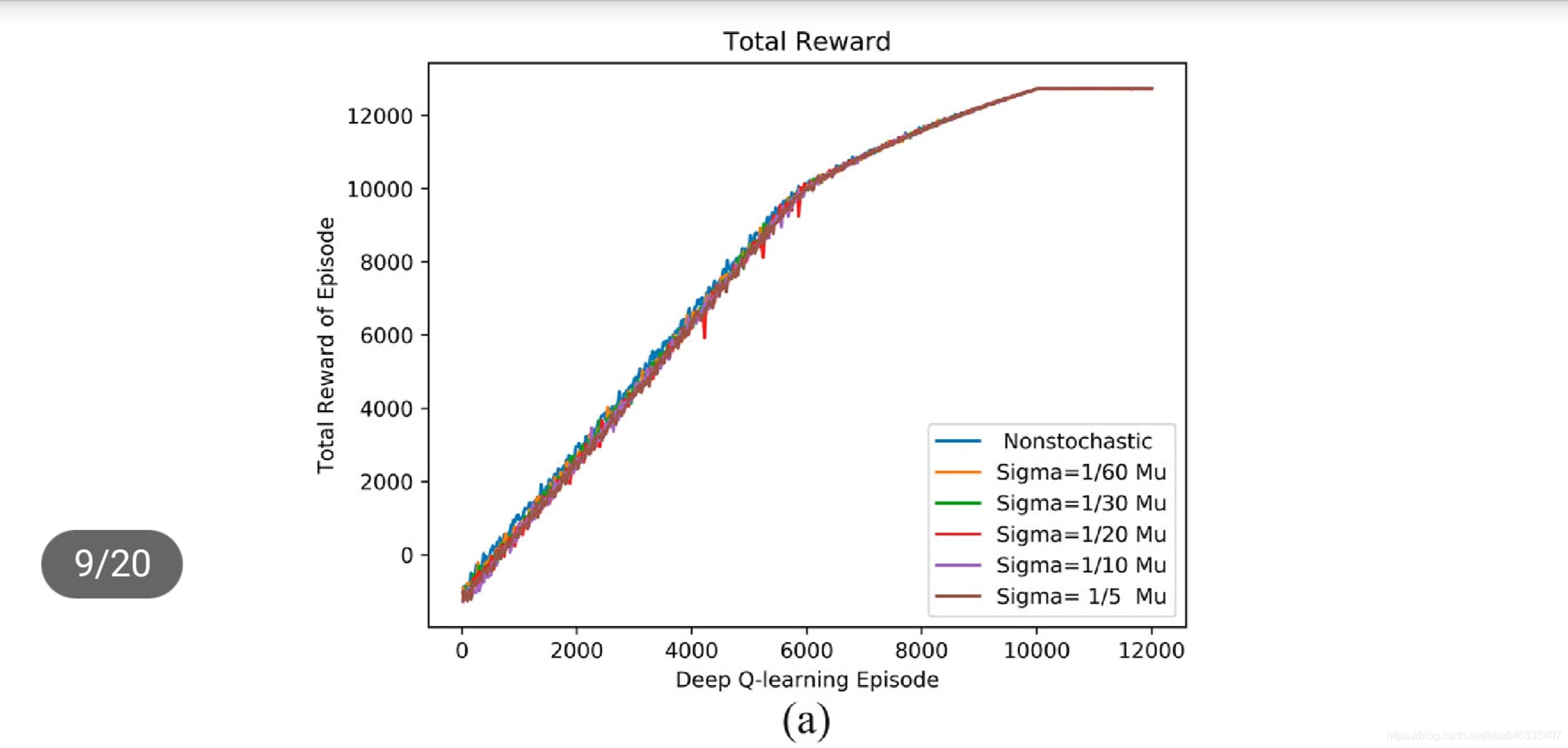
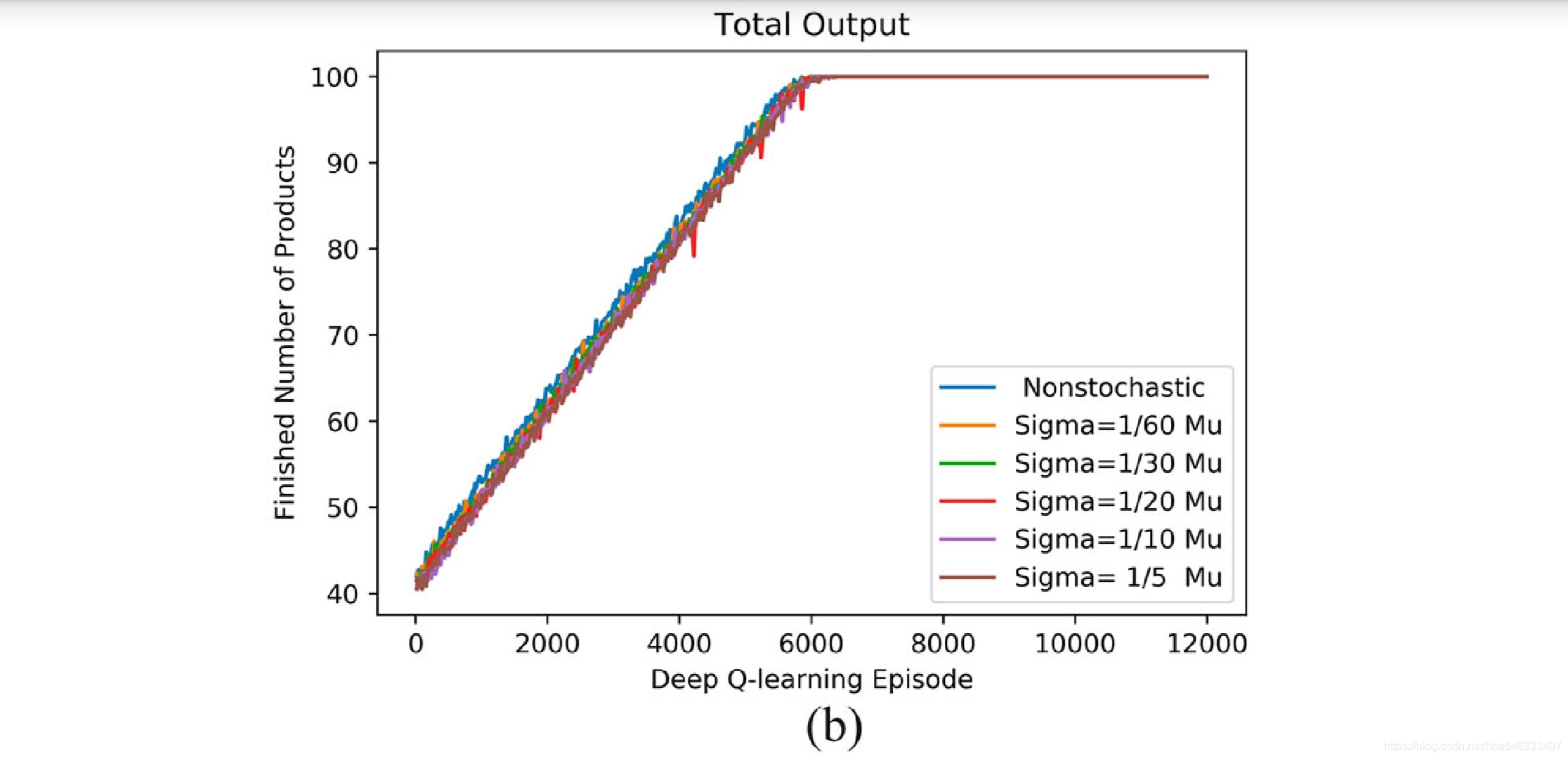
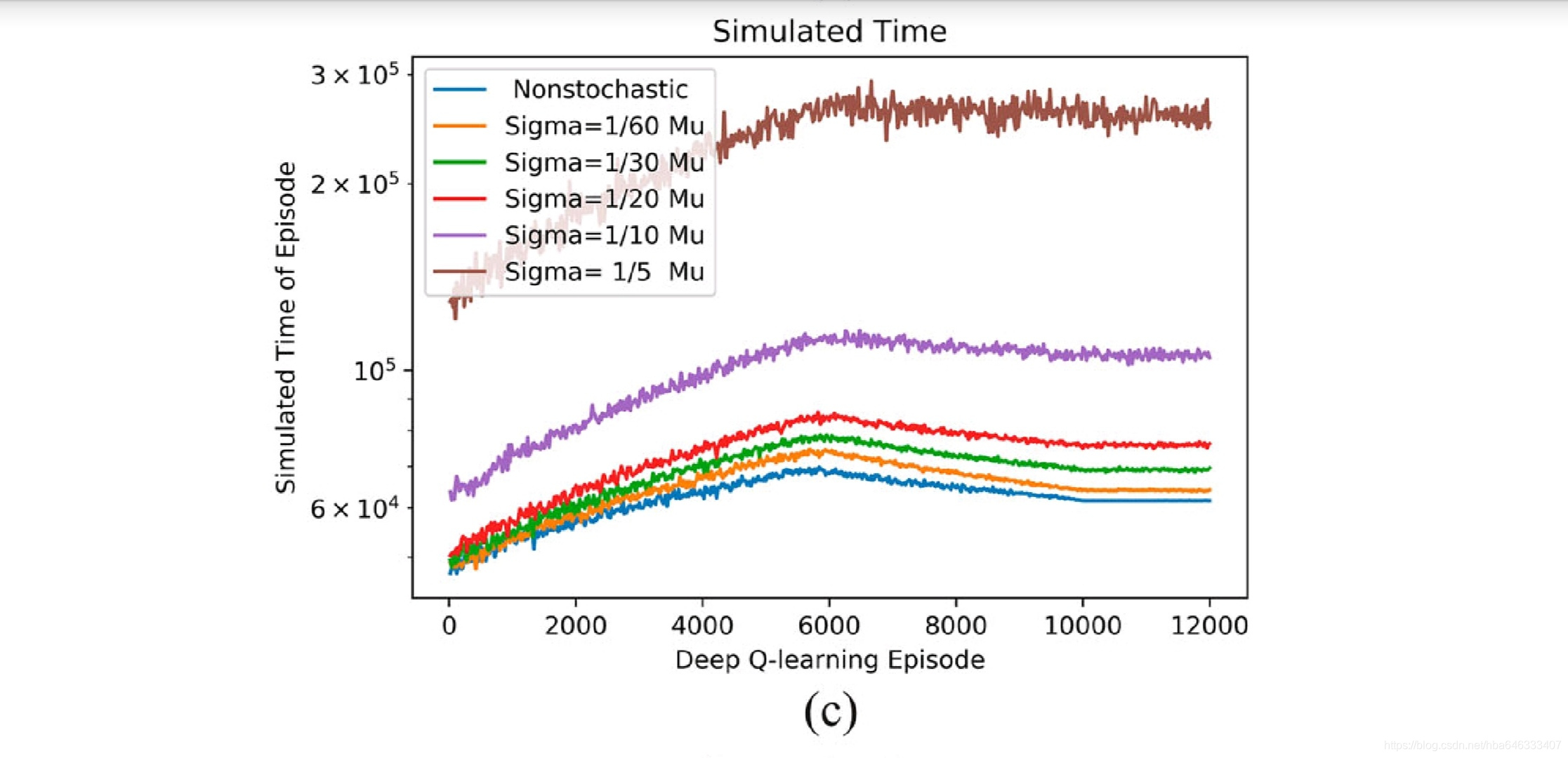
