初始化集群
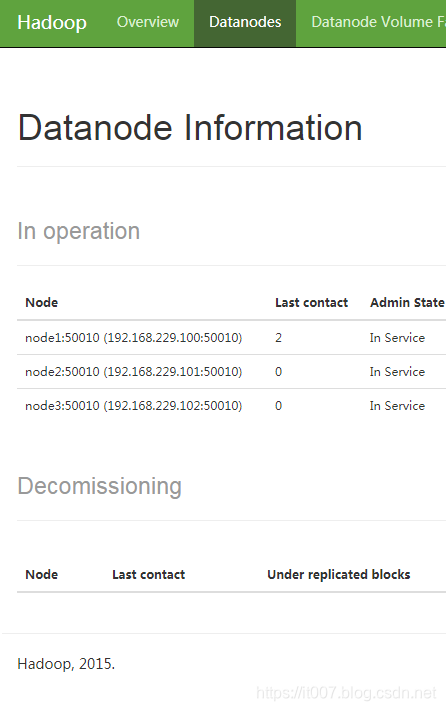
初始化集群:hadoop三个DataNode,HBASE集群只有一个regionserver。
后面我们不停服的情况下,动态添加一个机器node4,在node4上启动DataNode服务。
hadoop动态扩容
准备工作
准备工作与新搭建集群类似,这里参考笔者另一篇博客Hadoop 2.8.5 完全分布式HA高可用安装(一)–环境准备
- 安装java
- 配置hostname
- 确保ssh免密登录可以互通
- 配置hosts
- 关闭防火墙
修改slaves文件
配置每台机器的hadoop-2.7.2/etc/hadoop/slaves文件,添加node4节点
[root@node1 hadoop]# cat slaves
node1
node2
node3
node4
启动DataNode
在新增加的node4集器启动DataNode
[root@node4 sbin]# ./hadoop-daemon.sh start datanode
starting datanode, logging to /data/program/hadoop-2.7.2/logs/hadoop-root-datanode-node4.out
[root@node4 sbin]# jps
1988 Jps
1910 DataNode
启动nodemanager
如果需要yarn服务,则启动nodemanager:
./yarn-daemon.sh start nodemanager
查看结果
访问http://node1:50070 查看DataNode结果,发现多了一个node4
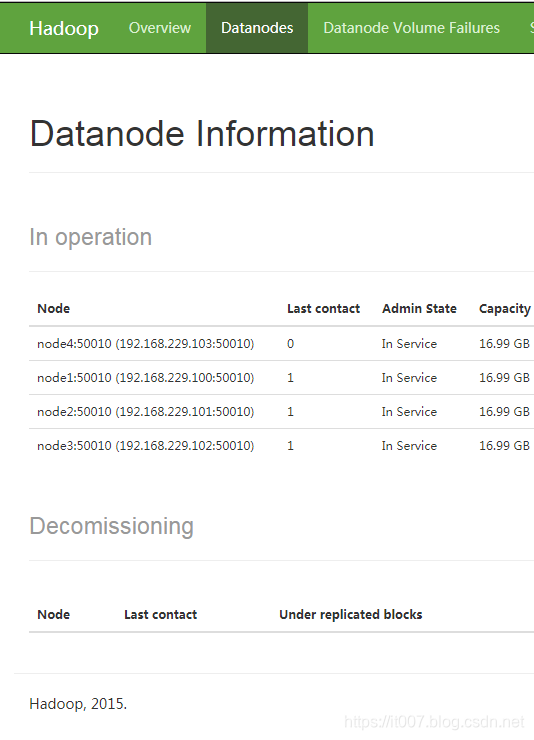
hadoop动态缩容
这里我们把node3的DataNode下线。
配置excludes
在namenode的active节点上配置excludes过滤
[root@node1 hadoop]# cat excludes
node3
修改hdfs-site.xml
在namenode的active节点上添加
<property>
<name>dfs.hosts.exclude</name>
<value>/data/program/hadoop-2.7.2/etc/hadoop/excludes</value>
</property>
修改mapred-site.xml
在namenode的active节点上添加
<property>
<name>mapred.hosts.exclude</name>
<value>/data/program/hadoop-2.7.2/etc/hadoop/excludes</value>
<final>true</final>
</property>
refreshNodes
在namenode的active节点上执行
[root@node1 bin]# ./hadoop dfsadmin -refreshNodes
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Refresh nodes successful for node1/192.168.229.100:9000
Refresh nodes successful for node2/192.168.229.101:9000
查看node3状态
[root@node1 bin]# ./hadoop dfsadmin -report
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Configured Capacity: 54721310720 (50.96 GB)
Present Capacity: 38866949149 (36.20 GB)
DFS Remaining: 38847803773 (36.18 GB)
DFS Used: 19145376 (18.26 MB)
DFS Used%: 0.05%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (4):
Name: 192.168.229.101:50010 (node2)
