多次面试都提到了这个问题,这次来系统的总结一下答题的要点吧。
一、HBASE底层设计,也即HBASE的底层架构:
1、HBASE中有多个RegionServer
2、RegionServer是调度者,Region负责存储。
因此HBASE是一个分布式的数据库,使用zookeeper来管理集群。
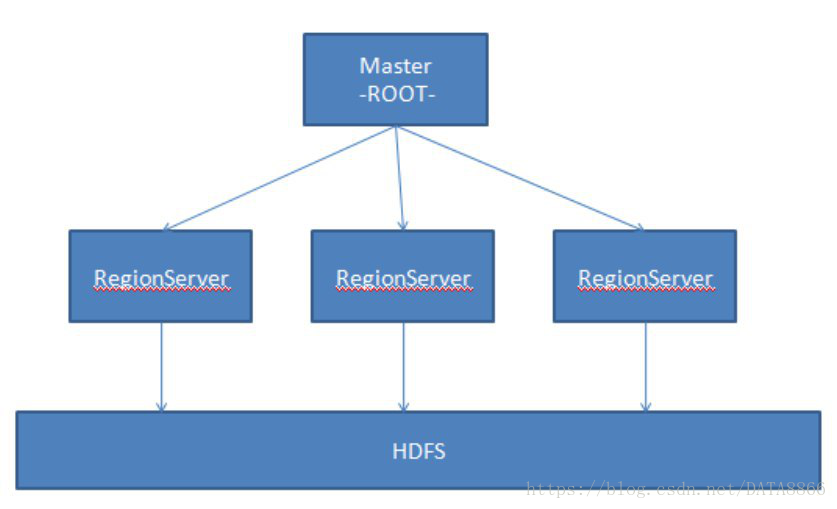
在Hbase中每一个regionserver分别对应于一个集群的节点,每一个regionserver负责管理多个region。其中一个region代表一张HBASE表中的一部分数据,所以HBASE中的一张表可能需要多个region来存储数据,但是region的分布并不是杂乱无章的,HBASE在管理region的时候会给每一个region定义一个rowkey的范围,落在特定范围内的数据将交给特定的region,从而将负载分摊到多个节点上,充分利用分布式的优点。
二、数据存储
数据存储是region的工作。
一个region代表的是一张HBASE表中特定rowkey范围内的数据,而HBASE是面向列存储的数据库,在一个region中,有多个文件来存储这些列。HBASE中数据是由列族来组织的,所以每一个列族都会对应一个数据机构,HBASE将列族的存储数据结构抽象为store,一个store代表一个列族。每一个store里边又有一些storefile来存储数据,最底层是Hfile来存储到hdfs上。
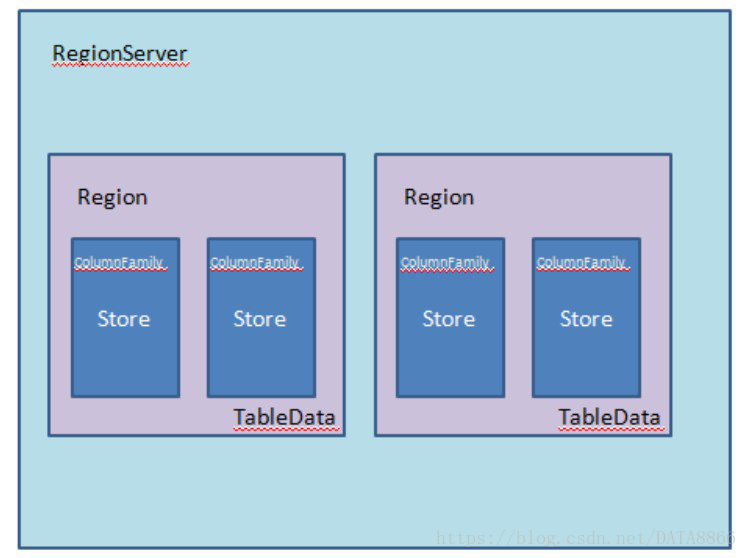

所以,我们查询的时候尽量减少不需要的列,而经常一起查询的列要组织到一个列族里:因为需要查询的列族越多,意味着要扫描的store文件就越多,这就需要越多的时间。
三、访问HBASE数据
client发起访问数据请求,请求将首先交由Zookeper处理,Zookeper接到请求后将查询root表,然后通过root表映射到META表来查询,最后META表映射到regionserver来查询,regionserver查询到相应的region,然后定位到region中特定的rowkey上。
四、HBASE常用shell指令
describe、create、get、put、scan、drop、list、delete、alter