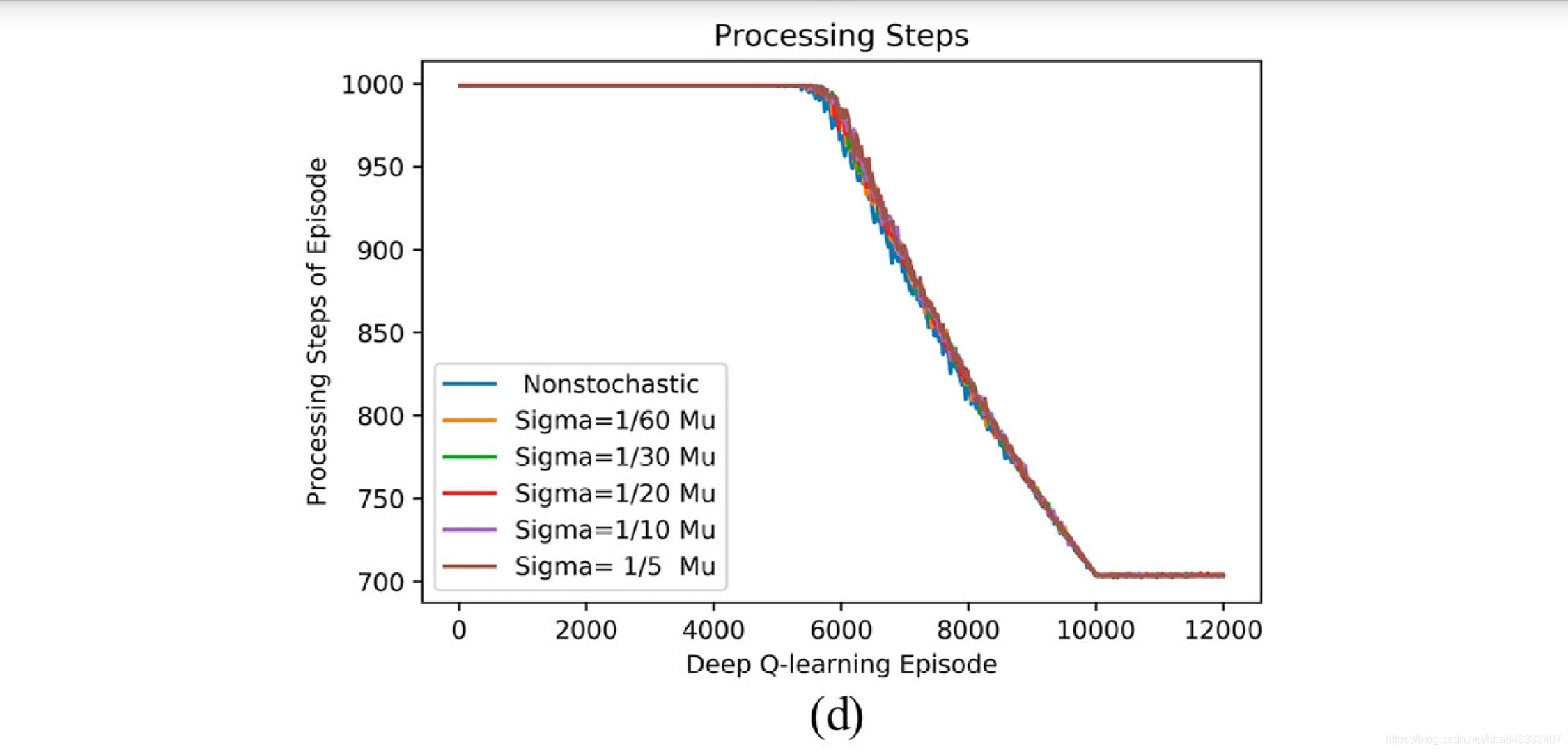
4.2并行生产线:工艺状态
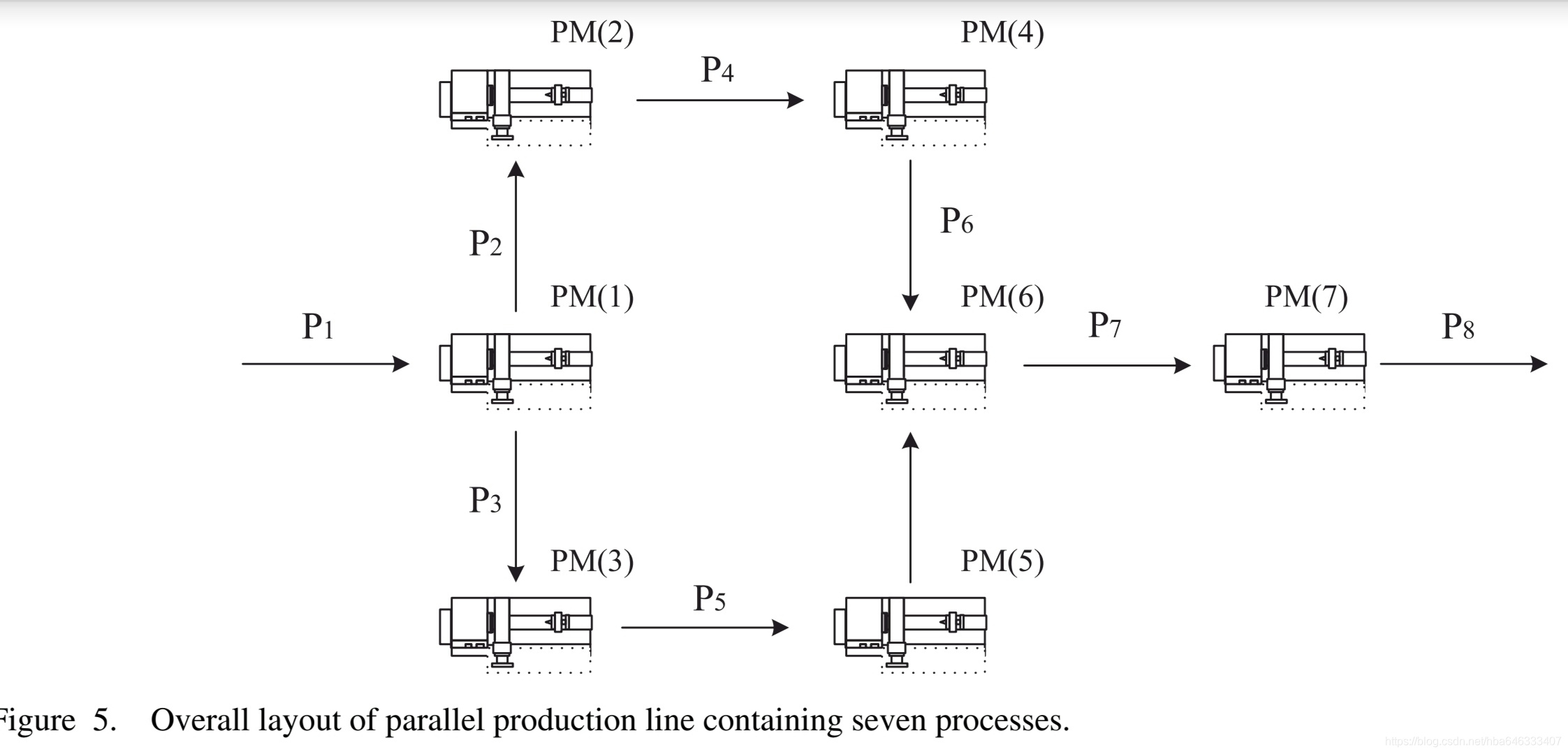