Hostname: node2
Decommission Status : Normal
Configured Capacity: 18238930944 (16.99 GB)
DFS Used: 4648960 (4.43 MB)
Non DFS Used: 5018213816 (4.67 GB)
DFS Remaining: 13216068168 (12.31 GB)
DFS Used%: 0.03%
DFS Remaining%: 72.46%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 5
Last contact: Mon Nov 04 18:55:55 CST 2019
Name: 192.168.229.103:50010 (node4)
Hostname: node4
Decommission Status : Normal
Configured Capacity: 18238930944 (16.99 GB)
DFS Used: 5374624 (5.13 MB)
Non DFS Used: 4930800408 (4.59 GB)
DFS Remaining: 13302755912 (12.39 GB)
DFS Used%: 0.03%
DFS Remaining%: 72.94%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 5
Last contact: Mon Nov 04 18:55:54 CST 2019
Name: 192.168.229.102:50010 (node3)
Hostname: node3
Decommission Status : Decommissioned
Configured Capacity: 18238930944 (16.99 GB)
DFS Used: 4517888 (4.31 MB)
Non DFS Used: 4846258853 (4.51 GB)
DFS Remaining: 13388154203 (12.47 GB)
DFS Used%: 0.02%
DFS Remaining%: 73.40%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 3
Last contact: Mon Nov 04 18:55:52 CST 2019
Name: 192.168.229.100:50010 (node1)
Hostname: node1
Decommission Status : Normal
Configured Capacity: 18238930944 (16.99 GB)
DFS Used: 4603904 (4.39 MB)
Non DFS Used: 5905347347 (5.50 GB)
DFS Remaining: 12328979693 (11.48 GB)
DFS Used%: 0.03%
DFS Remaining%: 67.60%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 3
Last contact: Mon Nov 04 18:55:52 CST 2019
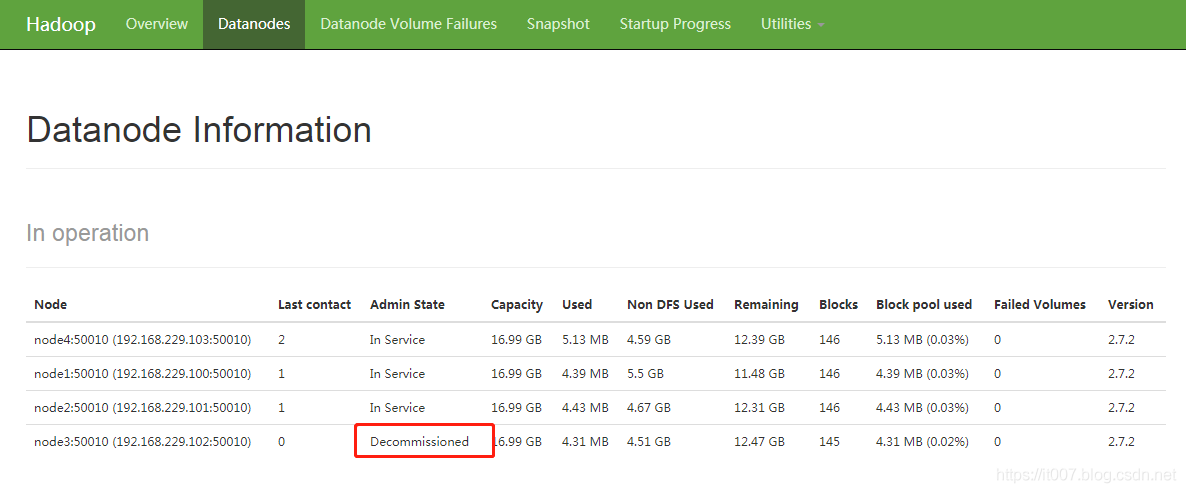
可以看到node3的Decommission Status由Normal变为了Decommissioned(下线过程中是decomissioning状态)
我们也可以在控制台查看状态:
关闭node3的DataNode进程
在node3机器上执行:
[root@node3 sbin]# ./hadoop-daemon.sh stop datanode
stopping datanode
如果有nodemanager, 在node3机器上执行yarn-daemon.sh stop nodemanager停止nodemanager
这一步操作需要等待很久的时间,才能看到node3变为dead状态:
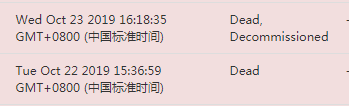
使用hadoop dfsadmin -report也可以看到有dead的节点Dead datanodes (1)