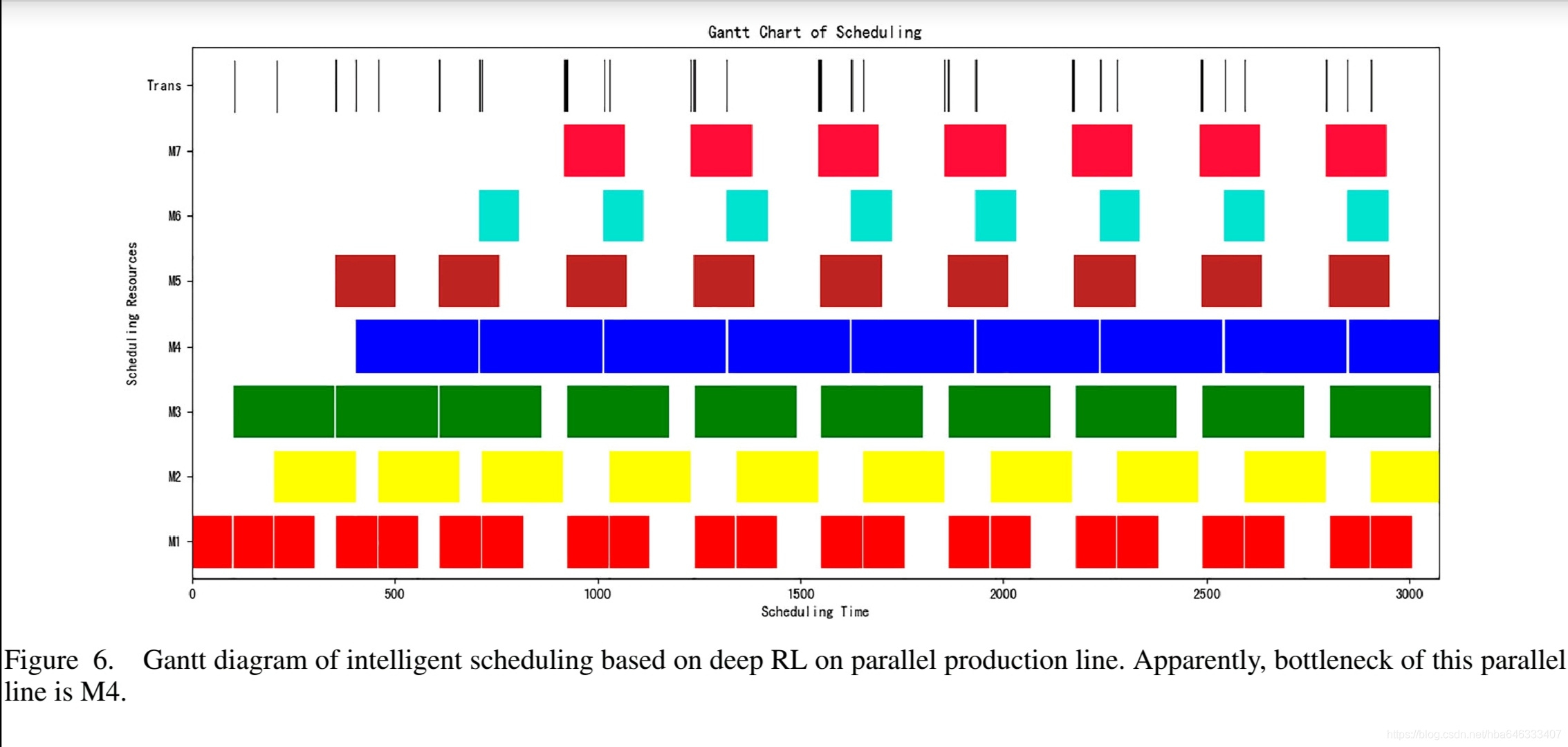
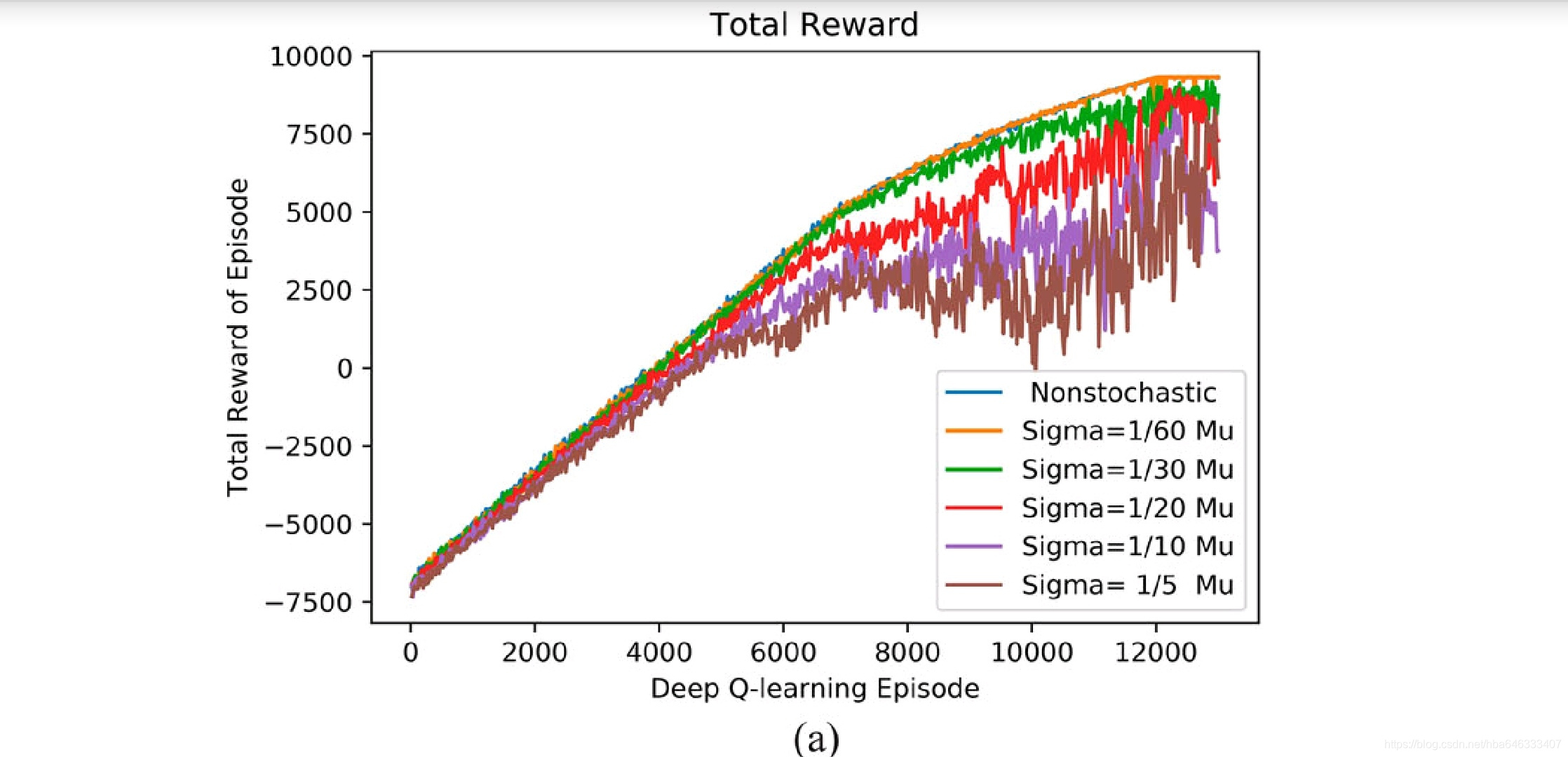
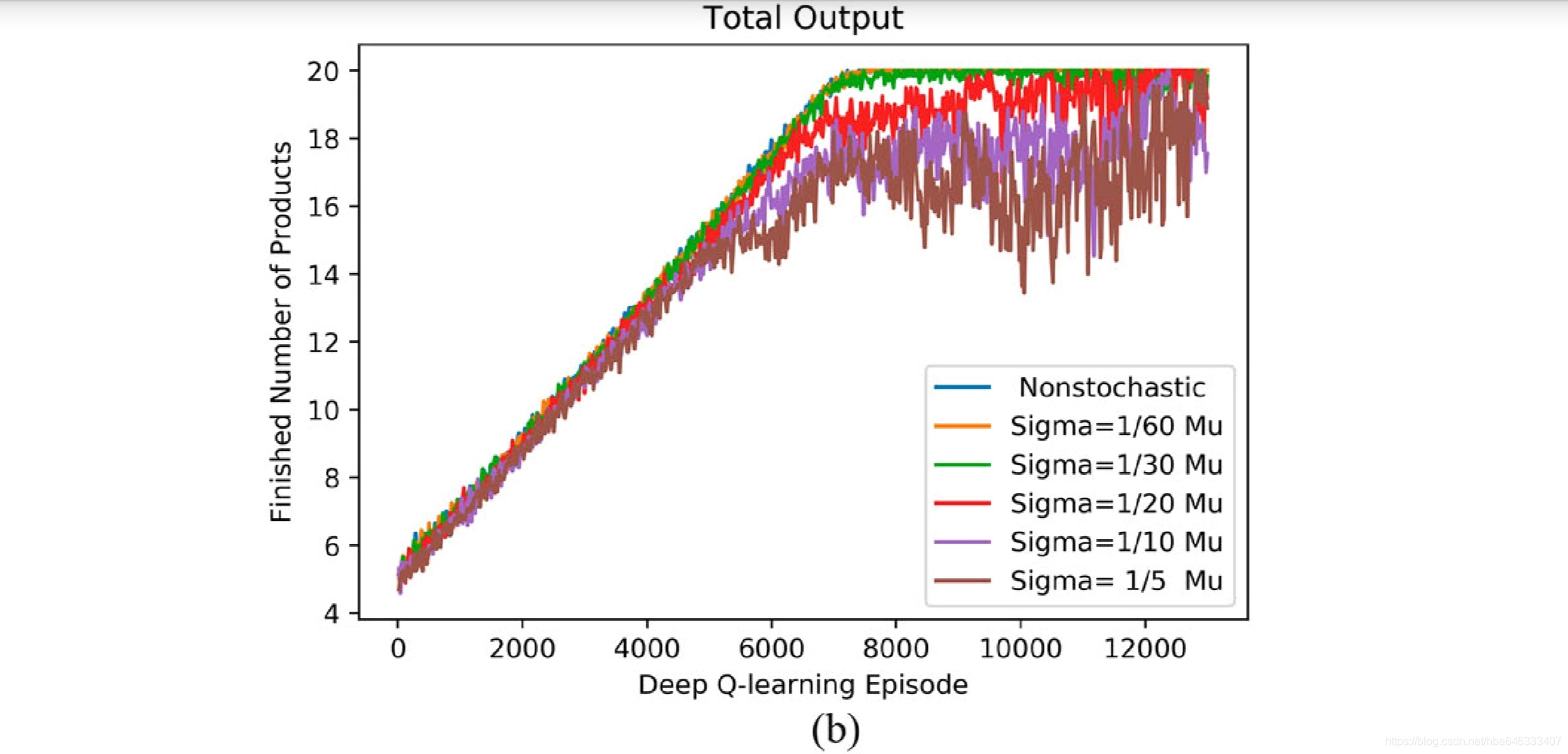
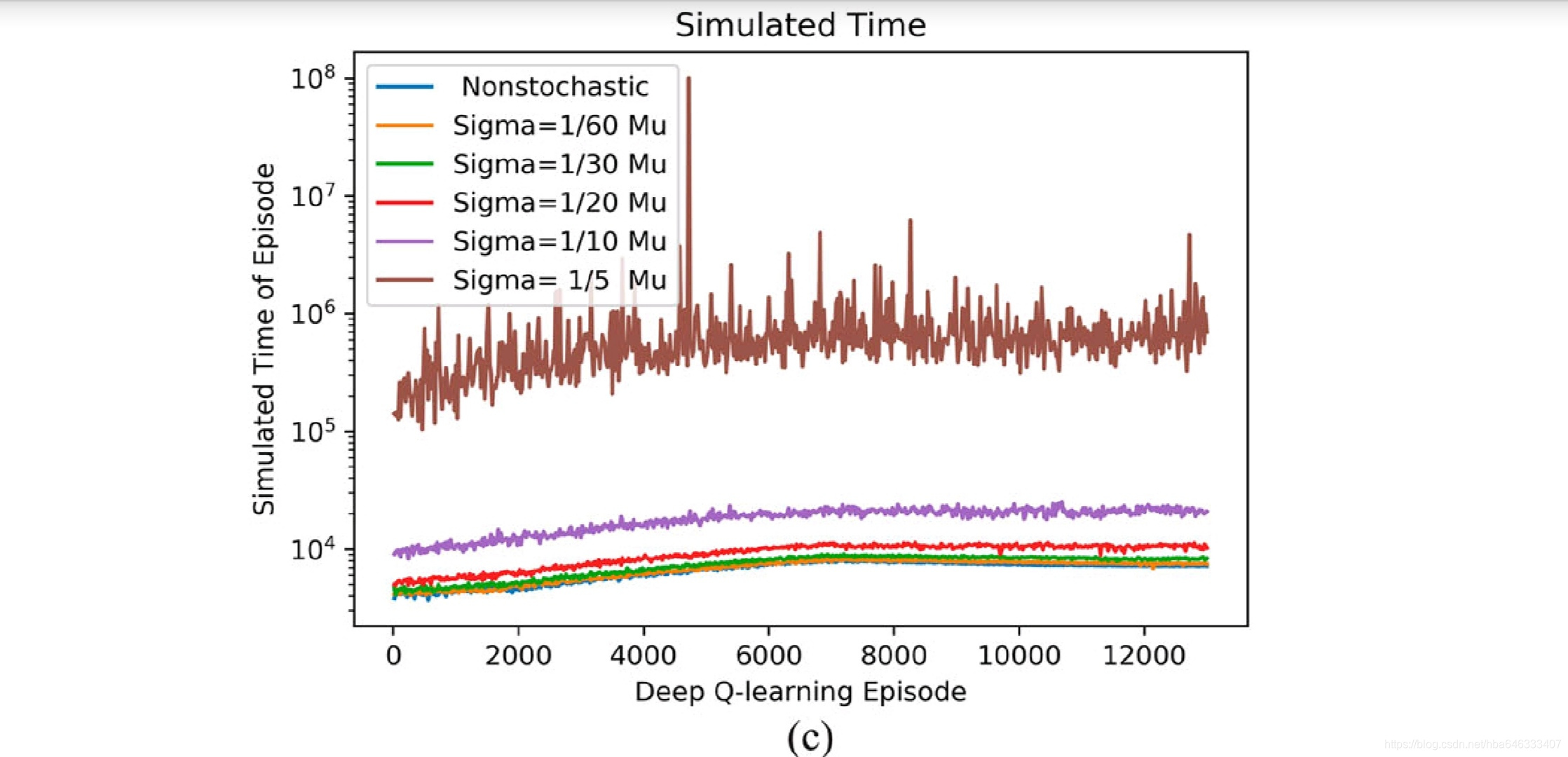
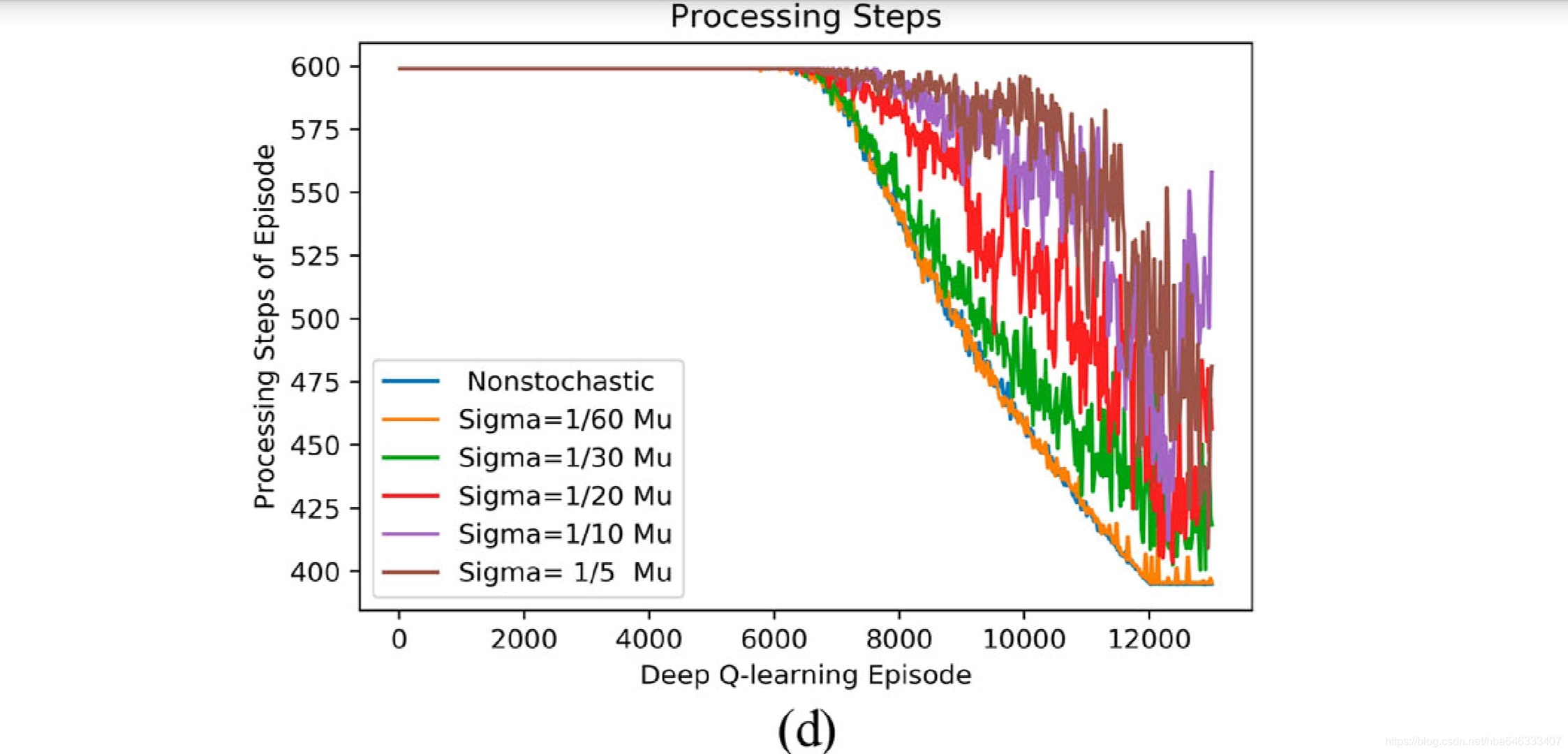
4.3可重入生产线:工艺状态
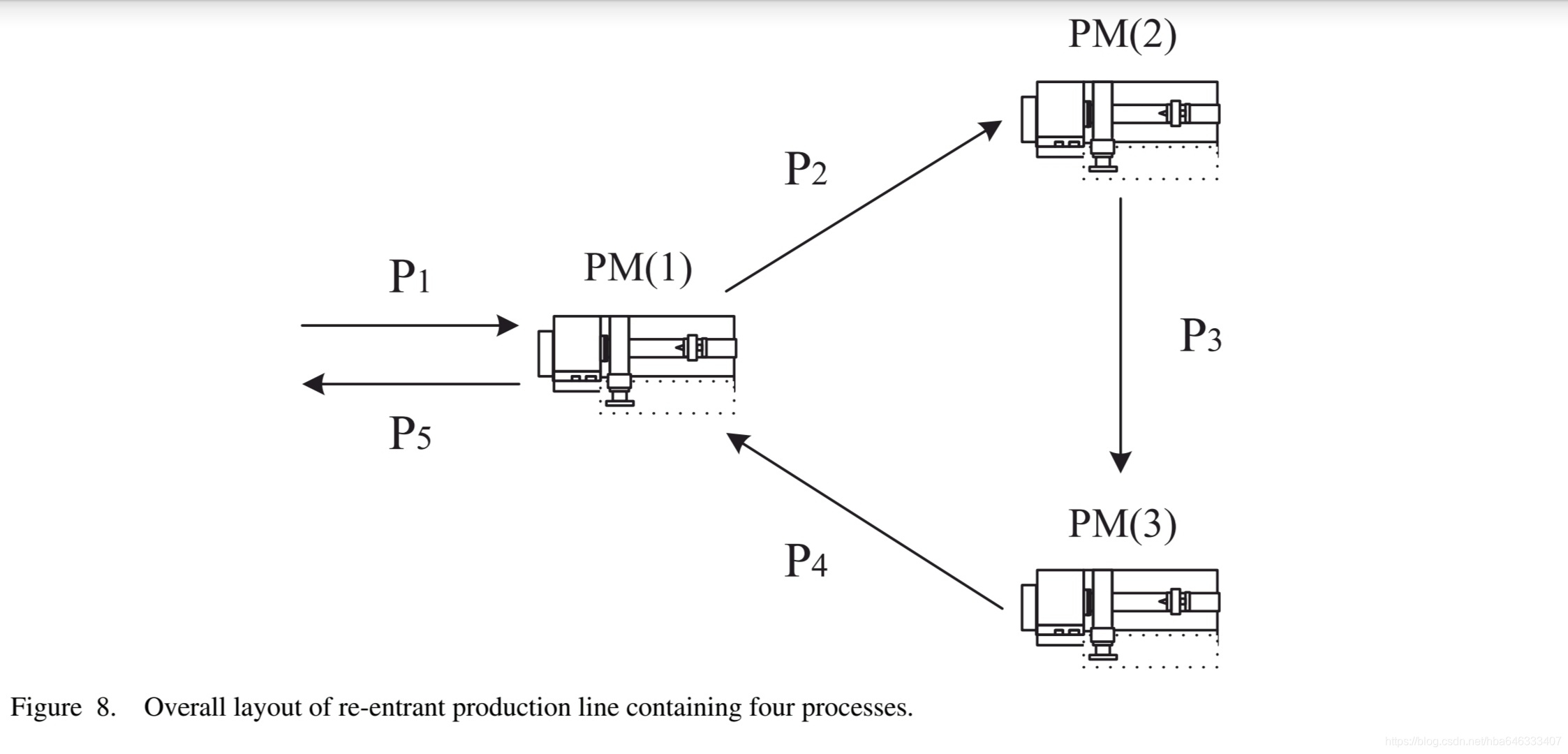
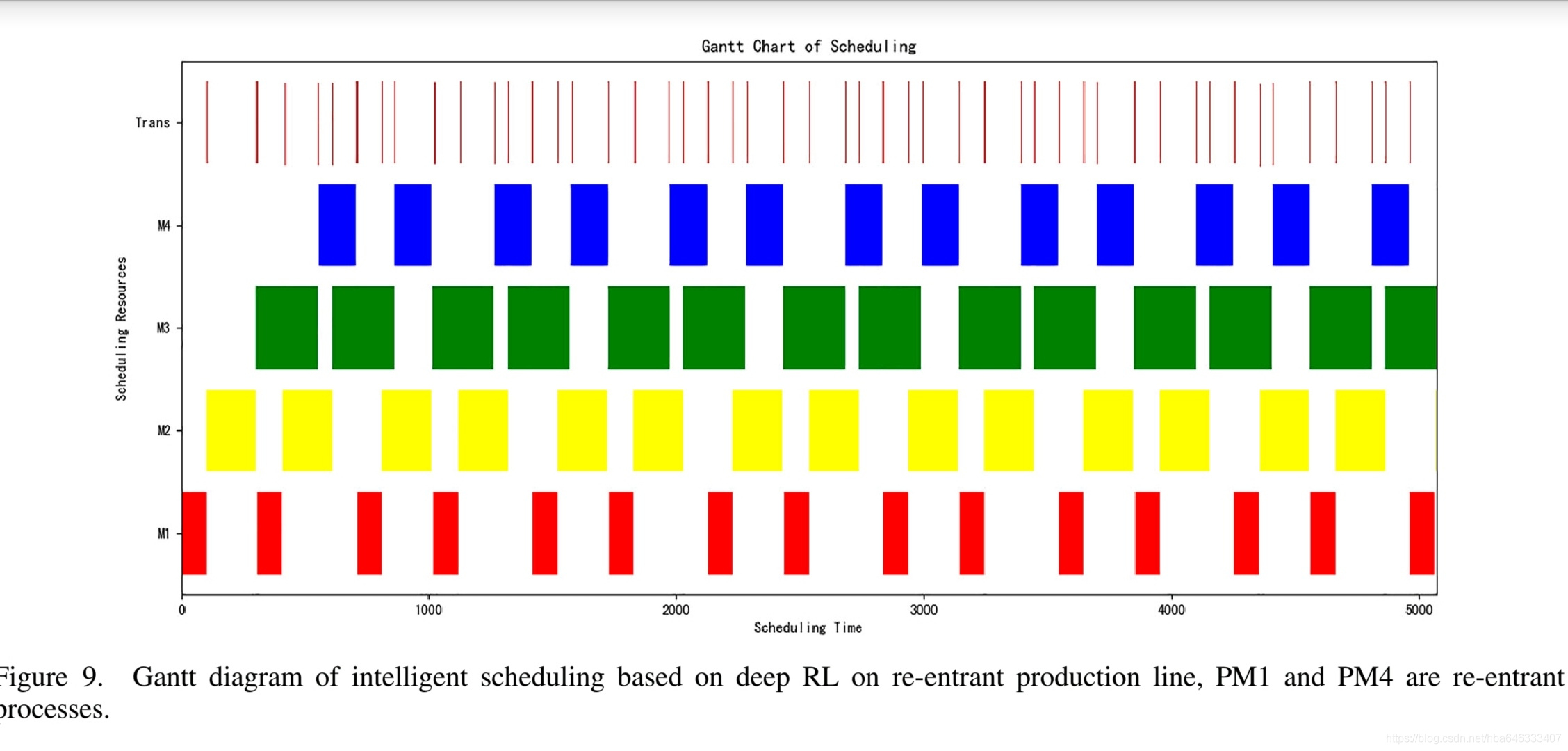
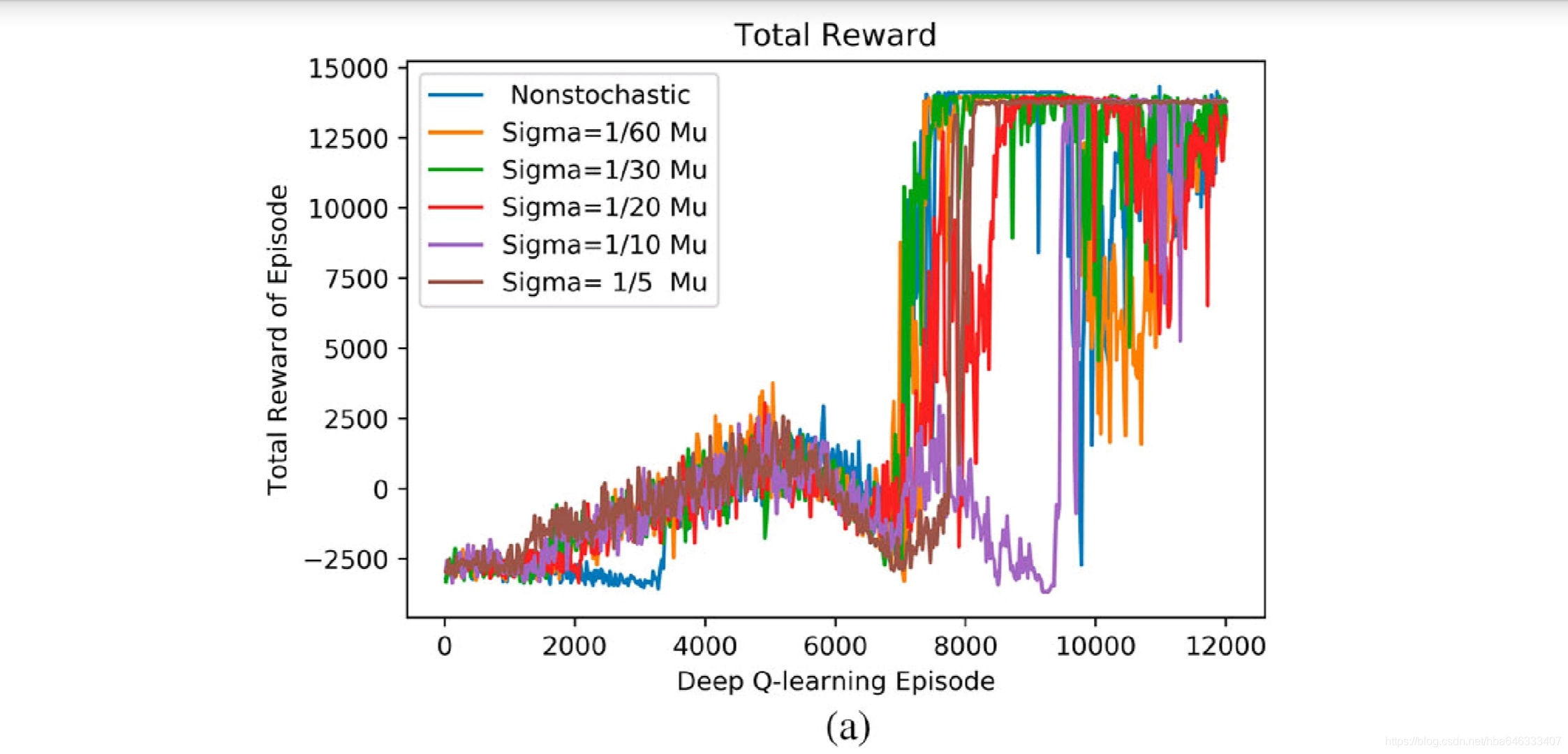
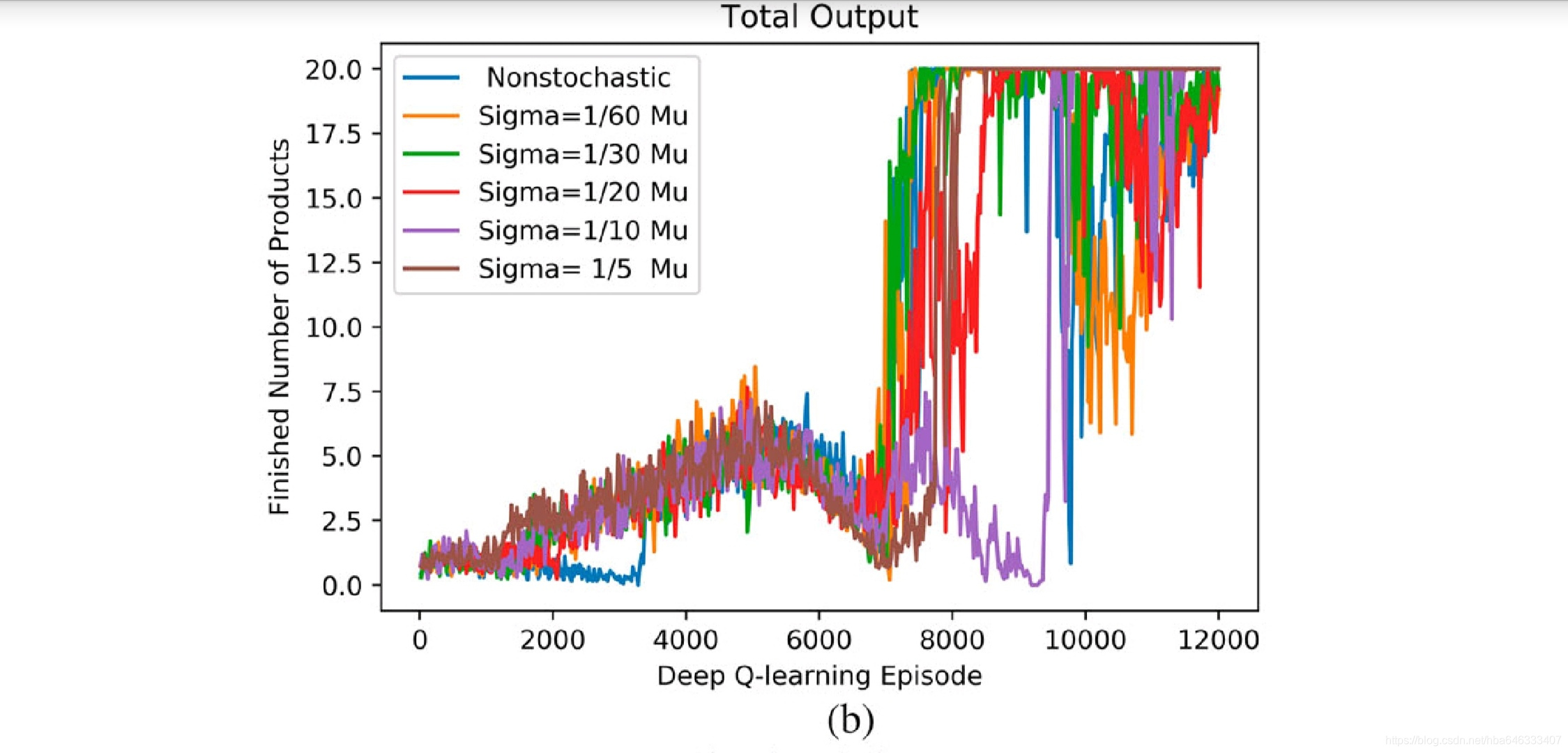
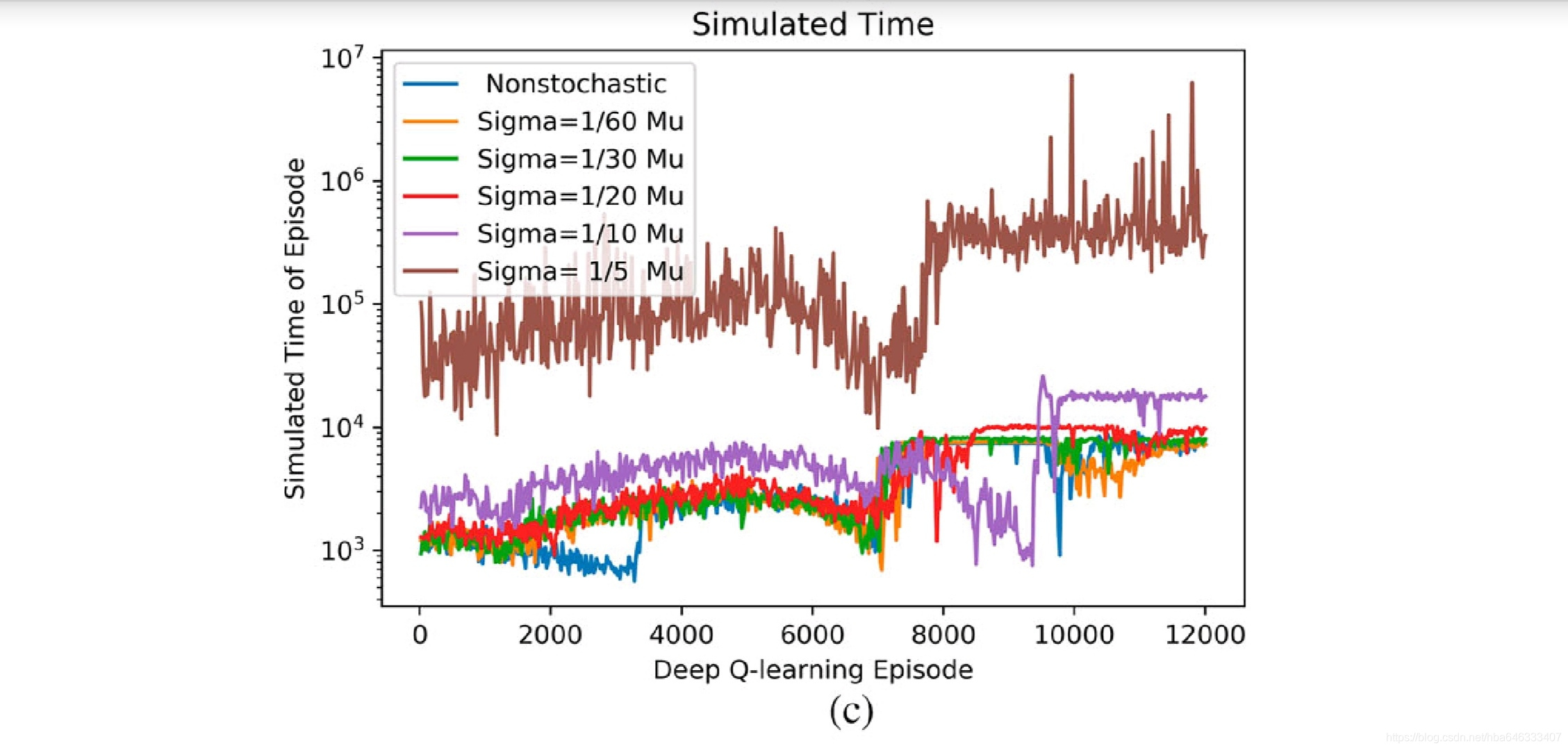
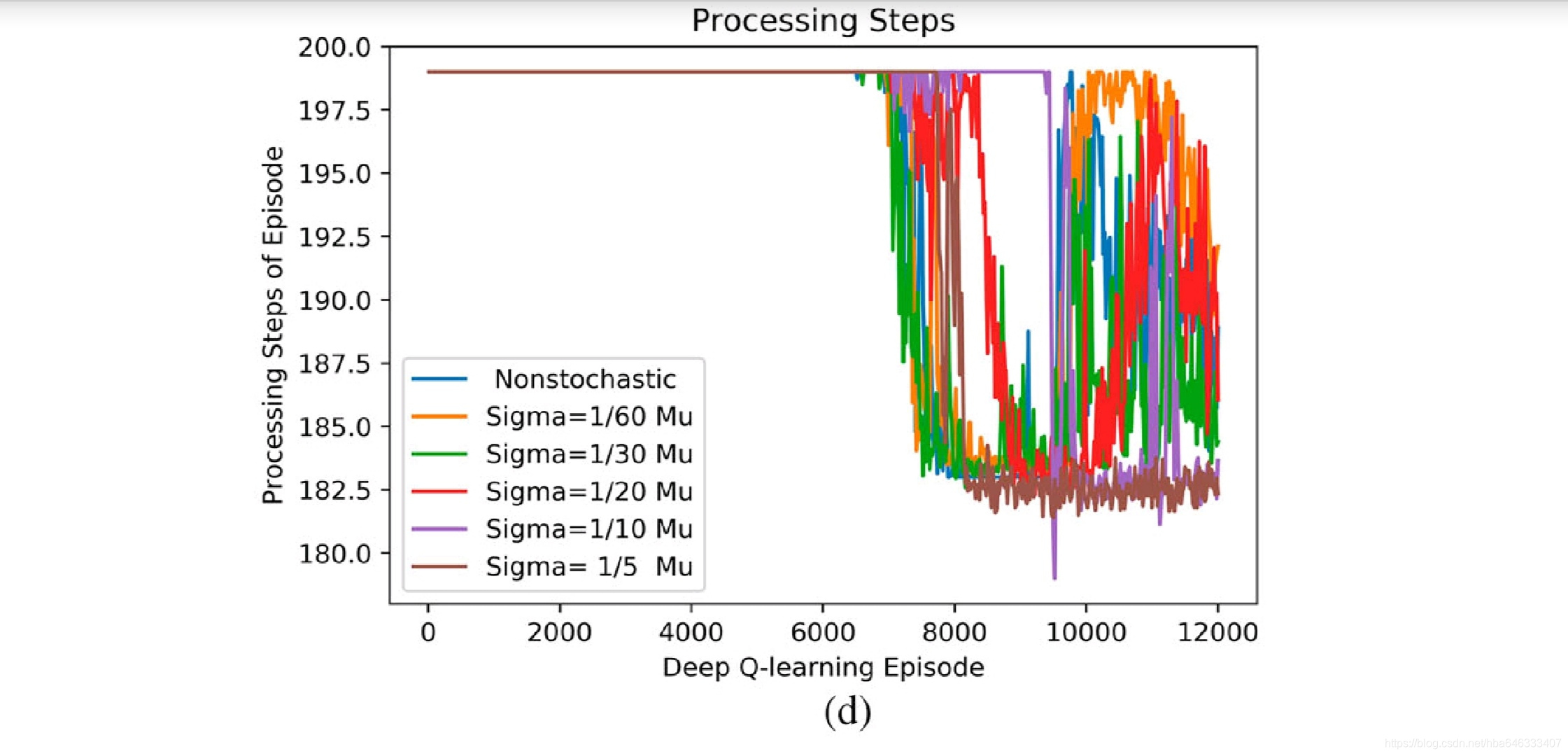
5启发
论文中考虑了加工时间随机的情况,这是可以借鉴的地方,因为强化学习本来就是通过试错的方法,对随机性具有天然的自适应性。
我认为不足的是,深度强化学习最主要的目的是通过已知预测未知,即通用性,文中只是对单个案例进行优化,因为状态表示方法的局限性,也无法测试算法的通用性,个人认为应该使用与领域问题相关的属性来表达状态,才能反映问题的本质特征,也才能针对不用的问题进行自适应调度。
